R 中 iris 数据集的完整指南
iris数据集是 R 中的集成数据集,包含 3 个不同物种的 50 朵花的 4 个不同属性(以厘米为单位)的测量值。
本教程以 iris 数据集为例,介绍如何在 R 中探索和总结数据集。
加载鸢尾花数据集
由于iris数据集是R中的内置数据集,我们可以使用以下命令加载它:
data(iris)
我们可以使用head()函数查看数据集的前六行:
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
总结 Iris 数据集
我们可以使用summary()函数快速总结数据集中的每个变量:
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
对于每个数值变量,我们可以看到以下信息:
- 最小值:最小值。
- 第一个 Qu :第一个四分位数(第 25 个百分位数)的值。
- 中位数:中值。
- 平均值:平均值。
- 第三曲:第三个四分位数(第 75 个百分位数)的值。
- 最大值:最大值。
对于数据集中唯一的分类变量(物种),我们看到每个值的频率计数:
- setosa :该物种出现了 50 次。
- 杂色:该物种出现 50 次。
- virginica :该物种出现了 50 次。
我们可以使用dim()函数获取数据集的行数和列数维度:
#display rows and columns
dim(iris)
[1] 150 5
我们可以看到数据集有150行和5列。
我们还可以使用names()函数来显示数据框的列名称:
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
可视化 Iris 数据集
我们还可以创建绘图来可视化数据集的值。
例如,我们可以使用hist()函数创建某个变量值的直方图:
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
