随机选择或随机分配
随机选择和随机分配是两种常用但经常混淆的统计技术。
随机选择是指从群体中随机选择个体参与研究的过程。
随机分配是指将参与研究的个体随机分配到治疗组或对照组的过程。
您可以将随机选择视为“让”个体参与研究的过程,也可以将随机分配视为在这些个体被选为研究的一部分后您对这些个体“做”的事情。
随机选择和随机分配的重要性
当一项研究使用随机选择时,它会使用随机过程从群体中选择个体。例如,如果一个群体有 1,000 个个体,我们可以使用计算机从数据库中随机选择其中的 100 个个体。这意味着每个人都有相同的概率被选为研究的一部分,从而增加了获得代表性样本(与一般人群具有相似特征)的机会。
通过在我们的研究中使用代表性样本,我们能够将我们的研究结果推广到人群。用统计学术语来说,这被称为具有外部有效性——将我们的结果外化到一般人群是有效的。
当研究使用随机分配时,它将个体随机分配到治疗组或对照组。例如,如果我们的研究中有 100 个人,我们可以使用随机数生成器将 50 个人随机分配到对照组,将 50 个人分配到治疗组。
通过使用随机分配,我们增加了两组具有大致相似特征的机会,这意味着两组之间观察到的任何差异都可以归因于治疗。这意味着该研究具有内部有效性:将组之间的任何差异归因于治疗本身是有效的,而不是组中个体之间的差异。
随机选择和随机分配的示例
一项研究可以同时使用随机选择和随机分配,或者仅使用其中一种技术,或者两种技术都不使用。一项强有力的研究是同时使用这两种技术的研究。
以下示例展示了一项研究如何使用这两种技术、一种或不使用这两种技术,以及由此产生的效果。
示例 1:同时使用随机选择和随机分配
研究:研究人员想知道在某个 10,000 人的社区中,新饮食是否比标准饮食能带来更大的减肥效果。他们通过使用计算机从数据库中随机选择 100 个名字来招募 100 人参与研究。一旦他们拥有了全部 100 个人,他们再次使用计算机将 50 个人随机分配到对照组(例如坚持标准饮食),并将 50 个人分配到治疗组(例如遵循新饮食)。他们记录了每个人一个月后的总体重减轻情况。
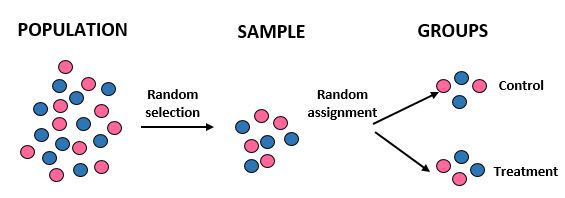
结果:研究人员在将个体放入治疗组或对照组时使用随机选择来获取样本和随机分配。通过这样做,他们能够将研究结果推广到总体人群,并将两组之间平均体重减轻的差异归因于新饮食。
示例 2:仅使用随机选择
研究:研究人员想知道在某个 10,000 人的社区中,新饮食是否比标准饮食能带来更大的减肥效果。他们通过使用计算机从数据库中随机选择 100 个名字来招募 100 人参与研究。然而,他们决定仅根据性别将个人分为几组。女性被分配到对照组,男性被分配到治疗组。他们记录了每个人一个月后的总体重减轻情况。
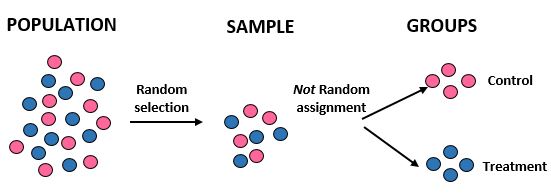
结果:研究人员使用随机选择来获取样本,但在将个体放入治疗组或对照组时没有使用随机分配。相反,他们使用特定因素——性别——来决定将个人分配到哪个组。通过这样做,他们能够将研究结果推广到总体人群,但他们无法将两组之间平均体重减轻的差异归因于新饮食。这项研究的内部有效性受到了影响,因为体重减轻的差异实际上可能只是由于性别而不是新饮食造成的。
示例 3:仅使用随机分配
研究:研究人员想知道在某个 10,000 人的社区中,新饮食是否比标准饮食能带来更大的减肥效果。他们正在招募 100 名男性运动员参与这项研究。然后他们使用计算机程序将 50 名男性运动员随机分配到对照组,将 50 名男性运动员分配到治疗组。他们记录了每个人一个月后的总体重减轻情况。
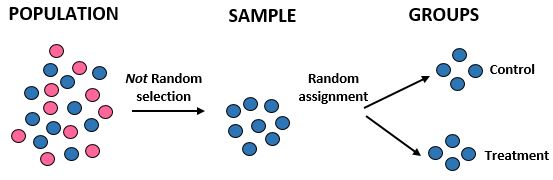
结果:研究人员没有使用随机选择来获取样本,因为他们专门选择了 100 名男性运动员。因此,他们的样本不能代表总体人群,其外部效度因此受到影响——他们无法将研究结果推广到总体人群。然而,他们使用了随机分配,这意味着他们可以将体重减轻的任何差异归因于新饮食。
示例 4:两种技术均不使用
研究:研究人员想知道在某个 10,000 人的社区中,新饮食是否比标准饮食能带来更大的减肥效果。他们正在招募 50 名男运动员和 50 名女运动员参与这项研究。然后他们将所有女运动员分配到对照组,将所有男运动员分配到治疗组。他们记录了每个人一个月后的总体重减轻情况。
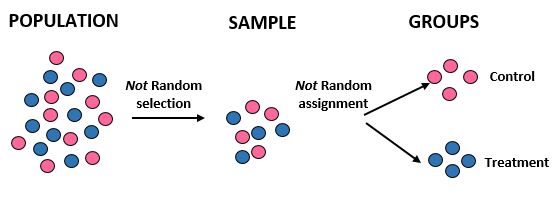
结果:研究人员没有使用随机选择来获取样本,因为他们专门选择了 100 名运动员。因此,他们的样本不能代表总体人群,其外部效度因此受到影响——他们无法将研究结果推广到总体人群。此外,他们根据性别而不是随机分配将个体分组,这意味着它们的内部有效性也受到损害——体重减轻的差异可能是由于性别而不是饮食造成的。
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多