K-medoids في r: مثال خطوة بخطوة
التجميع هو أسلوب للتعلم الآلي يحاول العثور على مجموعات أو مجموعات من الملاحظات ضمن مجموعة بيانات.
الهدف هو العثور على مجموعات بحيث تكون الملاحظات داخل كل مجموعة متشابهة تمامًا مع بعضها البعض، في حين أن الملاحظات في مجموعات مختلفة تختلف تمامًا عن بعضها البعض.
التجميع هو شكل من أشكال التعلم غير الخاضع للرقابة لأننا نحاول ببساطة العثور على بنية ضمن مجموعة بيانات بدلاً من التنبؤ بقيمة متغير الاستجابة .
غالبًا ما يتم استخدام التجميع في التسويق عندما تتمكن الشركات من الوصول إلى معلومات مثل:
- دخل الأسرة
- حجم الأسرة
- مهنة رب الأسرة
- المسافة إلى أقرب منطقة حضرية
عندما تتوفر هذه المعلومات، يمكن استخدام التجميع لتحديد الأسر المتشابهة والتي قد تكون أكثر عرضة لشراء منتجات معينة أو الاستجابة بشكل أفضل لنوع معين من الإعلانات.
يُعرف أحد أكثر أشكال التجميع شيوعًا باسم التجميع بالوسائل k .
لسوء الحظ، يمكن أن تتأثر هذه الطريقة بالقيم المتطرفة، وهذا هو السبب في أن البديل المستخدم غالبًا هو تجميع k-medoids .
ما هو تجميع K-Medoids؟
تجميع K-medoids هو أسلوب نضع فيه كل ملاحظة في مجموعة بيانات في إحدى مجموعات K.
الهدف النهائي هو الحصول على مجموعات K تكون فيها الملاحظات داخل كل مجموعة متشابهة تمامًا مع بعضها البعض بينما تختلف الملاحظات في المجموعات المختلفة تمامًا عن بعضها البعض.
من الناحية العملية، نستخدم الخطوات التالية لتنفيذ تجميع الوسائل K:
1. اختر قيمة لـ K.
- أولاً، نحتاج إلى تحديد عدد المجموعات التي نريد تحديدها في البيانات. غالبًا ما نحتاج ببساطة إلى اختبار عدة قيم مختلفة لـ K وتحليل النتائج لمعرفة عدد المجموعات التي يبدو أنها الأكثر منطقية لمشكلة معينة.
2. قم بتخصيص كل ملاحظة بشكل عشوائي لمجموعة أولية، من 1 إلى K.
3. قم بتنفيذ الإجراء التالي حتى تتوقف تعيينات المجموعة عن التغيير.
- لكل مجموعة من مجموعات K ، احسب مركز ثقل الكتلة. هذا هو متجه المتوسطات p للميزات الخاصة بملاحظات المجموعة k .
- تعيين كل ملاحظة إلى الكتلة مع أقرب النقطه الوسطى. هنا، يتم تعريف الأقرب باستخدام المسافة الإقليدية .
ملاحظة تقنية:
نظرًا لأن k-medoids تحسب النقط الوسطى العنقودية باستخدام المتوسطات بدلاً من الوسائل، فإنها تميل إلى أن تكون أكثر قوة بالنسبة للقيم المتطرفة من الوسائل k.
من الناحية العملية، إذا لم تكن هناك قيم متطرفة في مجموعة البيانات، فإن k-means وk-medoids ستنتج نتائج مماثلة.
مجموعات K-Medoids في R
يوفر البرنامج التعليمي التالي مثالاً خطوة بخطوة حول كيفية تنفيذ مجموعات k-medoids في R.
