监督学习和无监督学习的快速介绍
机器学习领域包含大量可用于理解数据的算法。这些算法可以分为以下两类之一:
1. 监督学习算法:涉及构建模型以根据一个或多个输入估计或预测结果。
2. 无监督学习算法:涉及从输入中查找结构和关系。没有“监督”输出。
本教程解释了这两种算法之间的区别以及每种算法的几个示例。
监督学习算法
当我们有一个或多个解释变量( X1 ,响应变量:
Y = f (X) + ε
其中f表示 X 提供的有关 Y 的系统信息,其中 ε 是独立于 X 且平均值为零的随机误差项。
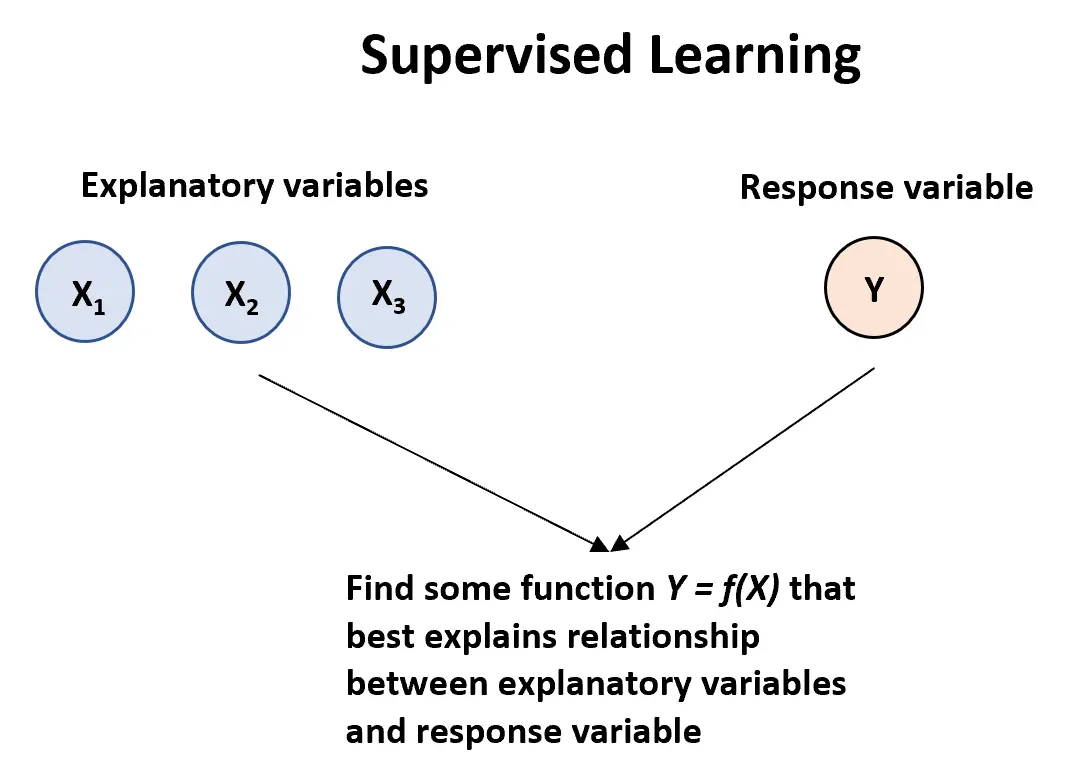
监督学习算法主要有两种类型:
1.回归:输出变量是连续的(例如体重、身高、时间等)
2.分类:输出变量是分类的(例如男性或女性、成功或失败、良性或恶性等)
我们使用监督学习算法有两个主要原因:
1.预测:我们经常使用一组解释变量来预测响应变量的值(例如,使用平方英尺和卧室数量来预测房屋的价格)。
2. 推论:我们可能有兴趣了解当解释变量的值发生变化时,响应变量如何受到影响(例如,当房间数量增加一间时,房地产价格平均上涨多少?)
