انحدار ريدج في r (خطوة بخطوة)
يعد انحدار ريدج طريقة يمكننا استخدامها لتناسب نموذج الانحدار عند وجود علاقة خطية متعددة في البيانات.
باختصار، يحاول انحدار المربعات الصغرى العثور على تقديرات للمعامل تقلل من مجموع المربعات المتبقية (RSS):
RSS = Σ(ص ط – ŷ ط )2
ذهب:
- Σ : رمز يوناني معناه المجموع
- y i : قيمة الاستجابة الفعلية للملاحظة رقم i
- ŷ i : قيمة الاستجابة المتوقعة بناءً على نموذج الانحدار الخطي المتعدد
على العكس من ذلك، يسعى انحدار ريدج إلى تقليل ما يلي:
آر إس إس + Σβ ي 2
حيث تنتقل j من 1 إلى متغيرات التوقع p و ≥ ≥ 0.
يُعرف هذا الحد الثاني في المعادلة بعقوبة الانسحاب . في انحدار التلال، نختار قيمة π التي تنتج أقل اختبار MSE ممكن (متوسط مربع الخطأ).
يوفر هذا البرنامج التعليمي مثالاً خطوة بخطوة لكيفية إجراء انحدار التلال في R.
الخطوة 1: تحميل البيانات
في هذا المثال، سوف نستخدم مجموعة بيانات R المضمنة والتي تسمى mtcars . سوف نستخدم hp كمتغير الاستجابة والمتغيرات التالية كتنبؤات:
- ميلا في الغالون
- وزن
- القرف
- com.qsec
لإجراء انحدار التلال، سوف نستخدم وظائف من حزمة glmnet . تتطلب هذه الحزمة أن يكون متغير الاستجابة متجهًا وأن تكون مجموعة متغيرات التوقع من فئة data.matrix .
يوضح الكود التالي كيفية تحديد بياناتنا:
#define response variable
y <- mtcars$hp
#define matrix of predictor variables
x <- data.matrix(mtcars[, c('mpg', 'wt', 'drat', 'qsec')])
الخطوة 2: تناسب نموذج انحدار ريدج
بعد ذلك، سوف نستخدم الدالة glmnet() لملاءمة نموذج انحدار Ridge وتحديد alpha=0 .
لاحظ أن تعيين ألفا يساوي 1 يعادل استخدام انحدار Lasso وتعيين ألفا إلى قيمة بين 0 و1 يعادل استخدام شبكة مرنة.
لاحظ أيضًا أن انحدار التلال يتطلب توحيد البيانات بحيث يكون لكل متغير متنبئ متوسط 0 وانحراف معياري 1.
لحسن الحظ، يقوم glmnet() تلقائيًا بهذا التوحيد نيابةً عنك. إذا قمت بالفعل بتوحيد المتغيرات، فيمكنك تحديد Standardize=False .
library (glmnet)
#fit ridge regression model
model <- glmnet(x, y, alpha = 0 )
#view summary of model
summary(model)
Length Class Mode
a0 100 -none- numeric
beta 400 dgCMatrix S4
df 100 -none- numeric
dim 2 -none- numeric
lambda 100 -none- numeric
dev.ratio 100 -none- numeric
nulldev 1 -none- numeric
npasses 1 -none- numeric
jerr 1 -none- numeric
offset 1 -none- logical
call 4 -none- call
nobs 1 -none- numeric
الخطوة 3: اختر القيمة المثلى لـ Lambda
بعد ذلك، سوف نحدد قيمة لامدا التي تنتج أقل خطأ متوسط مربع للاختبار (MSE) باستخدام التحقق المتبادل k-fold .
لحسن الحظ، يحتوي glmnet على وظيفة cv.glmnet() التي تقوم تلقائيًا بإجراء التحقق من صحة k-fold باستخدام k = 10 مرات.