الخطوة 1: تحميل الحزم اللازمة
أولاً، سنقوم بتحميل حزمتين تحتويان على العديد من الوظائف المفيدة لتجميع k-medoids في R.
library (factoextra) library (cluster)
الخطوة 2: تحميل البيانات وإعدادها
في هذا المثال، سنستخدم مجموعة بيانات USArrests المضمنة في R، والتي تحتوي على عدد الاعتقالات لكل 100000 شخص في كل ولاية أمريكية في عام 1973 بتهمة القتل والاعتداء والاغتصاب ، بالإضافة إلى النسبة المئوية لسكان كل ولاية الذين يعيشون في المناطق الحضرية المناطق. أوربان بوب .
يوضح الكود التالي كيفية القيام بما يلي:
- قم بتحميل مجموعة بيانات USArrests
- قم بإزالة كافة الصفوف ذات القيم المفقودة
- قم بقياس كل متغير في مجموعة البيانات للحصول على متوسط 0 وانحراف معياري 1
#load data df <-USArrests #remove rows with missing values df <- na. omitted (df) #scale each variable to have a mean of 0 and sd of 1 df <- scale(df) #view first six rows of dataset head(df) Murder Assault UrbanPop Rape Alabama 1.24256408 0.7828393 -0.5209066 -0.003416473 Alaska 0.50786248 1.1068225 -1.2117642 2.484202941 Arizona 0.07163341 1.4788032 0.9989801 1.042878388 Arkansas 0.23234938 0.2308680 -1.0735927 -0.184916602 California 0.27826823 1.2628144 1.7589234 2.067820292 Colorado 0.02571456 0.3988593 0.8608085 1.864967207
الخطوة 3: العثور على العدد الأمثل للمجموعات
لإجراء تجميع k-medoid في لغة R، يمكننا استخدام الدالة pam() ، والتي تعني “التقسيم حول المتوسطات” وتستخدم الصيغة التالية:
