验证集和测试集:有什么区别?
每当我们将机器学习算法应用于数据集时,我们通常将数据集分为三个部分:
1. 训练集:用于训练模型。
2.验证集:用于优化模型参数。
3. 测试集:用于获得最终模型性能的无偏估计。
下图提供了这三种不同类型的数据集的直观解释:
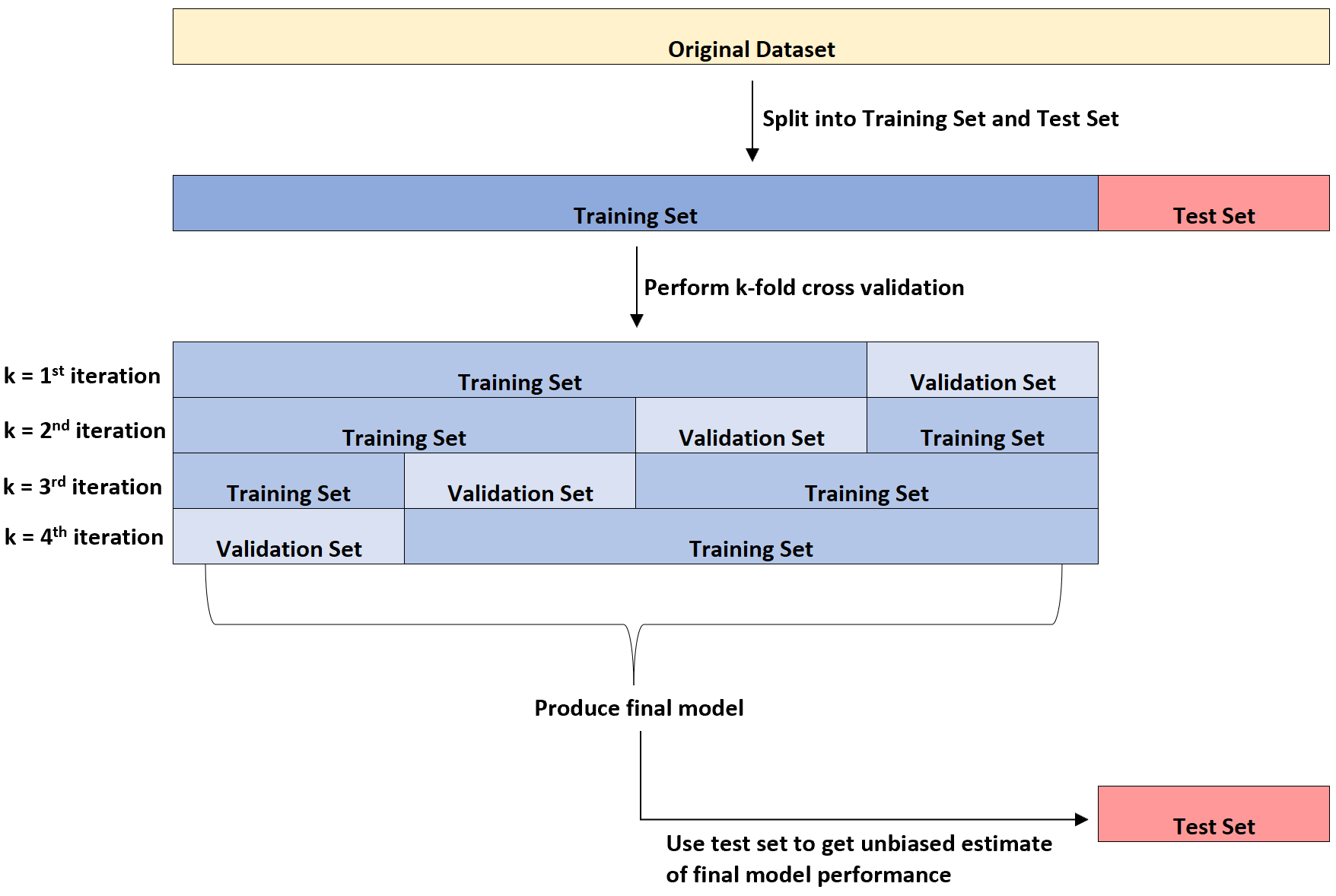
让学生感到困惑的一点是验证集和测试集之间的差异。
简而言之,验证集用于优化模型参数,而测试集用于提供最终模型的无偏估计。
可以看出,一旦将模型应用于不可见的数据集,通过 k 倍交叉验证测量的错误率往往会低估真实的错误率。
