Sas:如何在合并语句中使用 (in=a)
在 SAS 中合并两个数据集时,可以使用IN语句仅返回特定数据集中存在某个值的行。
以下是在实践中使用IN语句的一些常见方法:
方法 1:返回第一个数据集中存在值的行(in=a)
data final_data;
merge data1 (in=a) data2;
byID ;
if a;
run ;
此特定示例合并名为data1和data2 的数据集,并仅返回data1中存在值的行。
方法 2:返回第二个数据集中存在值的行(in=b)
data final_data;
merge data1 data2 (in=b);
byID ;
if b;
run ;
此特定示例合并名为data1和data2 的数据集,并仅返回data2中存在值的行。
方法 3:返回数据集中 (in=a) 和 (in=b) 中都存在值的行
data final_data;
merge data1(in=a) data2(in=b);
byID ;
if a and b;
run ;
此特定示例合并名为data1和data2 的数据集,并仅返回data1和data2中都存在值的行。
以下示例展示了如何在实践中使用以下两个数据集的每种方法:
/*create first dataset*/
data data1;
inputIDGender $;
datalines ;
1 Male
2 Male
3 Female
4 Male
5 Female
;
run ;
title "data1";
proc print data = data1;
/*create second dataset*/
data data2;
input IDSales;
datalines ;
1 22
2 15
4 29
6 31
7 20
8 13
;
run ;
title "data2";
proc print data = data2;
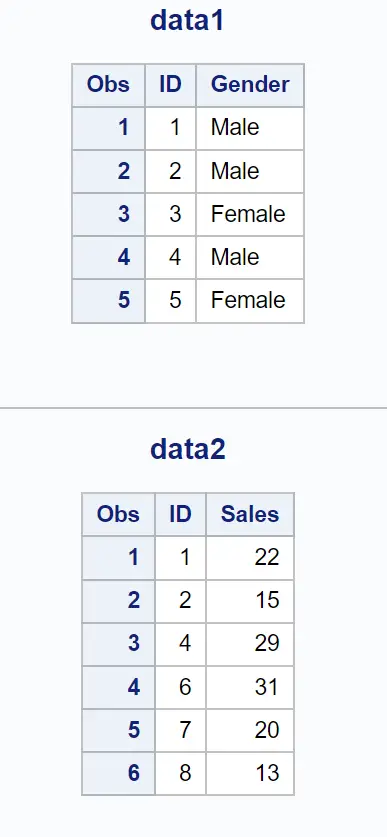
示例 1:返回所有行
我们可以使用以下不带任何IN语句的合并语句来根据ID列值合并两个数据集并返回两个数据集中的所有行:
/*perform merge*/
data final_data;
merge data1 data2;
byID ;
run ;
/*view results*/
title "final_data";
proc print data =final_data;
请注意,即使由于两个数据集中不存在 ID 值而导致值丢失,两个数据集中的所有行都会返回。
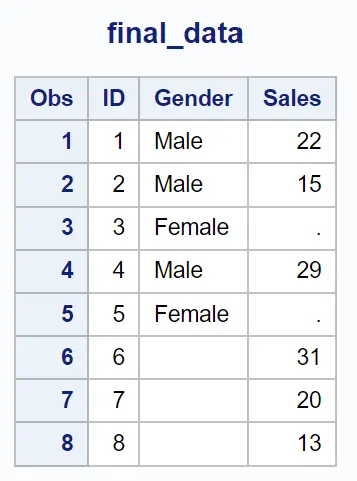
示例 2:返回第一个数据集中存在值的行 (in = a)
我们可以使用以下带有(in=a)的合并语句来根据ID列中的值合并两个数据集,并仅返回第一个数据集中存在值的行:
/*perform merge*/
data final_data;
merge data1 (in = a) data2;
byID ;
if a;
run ;
/*view results*/
title "final_data";
proc print data =final_data;
请注意,仅返回第一个数据集中存在值的行。
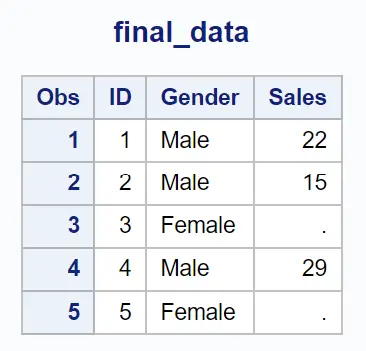
示例 3:返回第二个数据集中存在值的行 (in=b)
我们可以使用以下带有(in=b)的合并语句来根据ID列中的值合并两个数据集,并仅返回第二个数据集中存在值的行:
/*perform merge*/
data final_data;
merge data1 data2(in=b);
byID ;
if b;
run ;
/*view results*/
title "final_data";
proc print data =final_data;
请注意,仅返回第二个数据集中存在值的行。
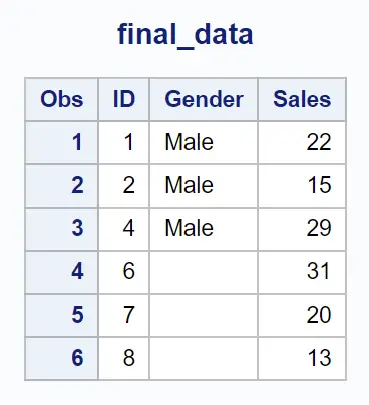
示例 4:返回数据集中 (in = a) 和 (in = b) 中都存在该值的行
我们可以使用以下带有(in=a)和(in=b)的合并语句,根据ID列中的值合并两个数据集,并仅返回两个数据集中都存在值的行:
/*perform merge*/
data final_data;
merge data1(in=a) data2(in=b);
byID ;
if a and b;
run ;
/*view results*/
title "final_data";
proc print data =final_data;
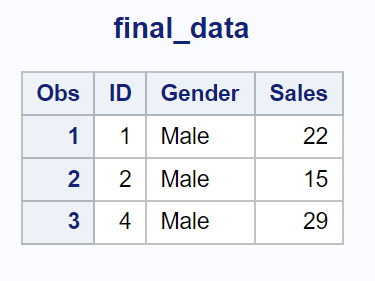
请注意,仅返回两个数据集中都存在值的行。
注意:您可以在此处找到 SAS merge语句的完整文档。
其他资源
以下教程解释了如何在 SAS 中执行其他常见任务:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多