pam(data, k, metric = “Euclidean”، stand = FALSE)
ذهب:
- البيانات: اسم مجموعة البيانات.
- ك: عدد المجموعات.
- المتري: المقياس المستخدم لحساب المسافة. الإعداد الافتراضي هو Euclidean ولكن يمكنك أيضًا تحديد manhattan .
- الوقوف: ما إذا كان سيتم تطبيع كل متغير في مجموعة البيانات أم لا. القيمة الافتراضية هي كاذبة.
نظرًا لأننا لا نعرف مسبقًا عدد المجموعات الأمثل، فسنقوم بإنشاء رسمين بيانيين مختلفين يمكن أن يساعدونا في اتخاذ القرار:
1. عدد المجموعات نسبة إلى المجموع في مجموع المربعات
أولاً، سنستخدم الدالة fviz_nbclust() لإنشاء رسم بياني لعدد العناقيد مقابل الإجمالي في مجموع المربعات:
fviz_nbclust(df, pam, method = “ wss ”)
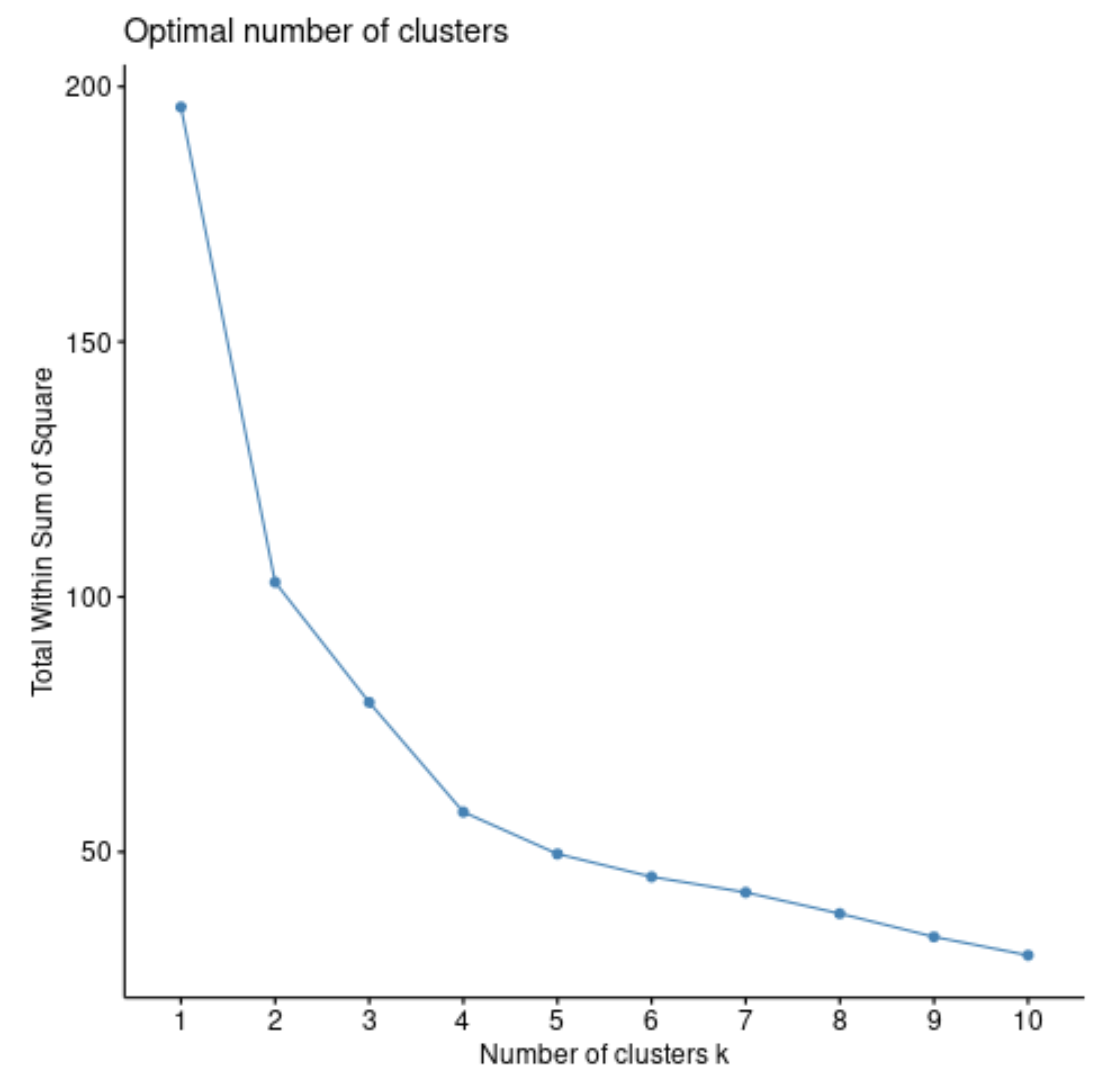
بشكل عام، سيزداد إجمالي مجموع المربعات دائمًا مع زيادة عدد المجموعات. لذلك عندما نقوم بإنشاء هذا النوع من الحبكة، فإننا نبحث عن “ركبة” حيث يبدأ مجموع المربعات في “الانحناء” أو الاستقرار.
تتوافق نقطة انحناء قطعة الأرض عمومًا مع العدد الأمثل للمجموعات. وبعد هذا الرقم، من المرجح أن يحدث فرط التجهيز .
بالنسبة لهذا الرسم البياني، يبدو أن هناك انحناء صغير أو “انحناء” عند k = 4 مجموعات.
2. عدد المجموعات مقابل إحصاءات الفجوات
هناك طريقة أخرى لتحديد العدد الأمثل للمجموعات وهي استخدام مقياس يسمى إحصائية الانحراف ، والذي يقارن إجمالي التباين داخل المجموعة لقيم k المختلفة مع قيمها المتوقعة للتوزيع بدون تجميع.