因此,我们将最终模型与测试集进行拟合,以获得对现实世界中真实错误率的无偏估计。
下面的例子说明了实践中验证集和测试集之间的区别。
示例:了解验证集和测试集之间的区别
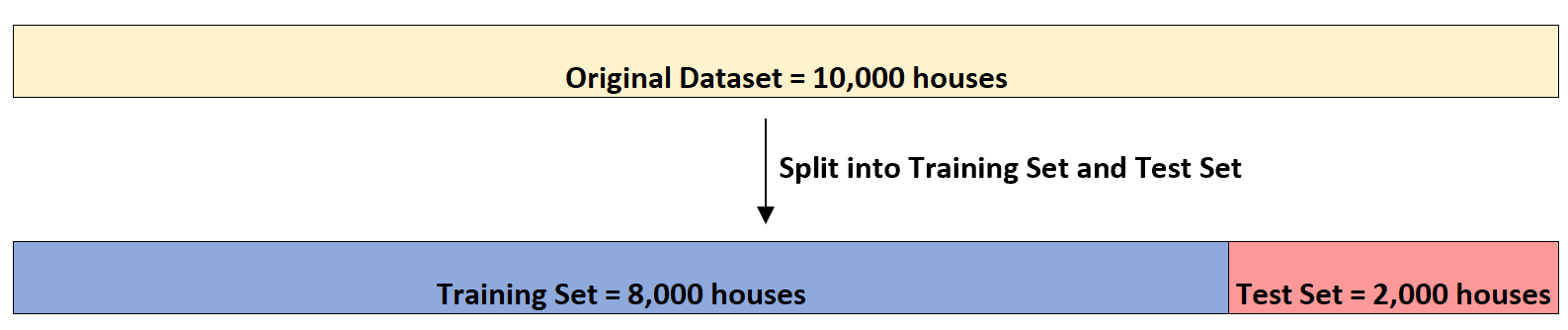
假设房地产投资者想要使用 (1) 卧室数量、(2) 总平方英尺数和 (3) 浴室数量来预测给定房屋的销售价格。
假设他有一个包含 10,000 栋房屋信息的数据集。首先,它将数据集分为包含 8,000 个房屋的训练集和包含 2,000 个房屋的测试集:
