Excel 中的皮尔逊偏度系数(逐步)
皮尔逊偏度系数由生物统计学家Karl Pearson开发,是一种测量样本数据集中偏度的方法。
实际上有两种方法可以用来计算皮尔逊偏度系数:
方法一:使用方式
偏度 =(平均值 – 众数)/样本标准差
方法 2:使用中位数
偏度 = 3(平均值 – 中位数)/样本标准差
一般来说,第二种方法是优选的,因为众数并不总是能够很好地指示数据集的“中心”值所在的位置,并且在给定的数据集中可能存在多个众数。
以下分步示例演示如何在 Excel 中计算给定数据集的两个版本的 Pearson 偏度系数。
第 1 步:创建数据集
首先,我们在 Excel 中创建以下数据集:
步骤2:计算皮尔逊偏度系数(使用众数)
那么我们可以使用下面的公式来计算使用众数的皮尔逊偏度系数:
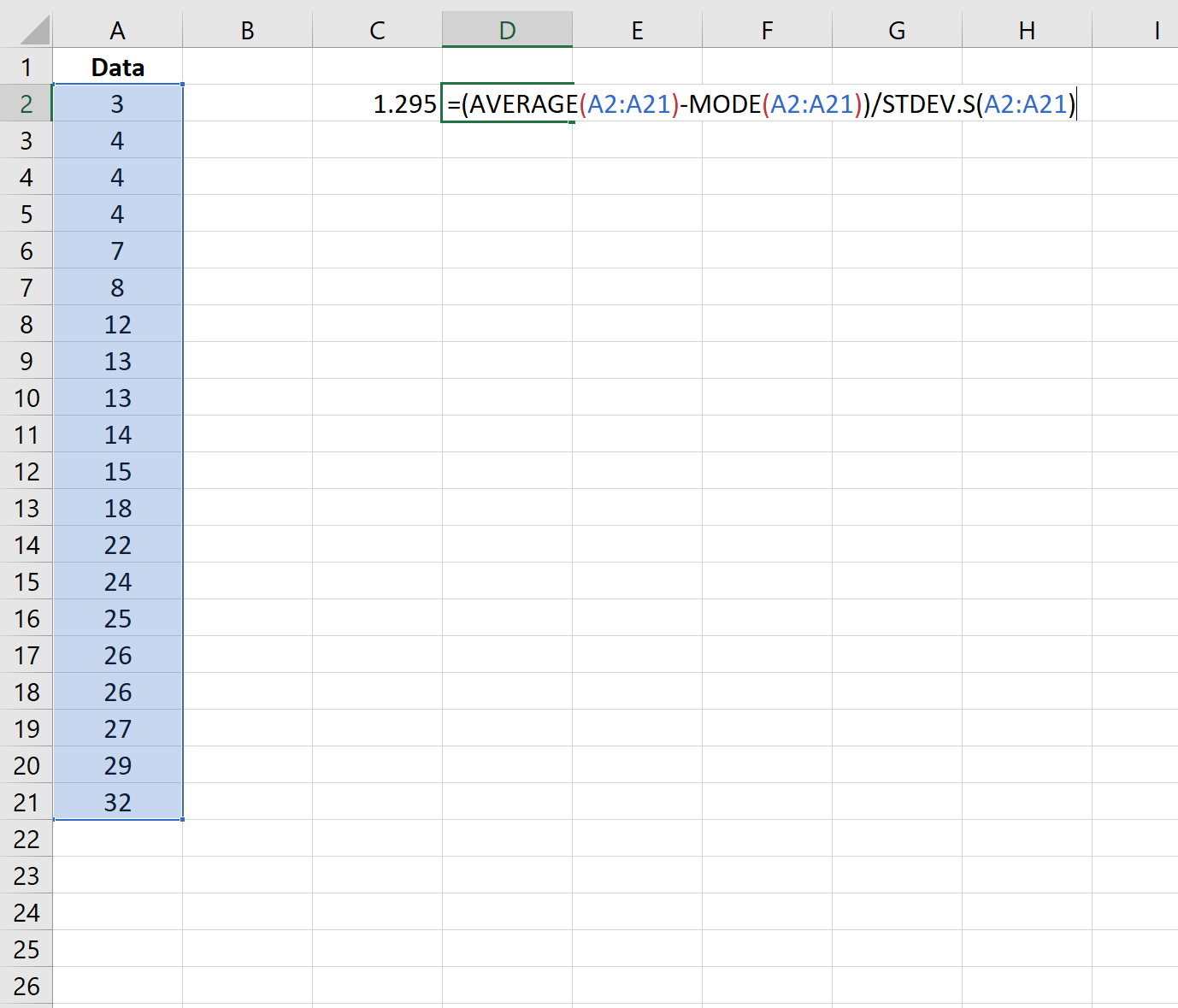