يمكننا حساب إحصائية الفجوة لكل عدد من المجموعات باستخدام الدالة clusGap() من حزمة المجموعة بالإضافة إلى رسم بياني للمجموعات مقابل إحصائيات الفجوة باستخدام الدالة fviz_gap_stat() :
#calculate gap statistic based on number of clusters gap_stat <- clusGap(df, FUN = pam, K.max = 10, #max clusters to consider B = 50) #total bootstrapped iterations #plot number of clusters vs. gap statistic fviz_gap_stat(gap_stat)
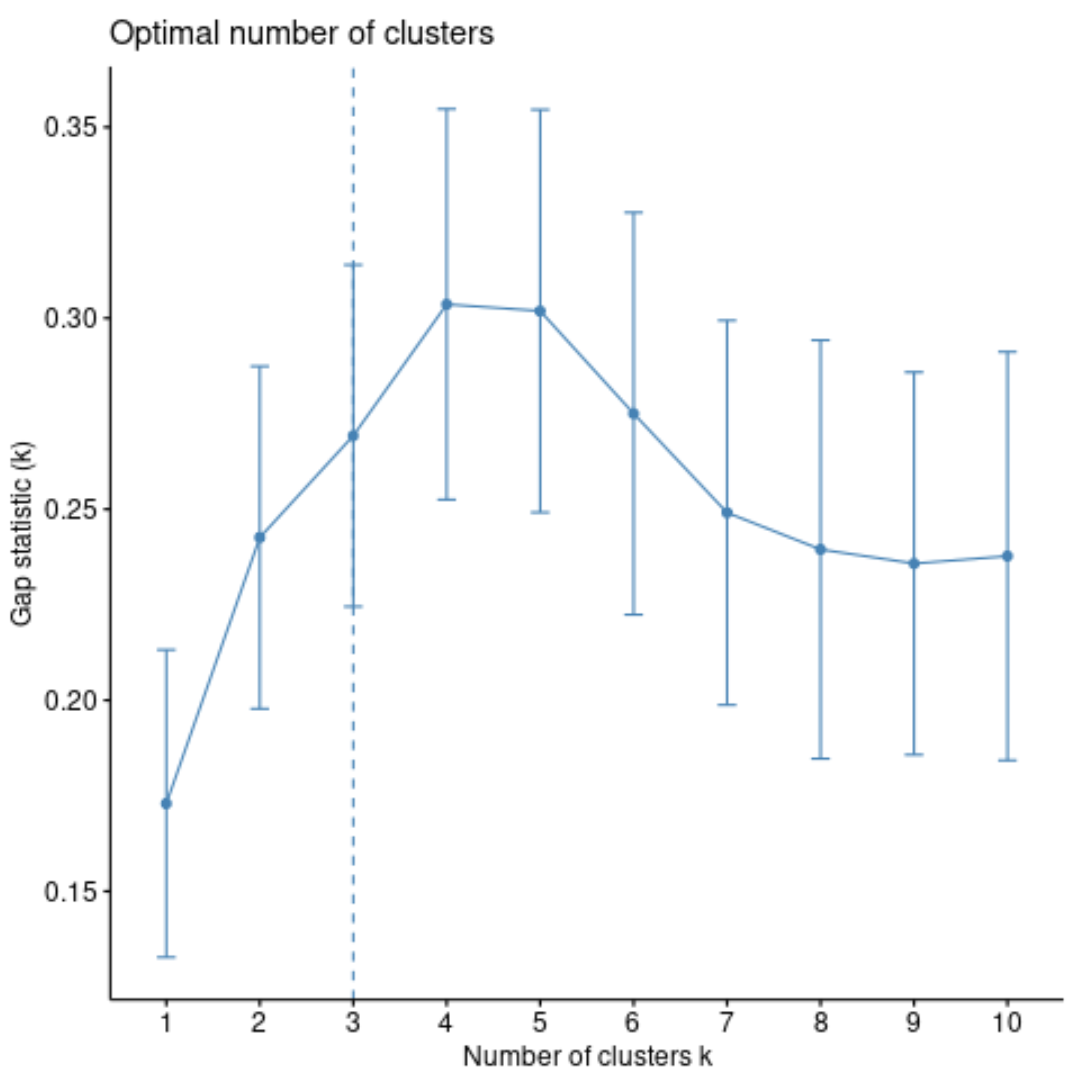
من الرسم البياني، يمكننا أن نرى أن إحصائية الفجوة هي الأعلى عند k = 4 مجموعات، وهو ما يتوافق مع طريقة الكوع التي استخدمناها سابقًا.
