الباندا: تجاهل أعمدة محددة عند استيراد ملف excel
يمكنك استخدام بناء الجملة الأساسي التالي لتجاهل أعمدة معينة عند استيراد ملف Excel إلى pandas DataFrame:
#define columns to skip skip_cols = [1, 2] #define columns to keep keep_cols = [i for i in range (4) if i not in skip_cols] #import Excel file and skip specific columns df = pd. read_excel (' my_data.xlsx ', usecols=keep_cols)
سيتجاهل هذا المثال تحديدًا الأعمدة الموجودة في موضعي الفهرس 1 و 2 عند استيراد ملف Excel المسمى my_data.xlsx إلى الباندا.
يوضح المثال التالي كيفية استخدام بناء الجملة هذا عمليًا.
مثال: تجاهل أعمدة معينة عند استيراد ملف Excel إلى Pandas
لنفترض أن لدينا ملف Excel التالي المسمى player_data.xlsx :
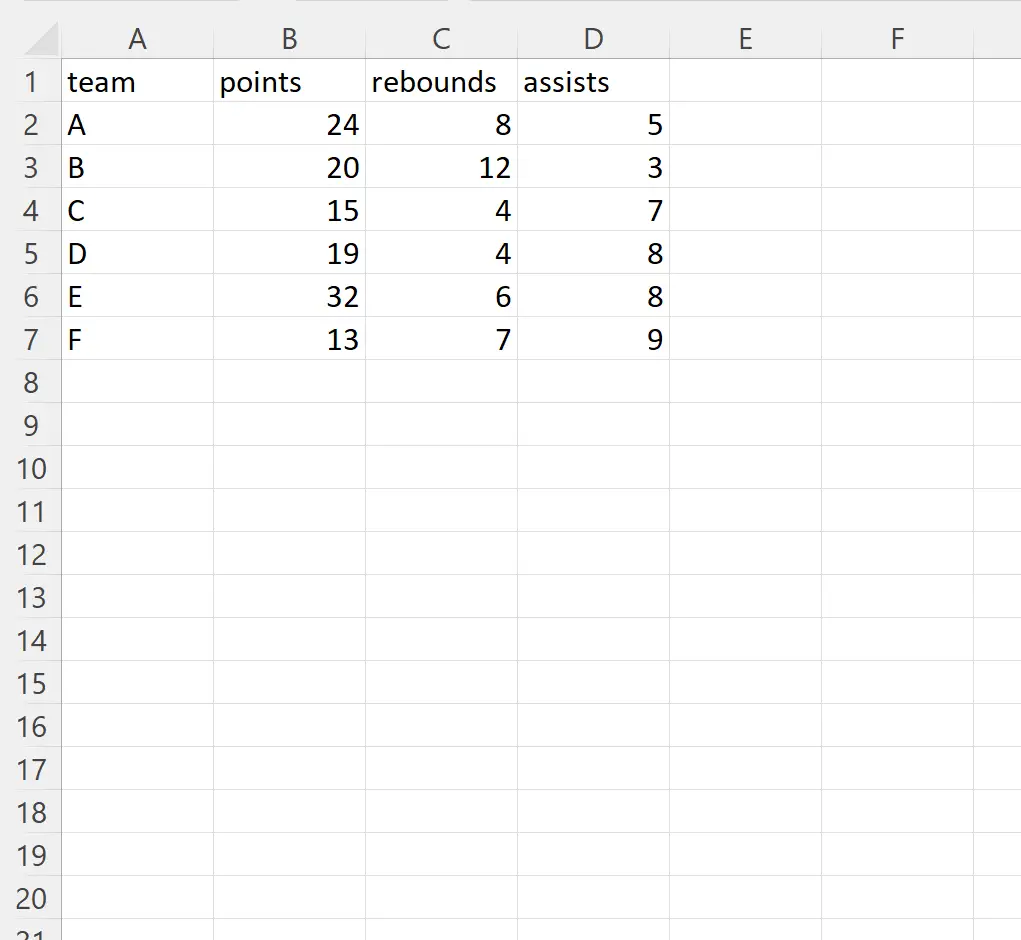
يمكننا استخدام الصيغة التالية لاستيراد هذا الملف إلى pandas DataFrame وتجاهل الأعمدة الموجودة في موضعي الفهرس 1 و 2 (أعمدة النقطة والارتداد) أثناء الاستيراد:
#define columns to skip skip_cols = [1, 2] #define columns to keep keep_cols = [i for i in range (4) if i not in skip_cols] #import Excel file and skip specific columns df = pd. read_excel (' player_data.xlsx ', usecols=keep_cols) #view DataFrame print (df) team assists 0 to 5 1 B 3 2 C 7 3 D 8 4 E 8 5 F 9
لاحظ أنه تم استيراد جميع الأعمدة الموجودة في ملف Excel باستثناء الأعمدة الموجودة في موضعي الفهرس 1 و 2 (أعمدة النقاط والارتدادات) إلى DataFrame الباندا.
لاحظ أن هذه الطريقة تفترض أنك تعرف مسبقًا عدد الأعمدة الموجودة في ملف Excel.
وبما أننا عرفنا أن هناك أربعة أعمدة في الملف، فقد استخدمنا النطاق (4) لتحديد الأعمدة التي أردنا الاحتفاظ بها.
ملاحظة : يمكنك العثور على الوثائق الكاملة لوظيفة Pandas read_excel() هنا .
مصادر إضافية
تشرح البرامج التعليمية التالية كيفية تنفيذ المهام الشائعة الأخرى في الباندا:
الباندا: كيفية تخطي الأسطر عند قراءة ملف Excel
الباندا: كيفية تحديد الأنواع عند استيراد ملف Excel
الباندا: كيفية الجمع بين أوراق إكسل متعددة
About Author
دكتور بنيامين أندرسون
مرحبًا، أنا بنجامين، أستاذ الإحصاء المتقاعد الذي تحول إلى مدرس متخصص في Statorials. بفضل خبرتي الواسعة في مجال الإحصاء، فأنا حريص على مشاركة معرفتي لتمكين الطلاب من خلال Statorials. تعرف أكثر