#perform k-fold cross-validation to find optimal lambda value
cv_model <- cv. glmnet (x, y, alpha = 0 )
#find optimal lambda value that minimizes test MSE
best_lambda <- cv_model$ lambda . min
best_lambda
[1] 10.04567
#produce plot of test MSE by lambda value
plot(cv_model)
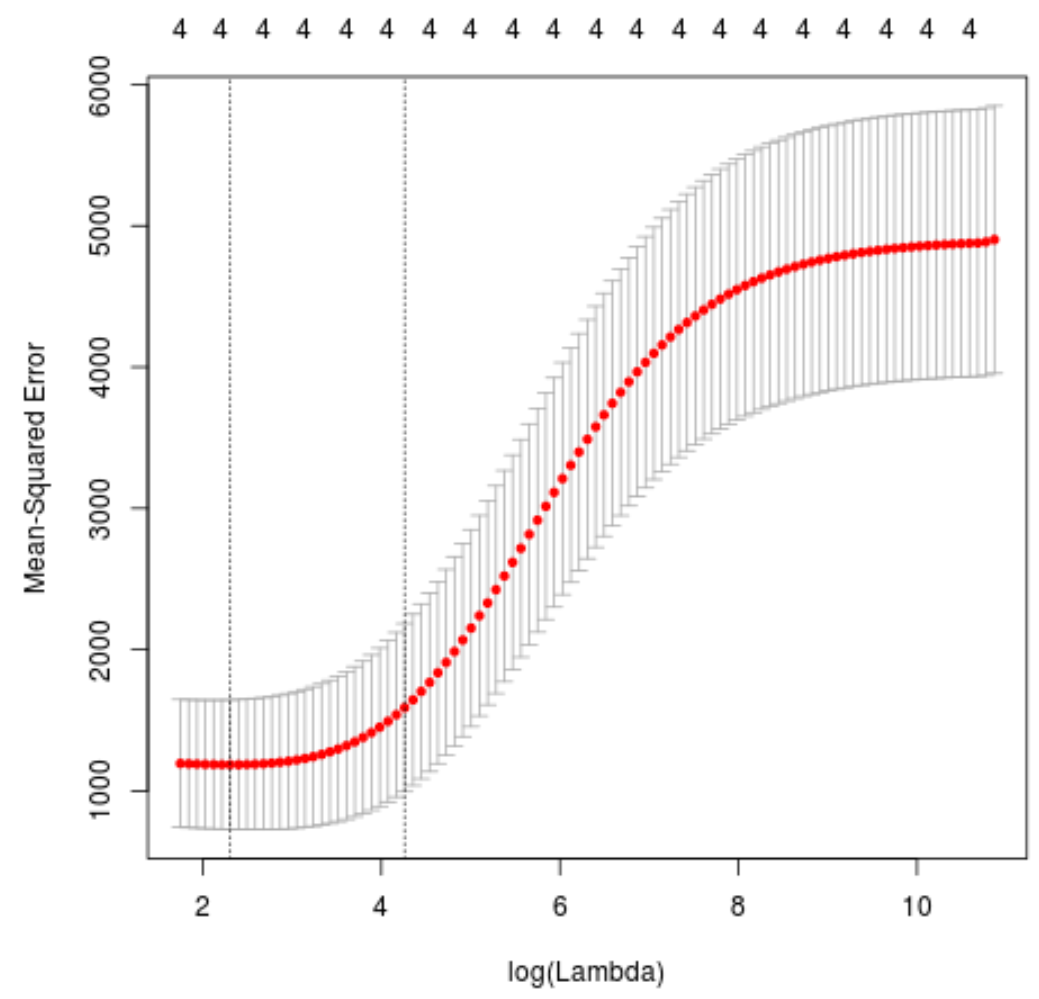
تبين أن قيمة لامدا التي تقلل من اختبار MSE هي 10.04567 .
الخطوة 4: تحليل النموذج النهائي
وأخيرا، يمكننا تحليل النموذج النهائي الناتج عن قيمة لامدا المثلى.