الخطوة 4: إجراء تجميع K-Medoids باستخدام Optimal K
أخيرًا، يمكننا إجراء تجميع k-medoids على مجموعة البيانات باستخدام القيمة المثالية لـ k لـ 4:
#make this example reproducible set.seed(1) #perform k-medoids clustering with k = 4 clusters kmed <- pam(df, k = 4) #view results kmed ID Murder Assault UrbanPop Rape Alabama 1 1.2425641 0.7828393 -0.5209066 -0.003416473 Michigan 22 0.9900104 1.0108275 0.5844655 1.480613993 Oklahoma 36 -0.2727580 -0.2371077 0.1699510 -0.131534211 New Hampshire 29 -1.3059321 -1.3650491 -0.6590781 -1.252564419 Vector clustering: Alabama Alaska Arizona Arkansas California 1 2 2 1 2 Colorado Connecticut Delaware Florida Georgia 2 3 3 2 1 Hawaii Idaho Illinois Indiana Iowa 3 4 2 3 4 Kansas Kentucky Louisiana Maine Maryland 3 3 1 4 2 Massachusetts Michigan Minnesota Mississippi Missouri 3 2 4 1 3 Montana Nebraska Nevada New Hampshire New Jersey 3 3 2 4 3 New Mexico New York North Carolina North Dakota Ohio 2 2 1 4 3 Oklahoma Oregon Pennsylvania Rhode Island South Carolina 3 3 3 3 1 South Dakota Tennessee Texas Utah Vermont 4 1 2 3 4 Virginia Washington West Virginia Wisconsin Wyoming 3 3 4 4 3 Objective function: build swap 1.035116 1.027102 Available components: [1] "medoids" "id.med" "clustering" "objective" "isolation" [6] "clusinfo" "silinfo" "diss" "call" "data"