根据我们的目标是推理还是预测(或两者的混合),我们可以使用不同的方法来估计函数f 。例如,线性模型提供更容易的解释,但难以解释的非线性模型可能提供更准确的预测。
以下是最常用的监督学习算法的列表:
- 线性回归
- 逻辑回归
- 线性判别分析
- 二次判别分析
- 决策树
- 朴素贝叶斯
- 支持向量机
- 神经网络
无监督学习算法
当我们有变量列表( X 1 , data.x )时,可以使用无监督学习算法。
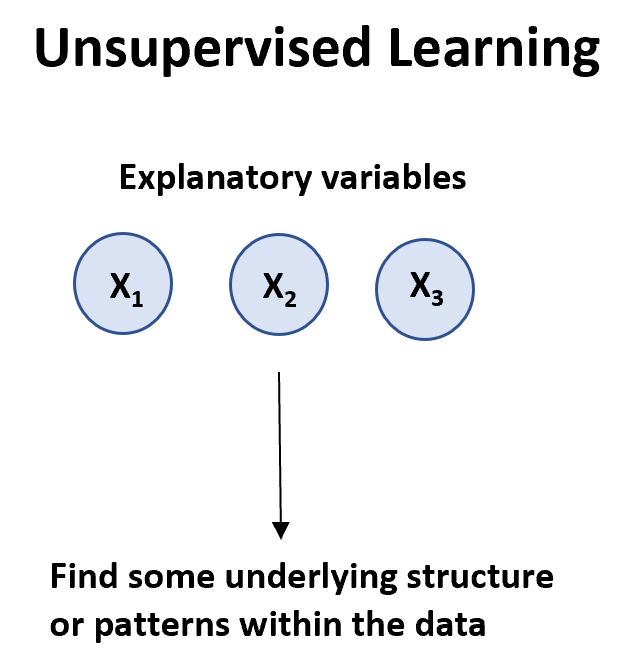
无监督学习算法主要有两种类型:
1. 聚类:使用这些类型的算法,我们尝试在数据集中找到彼此相似的观察“聚类”。当企业想要识别具有相似购买习惯的客户群时,这通常用于零售业,以便他们可以针对某些客户群制定特定的营销策略。
2.关联:使用这些类型的算法,我们试图找到可用于建立关联的“规则”。例如,零售商可以开发一种关联算法,表明“如果客户购买产品 X,他们很可能也会购买产品 Y”。
以下是最常用的无监督学习算法的列表:
- 主成分分析
- K-均值聚类
- K-中心点的分组
- 层次分类
- 先验算法
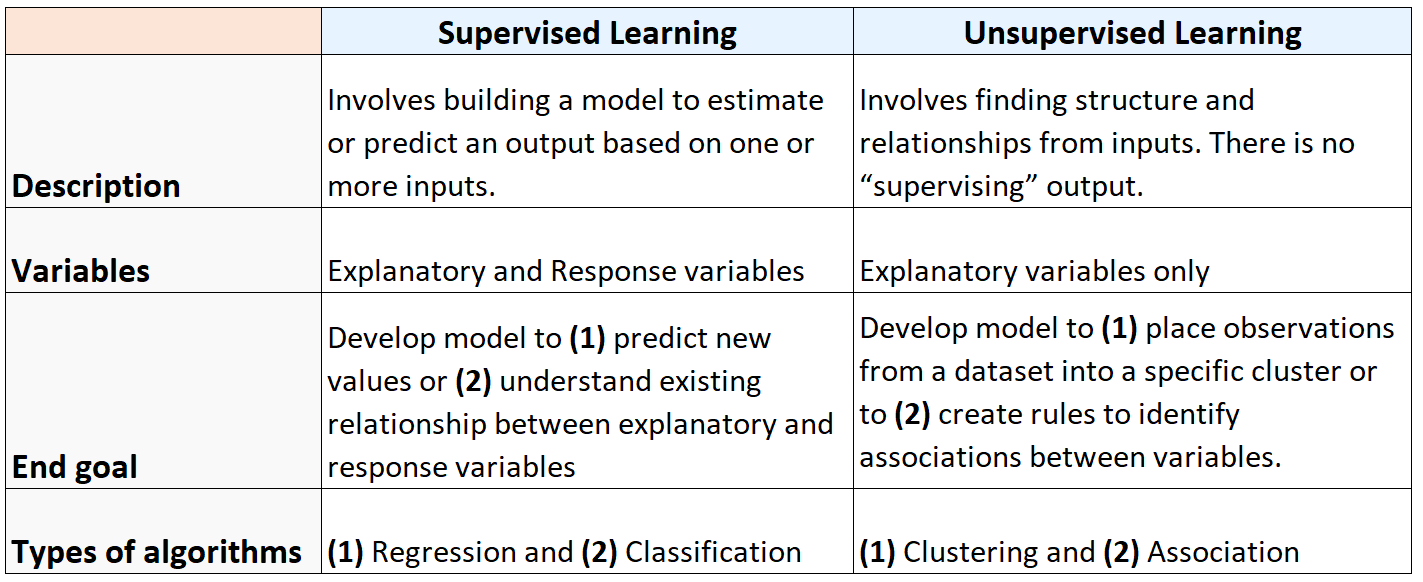
摘要:监督或无监督学习
下表总结了监督学习算法和无监督学习算法之间的差异:
下图总结了机器学习算法的类型:

关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多