يمكننا استخدام الكود التالي للحصول على تقديرات المعامل لهذا النموذج:
#find coefficients of best model
best_model <- glmnet(x, y, alpha = 0 , lambda = best_lambda)
coef(best_model)
5 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) 475.242646
mpg -3.299732
wt 19.431238
drat -1.222429
qsec -17.949721
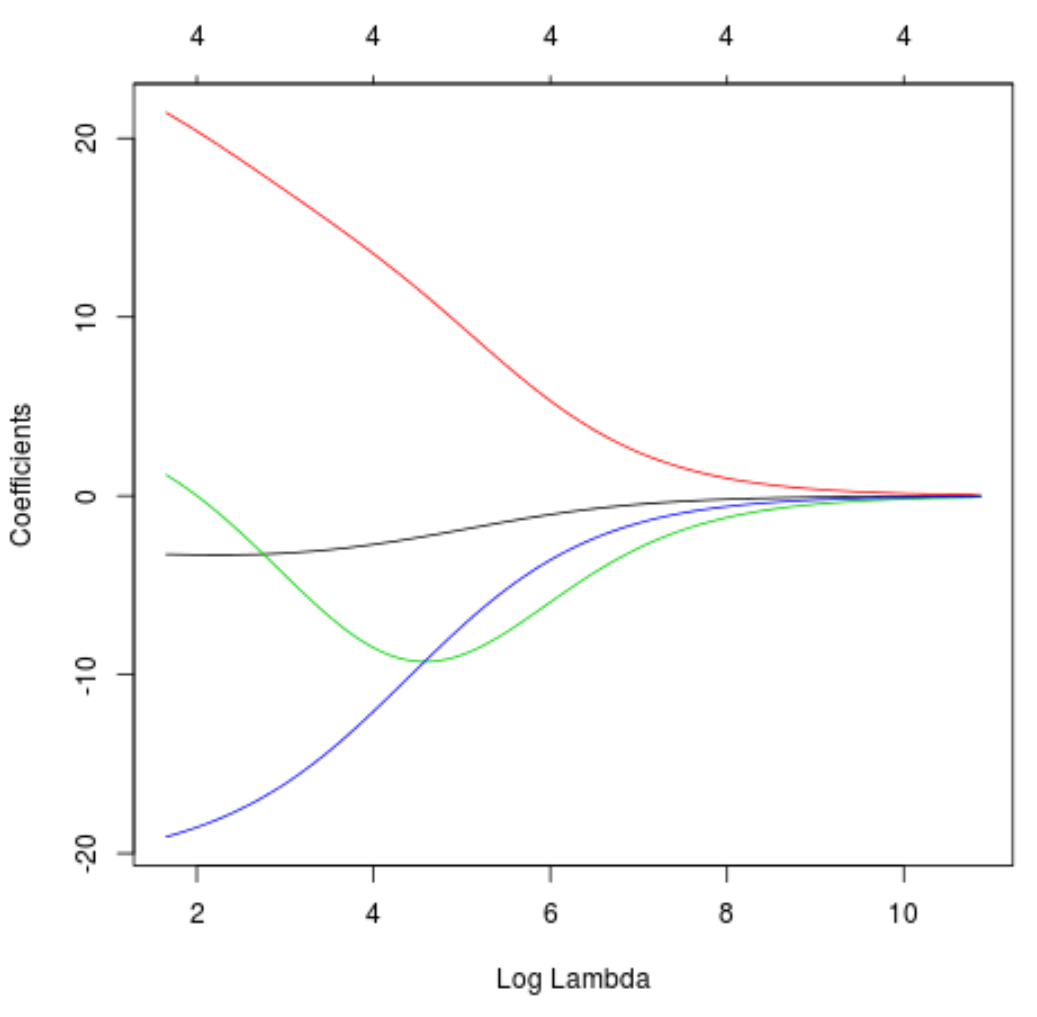
يمكننا أيضًا إنتاج مخطط تتبع لتصور كيفية تغير تقديرات المعامل بسبب الزيادة في لامدا:
#produce Ridge trace plot
plot(model, xvar = " lambda ")
وأخيرًا، يمكننا حساب مربع R للنموذج على بيانات التدريب:
#use fitted best model to make predictions
y_predicted <- predict (model, s = best_lambda, newx = x)
#find OHS and SSE
sst <- sum ((y - mean (y))^2)
sse <- sum ((y_predicted - y)^2)
#find R-Squared
rsq <- 1 - sse/sst
rsq
[1] 0.7999513
تبين أن مربع R يساوي 0.7999513 . أي أن النموذج الأفضل استطاع تفسير 79.99% من التباين في قيم الاستجابة لبيانات التدريب.
يمكنك العثور على رمز R الكامل المستخدم في هذا المثال هنا .
About Author
دكتور بنيامين أندرسون
مرحبًا، أنا بنجامين، أستاذ الإحصاء المتقاعد الذي تحول إلى مدرس متخصص في Statorials. بفضل خبرتي الواسعة في مجال الإحصاء، فأنا حريص على مشاركة معرفتي لتمكين الطلاب من خلال Statorials. تعرف أكثر