لاحظ أن جميع النقط الوسطى العنقودية الأربعة هي ملاحظات فعلية في مجموعة البيانات. بالقرب من الجزء العلوي من الناتج، يمكننا أن نرى أن النقط الوسطى الأربعة هي الحالات التالية:
- ألاباما
- ميشيغان
- أوكلاهوما
- نيو هامبشاير
يمكننا تصور المجموعات على مخطط التشتت الذي يعرض أول مكونين رئيسيين على المحاور باستخدام الدالة fivz_cluster() :
#plot results of final k-medoids model
fviz_cluster(kmed, data = df)
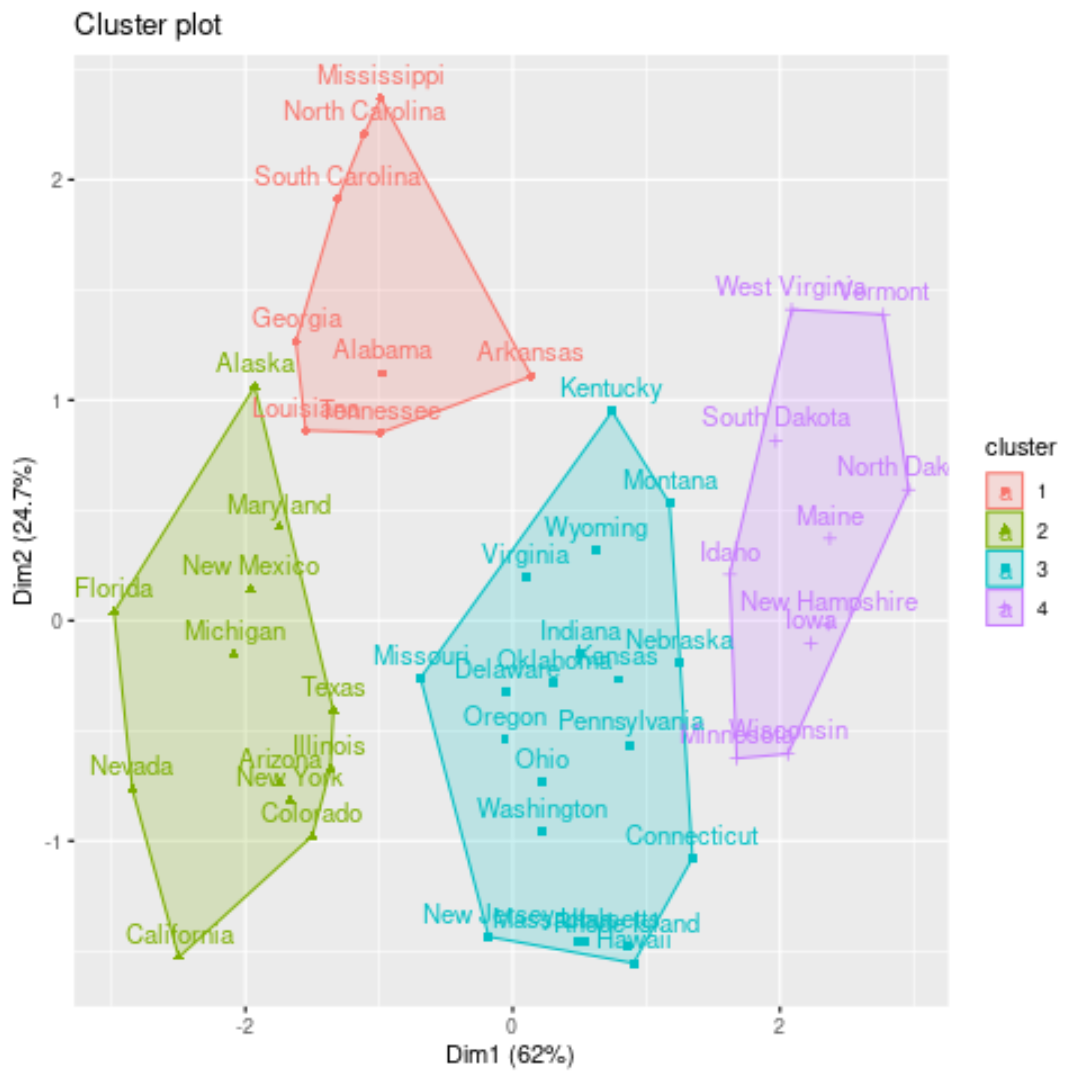
يمكننا أيضًا إضافة تخصيصات المجموعة لكل ولاية إلى مجموعة البيانات الأصلية:
#add cluster assignment to original data
final_data <- cbind(USArrests, cluster = kmed$cluster)
#view final data
head(final_data)
Murder Assault UrbanPop Rape cluster
Alabama 13.2 236 58 21.2 1
Alaska 10.0 263 48 44.5 2
Arizona 8.1 294 80 31.0 2
Arkansas 8.8 190 50 19.5 1
California 9.0 276 91 40.6 2
Colorado 7.9 204 78 38.7 2
يمكنك العثور على رمز R الكامل المستخدم في هذا المثال هنا .
About Author
دكتور بنيامين أندرسون
مرحبًا، أنا بنجامين، أستاذ الإحصاء المتقاعد الذي تحول إلى مدرس متخصص في Statorials. بفضل خبرتي الواسعة في مجال الإحصاء، فأنا حريص على مشاركة معرفتي لتمكين الطلاب من خلال Statorials. تعرف أكثر