偏度结果为1.295 。
步骤 3:计算皮尔逊偏度系数(使用中位数)
我们还可以使用下面的公式来计算使用中位数的皮尔逊偏度系数:
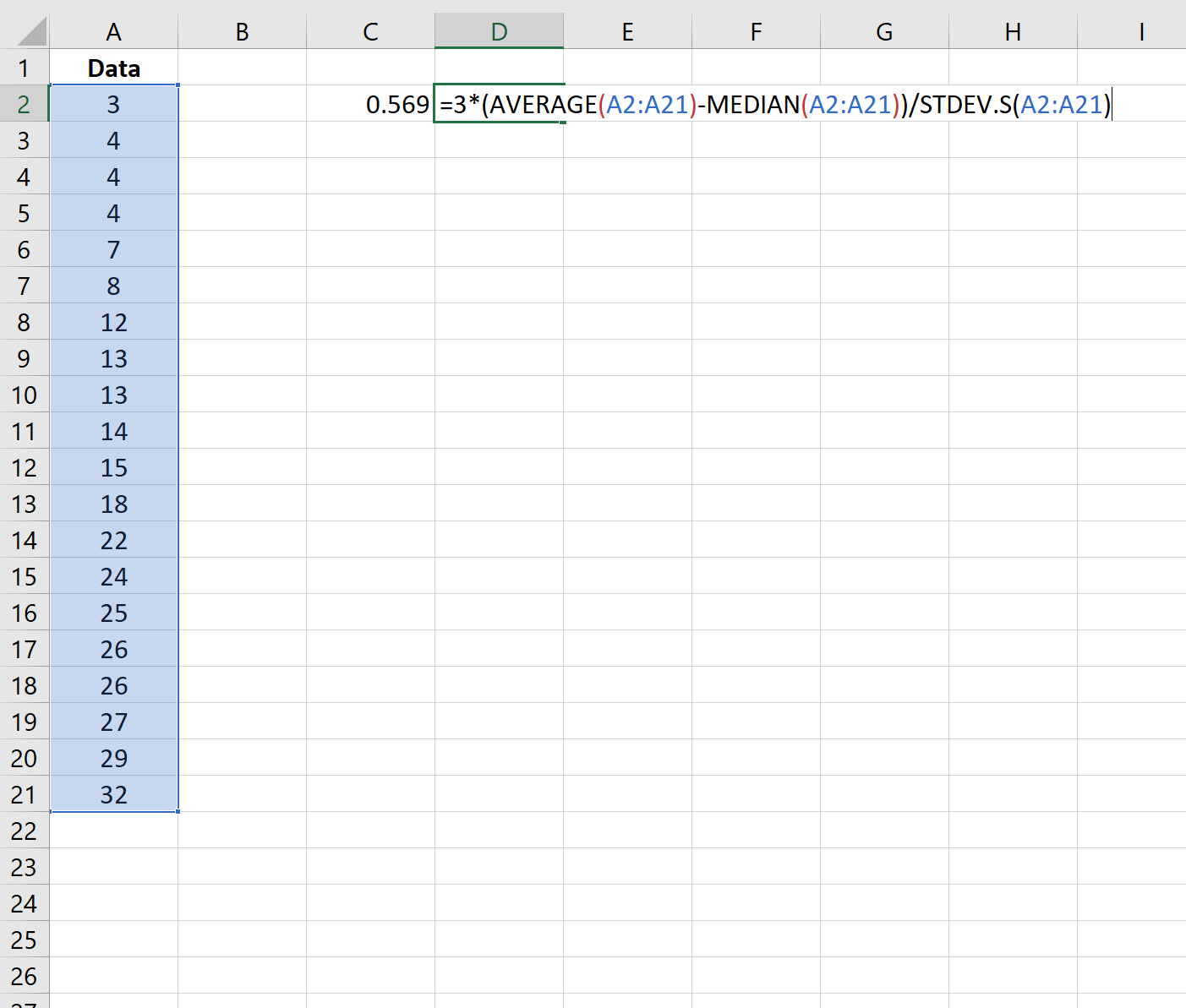
不对称性结果为0.569 。
如何解释不对称性
我们通过以下方式解释皮尔逊不对称系数:
- 值为 0表示没有不对称性。如果我们创建一个直方图来可视化数据集中值的分布,它将是完全对称的。
- 正值表示正倾斜或“右”倾斜。直方图会显示分布右侧的“尾部”。
- 负值表示负倾斜或“左”倾斜。直方图会显示分布左侧的“尾部”。
在我们之前的示例中,偏度为正,表明数据值的分布是正偏或“右”。
其他资源
查看这篇文章,了解左右偏态分布的详细解释。
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多