然后它将对数据集进行四次多元线性回归模型拟合。每次将使用 6,000 个房屋作为训练集,使用 2,000 个房屋作为验证集。
这称为k 折交叉验证。
训练集用于训练模型,验证集用于评估模型的性能。它将每次使用不同的 2,000 栋房屋组作为验证集。
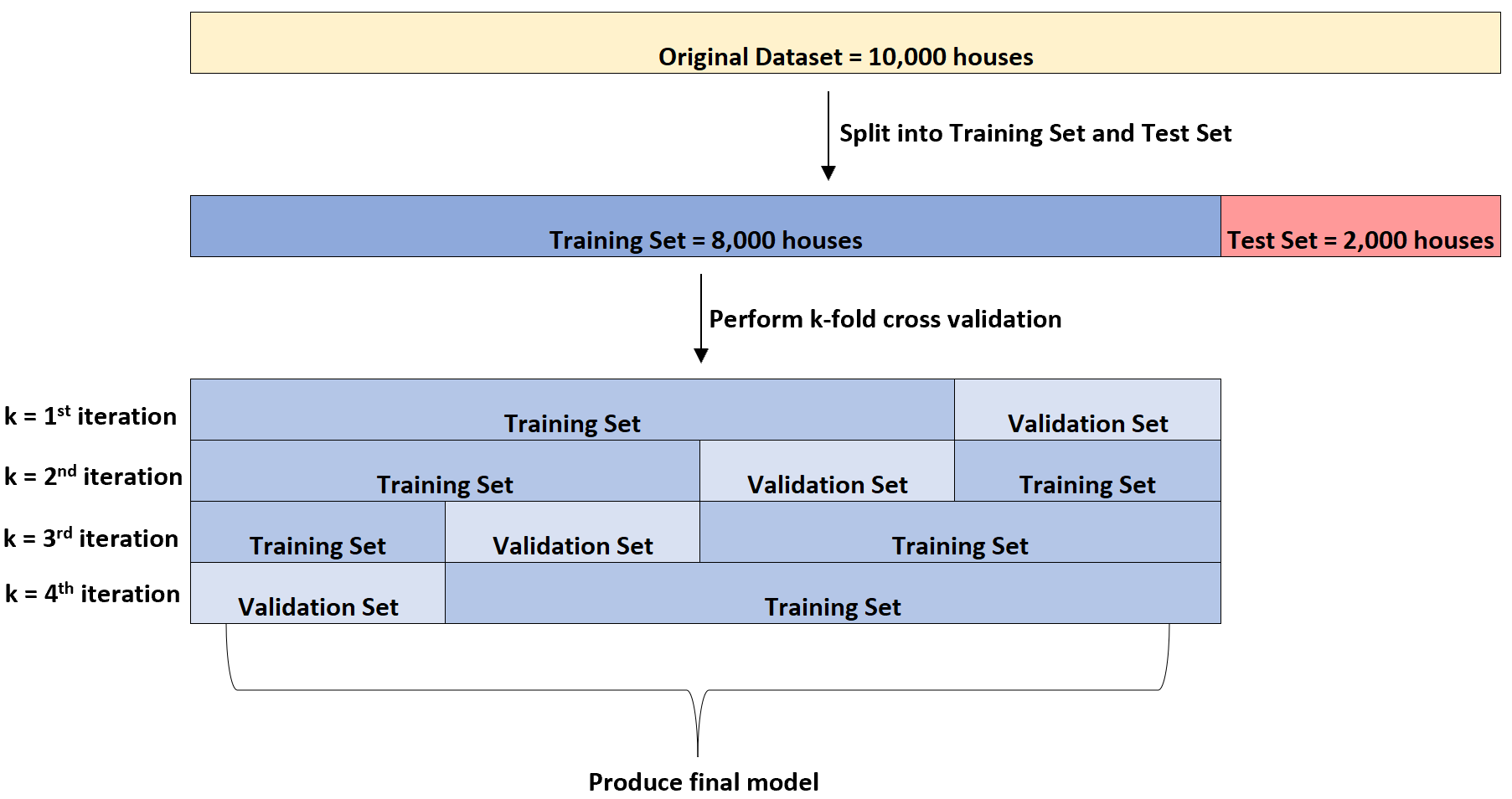
它可以对几种不同类型的回归模型执行此 k 折交叉验证,以识别具有最低误差的模型(即识别最适合数据集的模型)。
只有在确定了最佳模型后,它才会使用一开始提供的 2,000 个家庭测试集来对模型的最终性能进行公正的估计。