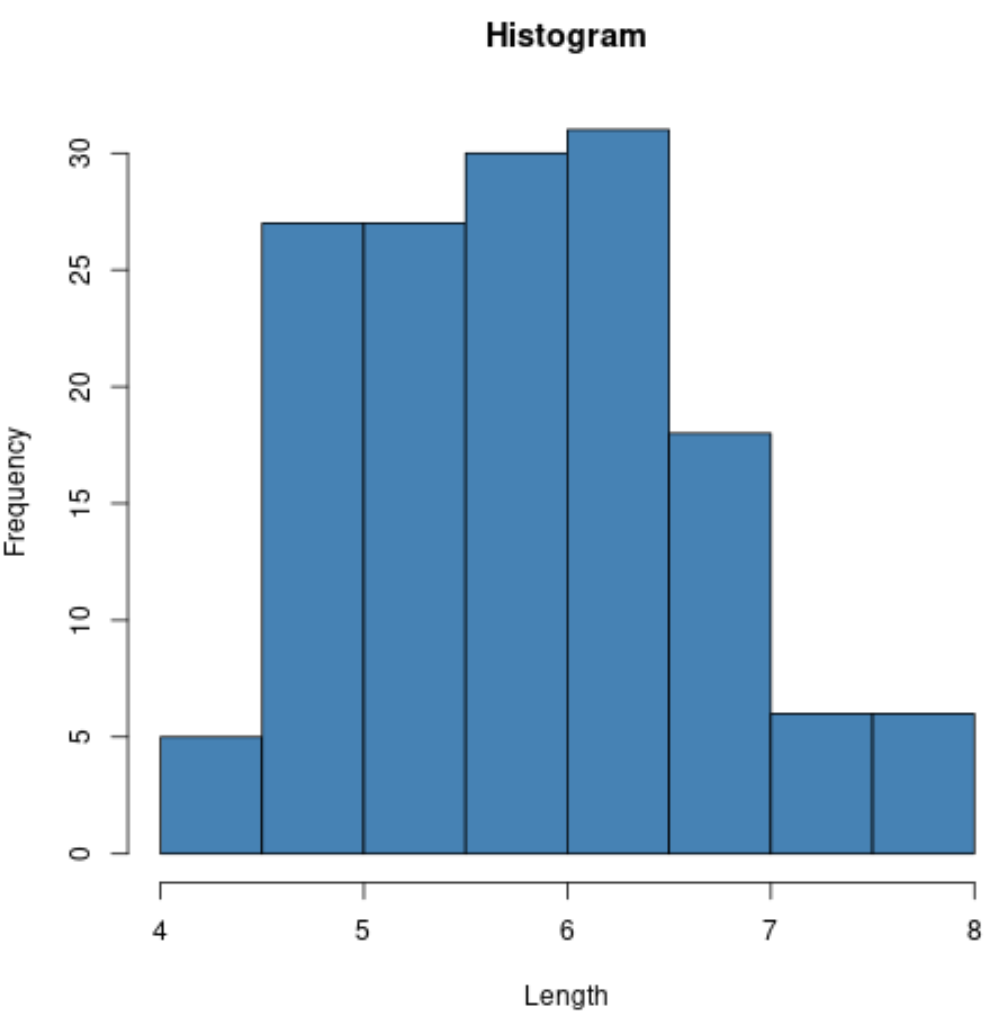
我们还可以使用plot()函数创建任意变量成对组合的散点图:
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
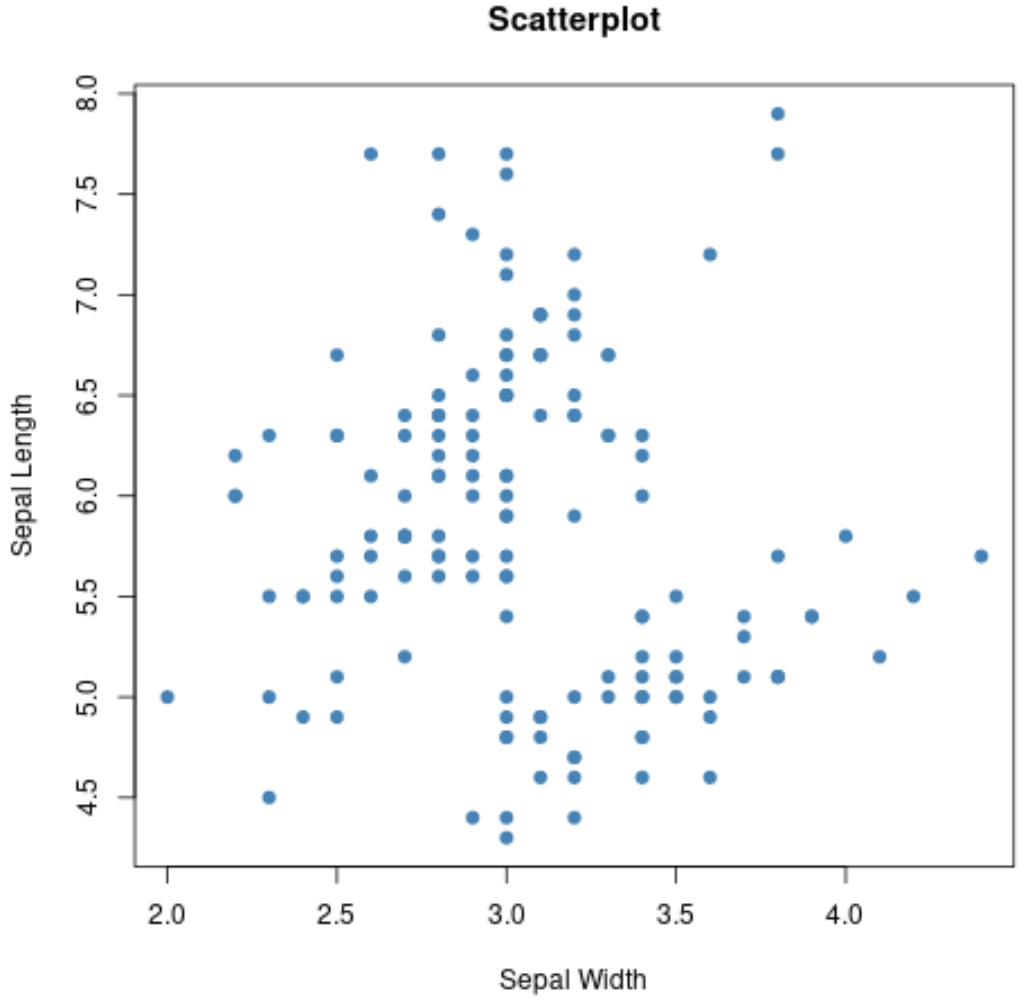
我们还可以使用boxplot()函数为每个组创建箱线图:
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
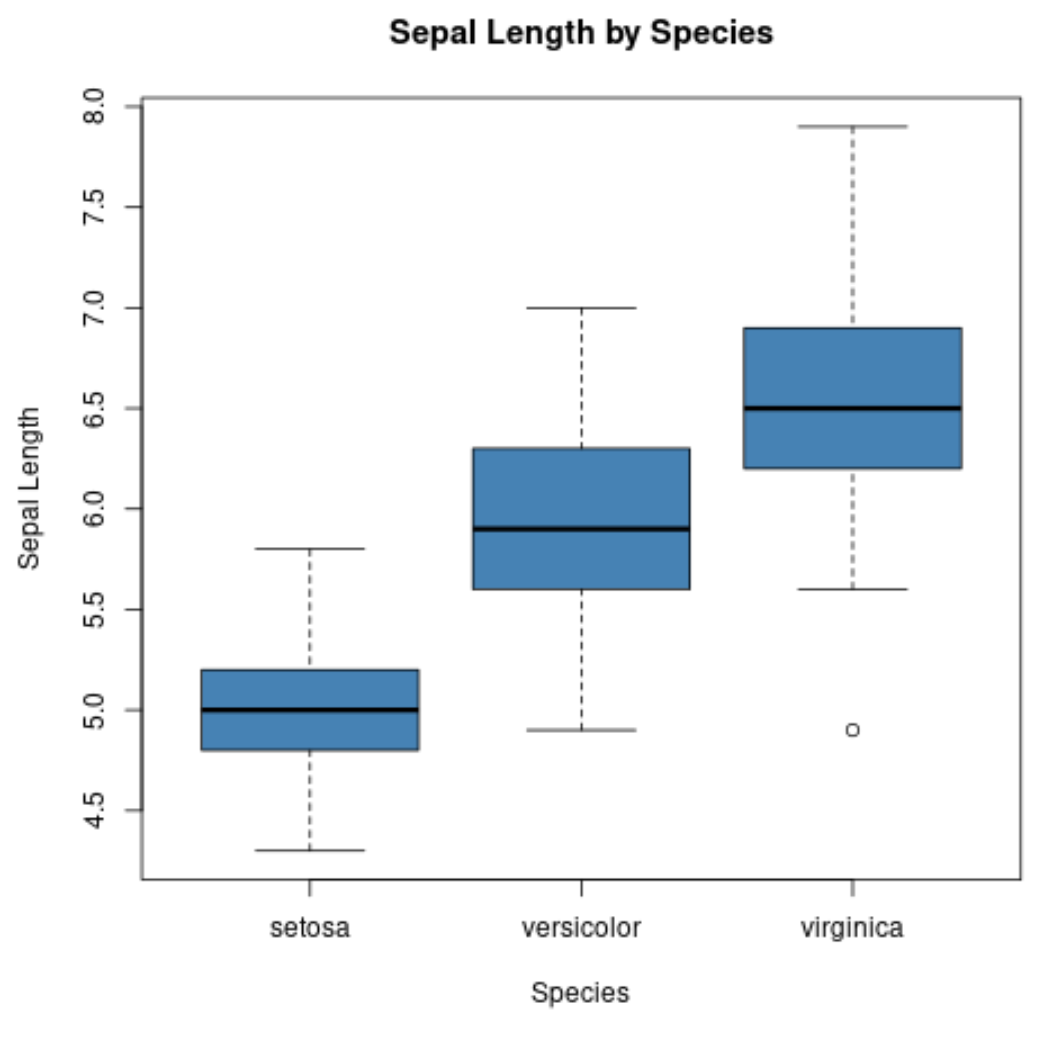
x 轴显示三个物种,y 轴显示每个物种的萼片长度值的分布。
这种类型的图使我们能够快速看出,弗吉尼亚物种的萼片长度往往是最大的,而山桃物种的萼片长度往往是最小的。
其他资源
以下教程更详细地解释了如何在 R 中汇总数据集:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多