كيفية إجراء ترميز واحد ساخن في بايثون
يتم استخدام التشفير السريع لتحويل المتغيرات الفئوية إلى تنسيق يمكن استخدامه بسهولة بواسطة خوارزميات التعلم الآلي .
الفكرة الأساسية للتشفير السريع هي إنشاء متغيرات جديدة تأخذ القيمتين 0 و1 لتمثيل القيم الفئوية الأصلية.
على سبيل المثال، توضح الصورة التالية كيف يمكننا التشفير السريع لتحويل متغير فئوي يحتوي على أسماء الفرق إلى متغيرات جديدة تحتوي على قيم 0 و1 فقط:
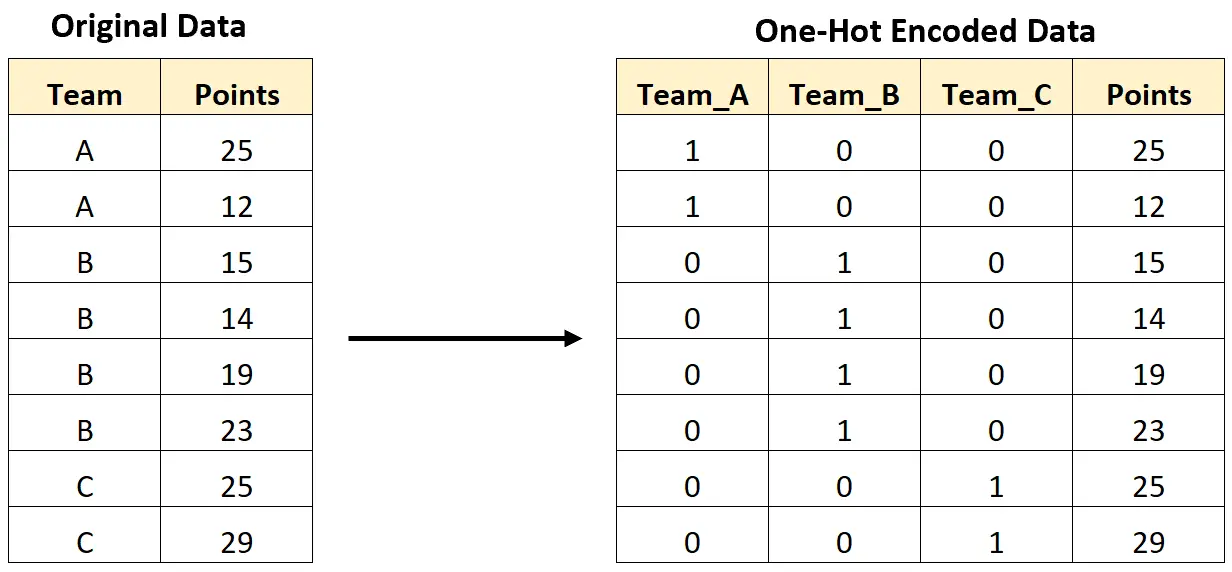
يوضح المثال التالي خطوة بخطوة كيفية إجراء تشفير سريع لمجموعة البيانات المحددة هذه في Python.
الخطوة 1: إنشاء البيانات
أولاً، لنقم بإنشاء إطار بيانات الباندا التالي:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'], ' points ': [25, 12, 15, 14, 19, 23, 25, 29]}) #view DataFrame print (df) team points 0 to 25 1 to 12 2 B 15 3 B 14 4 B 19 5 B 23 6 C 25 7 C 29
الخطوة 2: تنفيذ التشفير السريع
بعد ذلك، لنستورد الدالة OneHotEncoder() من مكتبة sklearn ونستخدمها لإجراء التشفير السريع على متغير “team” في pandas DataFrame:
from sklearn. preprocessing import OneHotEncoder #creating instance of one-hot-encoder encoder = OneHotEncoder(handle_unknown=' ignore ') #perform one-hot encoding on 'team' column encoder_df = pd. DataFrame ( encoder.fit_transform (df[[' team ']]). toarray ()) #merge one-hot encoded columns back with original DataFrame final_df = df. join (encoder_df) #view final df print (final_df) team points 0 1 2 0 to 25 1.0 0.0 0.0 1 to 12 1.0 0.0 0.0 2 B 15 0.0 1.0 0.0 3 B 14 0.0 1.0 0.0 4 B 19 0.0 1.0 0.0 5 B 23 0.0 1.0 0.0 6 C 25 0.0 0.0 1.0 7 C 29 0.0 0.0 1.0
لاحظ أنه تمت إضافة ثلاثة أعمدة جديدة إلى DataFrame نظرًا لأن عمود “الفريق” الأصلي يحتوي على ثلاث قيم فريدة.
ملاحظة : يمكنك العثور على الوثائق الكاملة لوظيفة OneHotEncoder() هنا .
الخطوة 3: إزالة المتغير الفئوي الأصلي
أخيرًا، يمكننا إزالة متغير “team” الأصلي من DataFrame لأننا لم نعد بحاجة إليه:
#drop 'team' column final_df. drop (' team ', axis= 1 , inplace= True ) #view final df print (final_df) points 0 1 2 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
ذات صلة: كيفية حذف الأعمدة في الباندا (4 طرق)
يمكننا أيضًا إعادة تسمية أعمدة DataFrame النهائية لتسهيل قراءتها:
#rename columns final_df. columns = ['points', 'teamA', 'teamB', 'teamC'] #view final df print (final_df) points teamA teamB teamC 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
اكتمل التشفير السريع ويمكننا الآن إدراج DataFrame الباندا هذا في أي خوارزمية للتعلم الآلي نريدها.
مصادر إضافية
كيفية حساب المتوسط المقلص في بايثون
كيفية تنفيذ الانحدار الخطي في بايثون
كيفية تنفيذ الانحدار اللوجستي في بايثون
About Author
دكتور بنيامين أندرسون
مرحبًا، أنا بنجامين، أستاذ الإحصاء المتقاعد الذي تحول إلى مدرس متخصص في Statorials. بفضل خبرتي الواسعة في مجال الإحصاء، فأنا حريص على مشاركة معرفتي لتمكين الطلاب من خلال Statorials. تعرف أكثر