岭回归简介
在普通的多元线性回归中,我们使用一组p 个预测变量和一个响应变量来拟合以下形式的模型:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
金子:
- Y :响应变量
- X j :第 j个预测变量
- β j :在保持所有其他预测变量不变的情况下,X j增加 1 个单位对 Y 的平均影响
- ε :误差项
β 0 , β 1 , B 2 , …, β p的值使用最小二乘法选择,该方法最小化残差平方和 (RSS):
RSS = Σ(y i – ŷ i ) 2
金子:
- Σ :希腊符号,意思是和
- y i :第 i 个观测值的实际响应值
- ŷ i :基于多元线性回归模型的预测响应值
然而,当预测变量高度相关时, 多重共线性可能会成为一个问题。这可能会使模型系数估计不可靠并表现出较高的方差。
在不从模型中完全删除某些预测变量的情况下解决此问题的一种方法是使用一种称为岭回归的方法,该方法旨在最小化以下内容:
RSS + λΣβ j 2
其中j从 1 到p并且λ ≥ 0。
等式中的第二项称为提款罚金。
当 λ = 0 时,该惩罚项不起作用,岭回归产生与最小二乘法相同的系数估计值。然而,当 λ 接近无穷大时,收缩惩罚变得更具影响力,并且峰值回归系数估计值接近零。
一般来说,模型中影响最小的预测变量将最快下降到零。
为什么使用岭回归?
岭回归相对于最小二乘回归的优势在于 偏差-方差权衡。
回想一下,均方误差 (MSE) 是我们可以用来衡量给定模型准确性的指标,其计算公式如下:
MSE = Var( f̂( x 0 )) + [偏差( f̂( x 0 ))] 2 + Var(ε)
MSE = 方差 + 偏差2 + 不可约误差
岭回归的基本思想是引入一个小的偏差,使得方差可以显着减小,从而导致整体MSE较低。
为了说明这一点,请考虑下图:

请注意,随着 λ 的增加,方差显着减小,而偏差的增加非常小。然而,超过某一点后,方差下降的速度会减慢,系数的下降会导致系数的显着低估,从而导致偏差急剧增加。
从图中我们可以看出,当我们选择在偏差和方差之间产生最佳权衡的 λ 值时,检验的 MSE 最低。
当 λ = 0 时,岭回归中的惩罚项不起作用,因此产生与最小二乘法相同的系数估计值。然而,通过将 λ 增加到某个点,我们可以降低测试的整体 MSE。
