什么是置信区间?
在统计学中,我们通常感兴趣的是测量总体参数,即描述整个总体某些特征的数字。
两个最常见的总体参数是:
1.总体平均值:某个变量在总体中的平均值(例如美国男性的平均身高)
2.人口比例:某个变量在人口中所占的比例(例如,一个县内支持某项法律的居民所占的比例)
即使我们想要测量这些参数,收集种群中每个个体的数据来计算种群参数通常也太昂贵且耗时。
相反,我们通常从总体中随机抽取样本,并使用样本数据来估计总体参数。
例如,假设我们想要估计佛罗里达州某种海龟的平均重量。由于佛罗里达州有数千只海龟,因此四处走动并单独称重每只海龟将非常耗时且昂贵。
相反,我们可以抽取 50 只海龟的简单随机样本,并使用该样本中海龟的平均重量来估计真实的种群平均值:
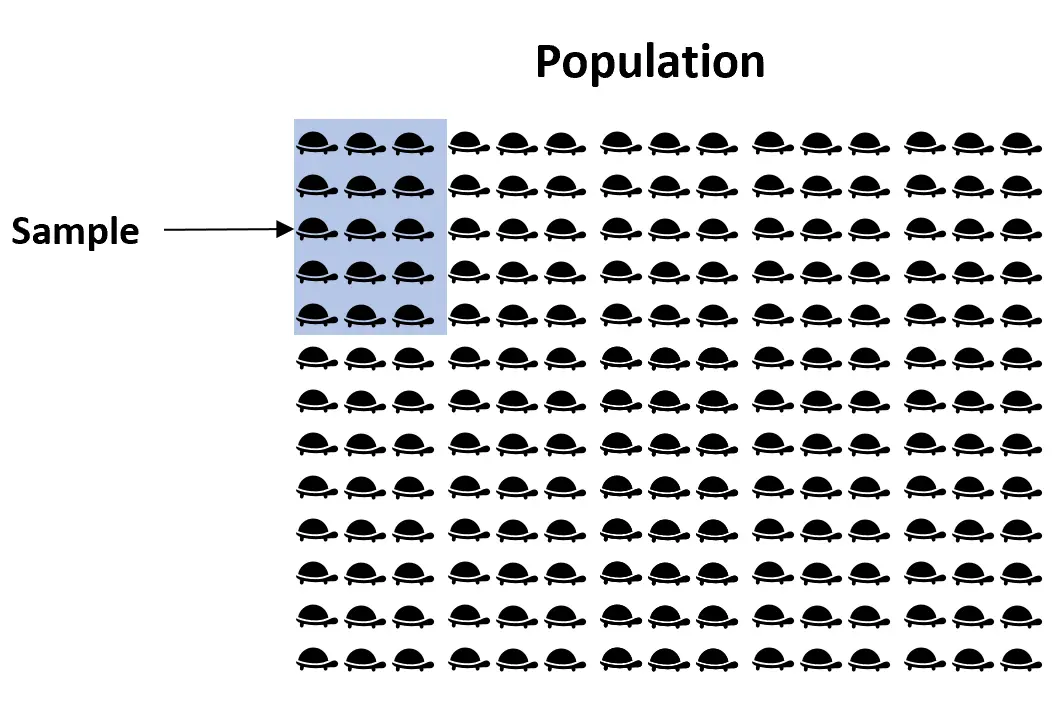
问题在于,不能保证样本中海龟的平均体重与整个群体中海龟的平均体重完全匹配。例如,我们可能会选择一个充满轻重量海龟的样本,或者可能选择一个充满重海龟的样本。
为了捕捉这种不确定性,我们可以创建一个置信区间。置信区间是可能包含具有一定置信水平的总体参数的值范围。根据以下通用公式计算:
置信区间=(点估计)+/-(临界值)*(标准误差)
此公式创建一个具有下限和上限的区间,其中可能包含具有一定置信度的总体参数。
置信区间=[下限,上限]
例如,计算总体平均值的置信区间的公式为:
置信区间 = x +/- z*(s/√ n )
金子:
- x :样本均值
- z:选择的z值
- s:样本标准差
- n:样本量
您使用的 z 值取决于您选择的置信水平。下表显示了与最常见的置信水平选择相对应的 z 值:
| 一定程度的信心 | z值 |
|---|---|
| 0.90 | 1,645 |
| 0.95 | 1.96 |
| 0.99 | 2.58 |
例如,假设我们收集具有以下信息的海龟随机样本:
- 样本量n = 25
- 平均样本重量x = 300
- 样本标准差s = 18.5
以下是计算真实总体平均体重的 90% 置信区间的方法:
90% 置信区间: 300 +/- 1.645*(18.5/√25) = [293.91, 306.09]
我们将此置信区间解释如下:
[293.91, 306.09] 的置信区间有 90% 的可能性包含海龟种群的真实平均体重。
同一件事的另一种说法是,真实总体平均值只有 10% 的可能性位于 90% 置信区间之外。也就是说,海龟种群的实际平均体重大于306.09磅或小于293.91磅的可能性只有10%。
毫无意义的是,有两个数字可以影响置信区间的大小:
1.样本量:样本量越大,置信区间越窄。
2. 置信水平:置信水平越高,置信区间越宽。
置信区间的类型
置信区间有多种类型。以下是最常用的:
平均值的置信区间
均值的置信区间是可能包含具有一定置信水平的总体均值的值范围。计算该间隔的公式如下:
置信区间 = x +/- z*(s/√ n )
金子:
- x :样本均值
- z:选择的z值
- s:样本标准差
- n:样本量
平均值之间差异的置信区间
均值差异的置信区间 (CI)是可能包含具有一定置信水平的两个总体均值之间的真实差异的值范围。计算该间隔的公式如下:
置信区间= ( x 1 – x 2 ) +/- t*√((s p 2 /n 1 ) + (s p 2 /n 2 ))
金子:
- x 1 , x 2 :样本 1 的平均值,样本 2 的平均值
- t:基于置信水平和 (n 1 + n 2 -2) 自由度的 t 临界值
- sp 2 :合并方差
- n 1 , n 2 : 样本量 1, 样本量 2
金子:
- 合并方差计算如下: s p 2 = ((n 1 -1)s 1 2 + (n 2 -1)s 2 2 ) / (n 1 +n 2 -2)
- t 临界值t可以使用逆 t 分布计算器找到。
资源:
如何计算平均值之间差异的置信区间
均值差异计算器的置信区间
比例的置信区间
比例的置信区间是可能包含具有一定置信水平的总体比例的值范围。计算该间隔的公式如下:
置信区间 = p +/- z*(√ p(1-p) / n )
金子:
- p:样本比例
- z:选择的z值
- n:样本量
比例差异的置信区间
比例差异的置信区间是可能包含具有一定置信度的两个总体比例之间的真实差异的值范围。计算该间隔的公式如下:
置信区间 = (p 1 –p 2 ) +/- z*√(p 1 (1-p 1 )/n 1 + p 2 (1-p 2 )/n 2 )
金子:
- p 1 , p 2 : 样本1的比例,样本2的比例
- z:基于置信水平的 z 临界值
- n 1 , n 2 : 样本量 1, 样本量 2
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多