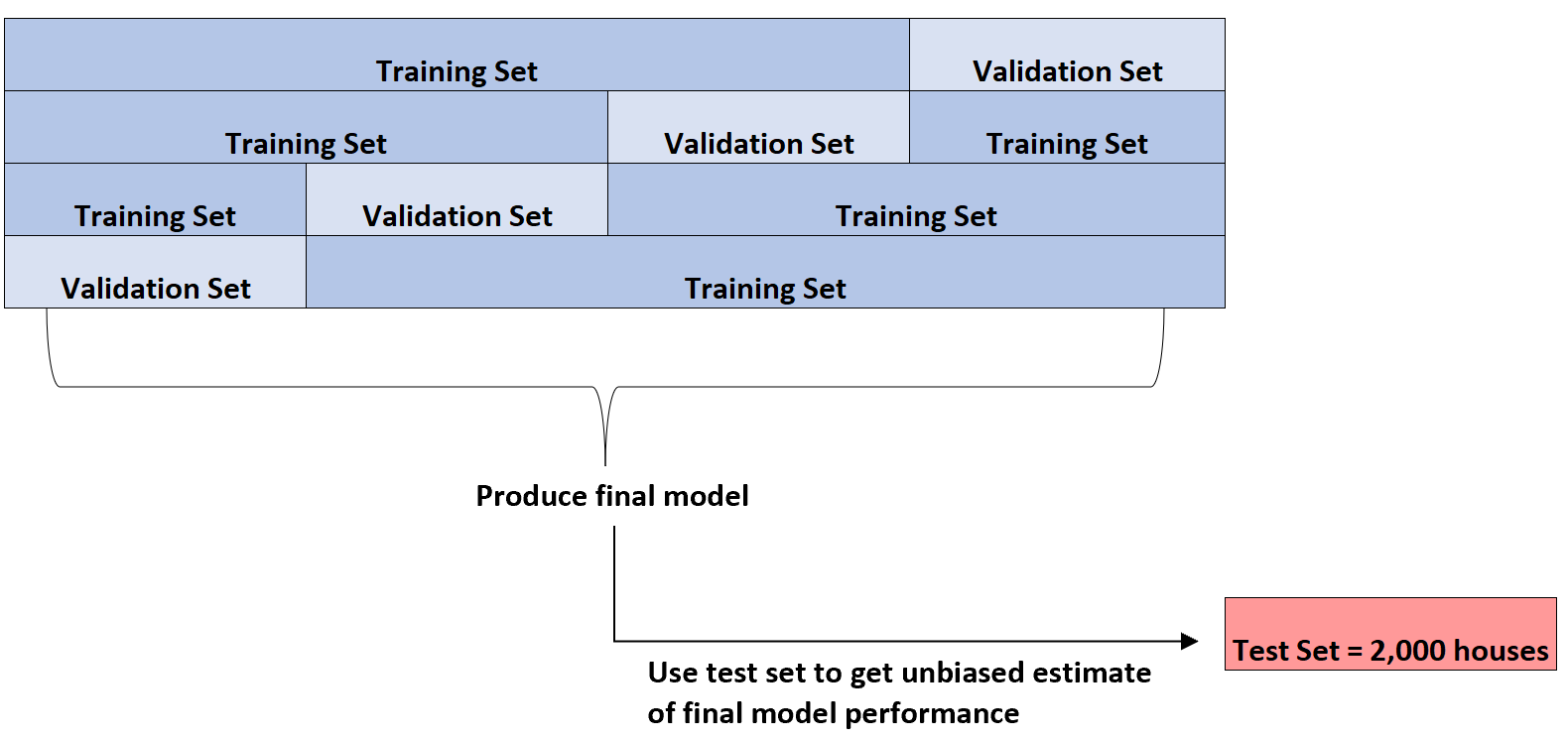
例如,它可以识别平均绝对误差为8.345的特定类型的回归模型。即预测房价与实际房价之间的平均绝对差值为8,345美元。
然后,他可以将这个精确的回归模型拟合到尚未使用的 2,000 栋房屋的测试集中,并发现模型的平均绝对误差为8.847 。
因此,模型真实平均绝对误差的无偏估计为 8,847 美元。
其他资源
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多