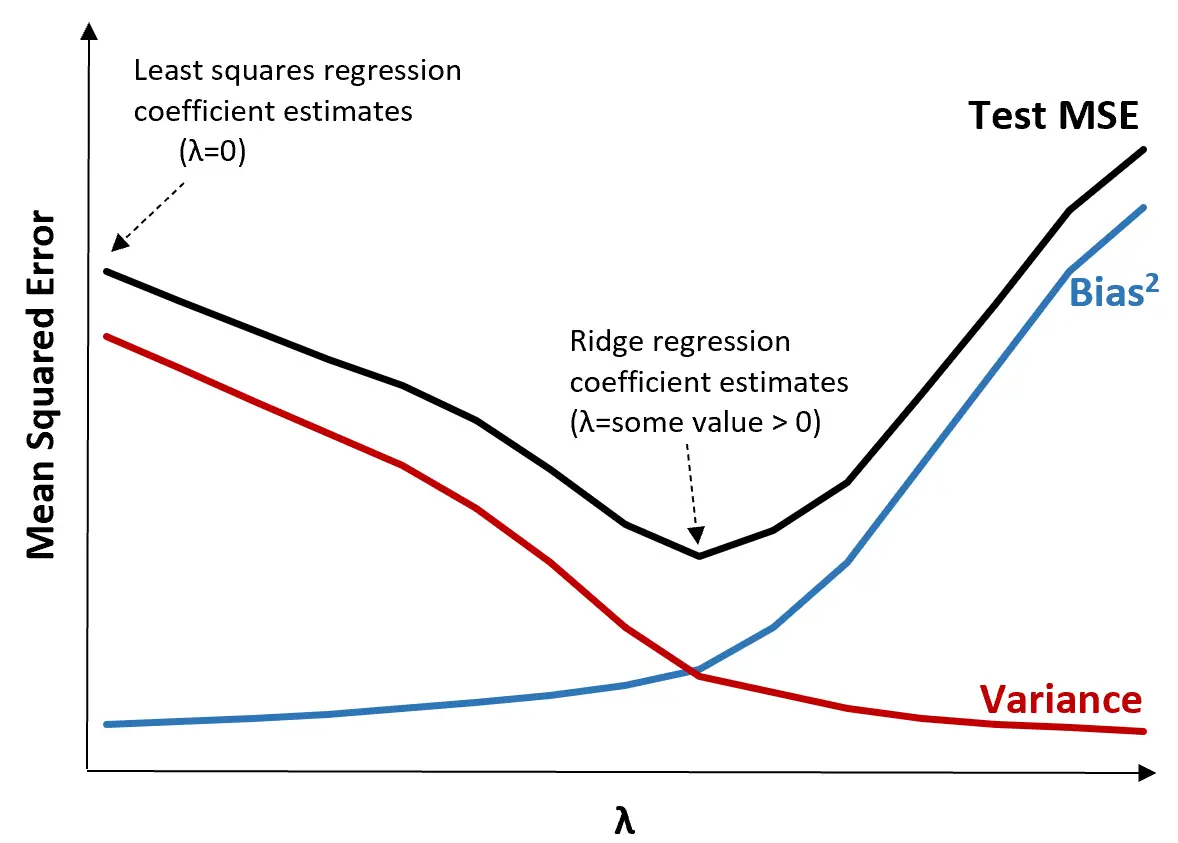
这意味着通过岭回归进行模型拟合将比通过最小二乘回归进行模型拟合产生更小的测试误差。
在实践中执行岭回归的步骤
以下步骤可用于执行岭回归:
步骤1:计算预测变量的相关矩阵和VIF值。
首先,我们需要生成一个相关矩阵并计算每个预测变量的VIF(方差膨胀因子)值。
如果我们检测到预测变量和高 VIF 值之间存在很强的相关性(一些文本将“高”VIF 值定义为 5,而其他文本则使用 10),那么岭回归可能是合适的。
但是,如果数据中不存在多重共线性,则可能不需要首先执行岭回归。相反,我们可以执行普通的最小二乘回归。
步骤 2:标准化每个预测变量。
在执行岭回归之前,我们需要对数据进行缩放,使每个预测变量的均值为 0,标准差为 1。这可确保在运行岭回归时没有单个预测变量会产生过大的影响。
步骤 3:拟合岭回归模型并选择 λ 值。
我们没有可以使用确切的公式来确定 λ 使用什么值。实际中,常用的λ选择方法有两种:
(1) 创建岭迹图。这是一张图表,直观地显示了随着 λ 向无穷大增加的系数估计值。通常,我们选择 λ 作为大多数系数估计开始稳定的值。
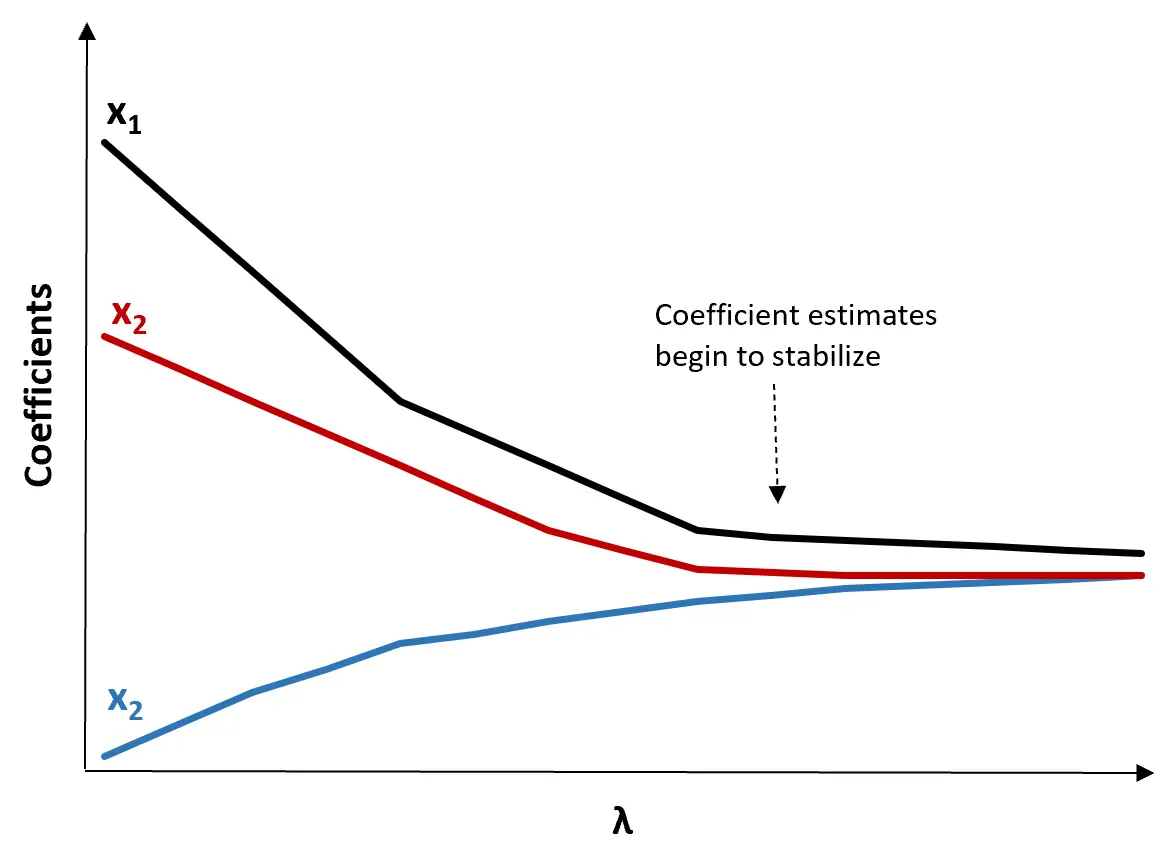
(2) 计算每个λ值的MSE检验。
选择 λ 的另一种方法是简单地计算具有不同 λ 值的每个模型的测试 MSE,并选择 λ 作为产生最低测试 MSE 的值。
岭回归的优点和缺点
岭回归的最大优点是,当存在多重共线性时,它能够产生比最小二乘法更低的检验均方误差 (MSE)。
然而,岭回归的最大缺点是它无法执行变量选择,因为它在最终模型中包含了所有预测变量。由于某些预测变量将减少到非常接近于零,这可能会导致模型结果难以解释。
在实践中,与最小二乘模型相比,岭回归有可能产生能够做出更好预测的模型,但解释模型的结果通常更困难。
根据模型解释或预测准确性对您来说更重要,您可以选择在不同场景中使用普通最小二乘法或岭回归。
R 和 Python 中的岭回归
以下教程解释了如何在 R 和 Python 这两种最常用的拟合岭回归模型的语言中执行岭回归:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多