كيفية إنشاء التوزيع الطبيعي في بايثون (مع أمثلة)
يمكنك إنشاء توزيع عادي بسرعة في لغة Python باستخدام الدالة numpy.random.normal() ، والتي تستخدم الصيغة التالية:
numpy. random . normal (loc=0.0, scale=1.0, size=None)
ذهب:
- loc: متوسط التوزيع. القيمة الافتراضية هي 0.
- المقياس: الانحراف المعياري للتوزيع. القيمة الافتراضية هي 1.
- الحجم: حجم العينة.
يعرض هذا البرنامج التعليمي مثالاً لاستخدام هذه الوظيفة لإنشاء توزيع عادي في بايثون.
ذات صلة: كيفية إنشاء منحنى الجرس في بايثون
مثال: إنشاء توزيع عادي في بايثون
يوضح الكود التالي كيفية إنشاء التوزيع الطبيعي في بايثون:
from numpy. random import seed
from numpy. random import normal
#make this example reproducible
seed(1)
#generate sample of 200 values that follow a normal distribution
data = normal (loc=0, scale=1, size=200)
#view first six values
data[0:5]
array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
يمكننا العثور بسرعة على المتوسط والانحراف المعياري لهذا التوزيع:
import numpy as np
#find mean of sample
n.p. mean (data)
0.1066888148479486
#find standard deviation of sample
n.p. std (data, ddof= 1 )
0.9123296653173484
يمكننا أيضًا إنشاء رسم بياني سريع لتصور توزيع قيم البيانات:
import matplotlib. pyplot as plt
count, bins, ignored = plt. hist (data, 30)
plt. show ()
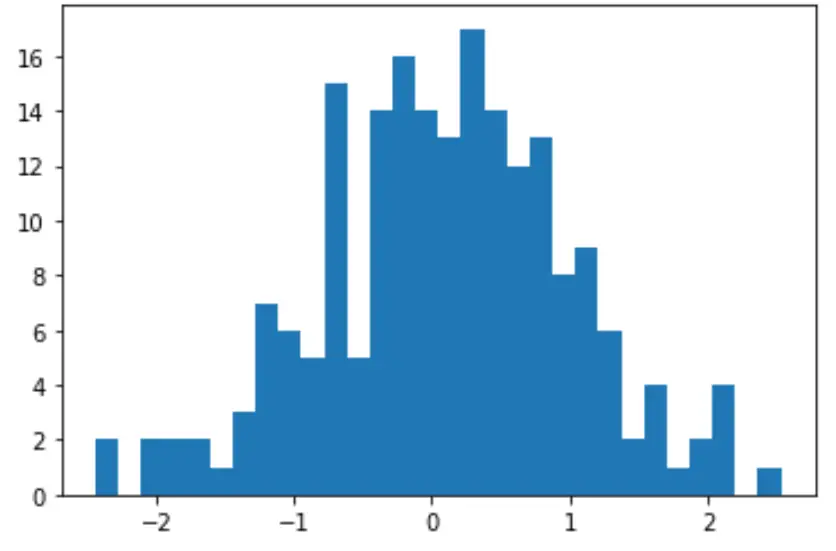
يمكننا أيضًا إجراء اختبار شابيرو ويلك لمعرفة ما إذا كانت مجموعة البيانات تأتي من مجموعة سكانية عادية:
from scipy. stats import shapiro
#perform Shapiro-Wilk test
shapiro(data)
ShapiroResult(statistic=0.9958659410, pvalue=0.8669294714)
وتبين أن القيمة p للاختبار هي 0.8669 . وبما أن هذه القيمة لا تقل عن 0.05، يمكننا أن نفترض أن بيانات العينة تأتي من مجتمع موزع بشكل طبيعي.
لا ينبغي أن تكون هذه النتيجة مفاجئة لأننا أنشأنا البيانات باستخدام الدالة numpy.random.normal() ، التي تولد عينة عشوائية من البيانات من التوزيع الطبيعي.
About Author
دكتور بنيامين أندرسون
مرحبًا، أنا بنجامين، أستاذ الإحصاء المتقاعد الذي تحول إلى مدرس متخصص في Statorials. بفضل خبرتي الواسعة في مجال الإحصاء، فأنا حريص على مشاركة معرفتي لتمكين الطلاب من خلال Statorials. تعرف أكثر