如何在 sas 中删除重复项(附示例)
您可以使用 SAS 中的proc sort来快速从数据集中删除重复行。
此过程使用以下基本语法:
proc sort data =original_data out =no_dups_data nodupkey ;
by _all_;
run;
请注意, by参数指定删除重复项时要扫描的列。
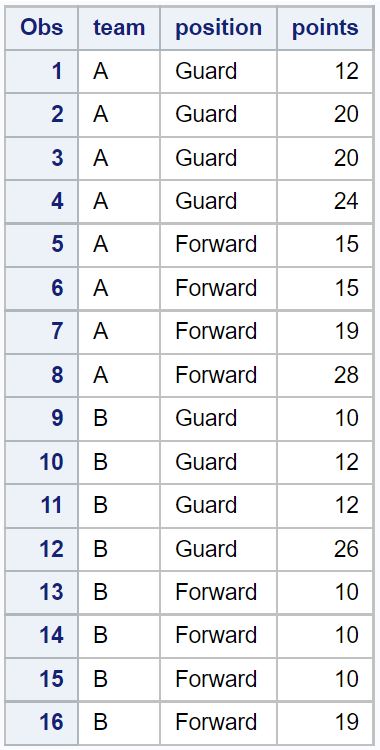
以下示例展示了如何从 SAS 中的以下数据集中删除重复项:
/*create dataset*/
data original_data;
input team $position $points;
datalines ;
A Guard 12
A Guard 20
A Guard 20
A Guard 24
A Forward 15
A Forward 15
A Forward 19
A Forward 28
B Guard 10
B Guard 12
B Guard 12
B Guard 26
B Forward 10
B Forward 10
B Forward 10
B Forward 19
;
run ;
/*view dataset*/
proc print data = original_data;
示例 1:从所有列中删除重复项
我们可以使用以下代码来删除数据集中所有列中具有重复值的行:
/*create dataset with no duplicate rows*/
proc sort data =original_data out =no_dups_data nodupkey ;
by _all_;
run ;
/*view dataset with no duplicate rows*/
proc print data =no_dups_data;
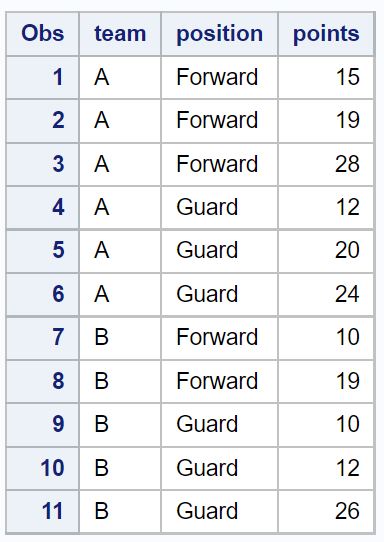
请注意,从原始数据集中删除了总共五个重复行。
示例 2:从特定列中删除重复项
我们可以使用by参数来指定删除重复项时要检查的列。
例如,以下代码删除team和position列中具有重复值的行:
/*create dataset with no duplicate rows in team and position columns*/
proc sort data =original_data out =no_dups_data nodupkey ;
by team position;
run ;
/*view dataset with no duplicate rows in team and position columns*/
proc print data =no_dups_data;
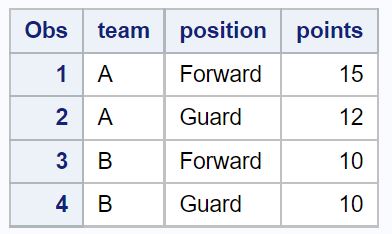
删除团队和位置列中具有重复值的行后,数据集中仅保留四行。
其他资源
以下教程解释了如何在 SAS 中执行其他常见操作:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多