什么是虚拟变量陷阱? (定义&;示例)
线性回归是一种可以用来量化一个或多个预测变量与响应变量之间关系的方法。
我们通常使用带有定量变量的线性回归。有时称为“数字”变量,这些变量代表可测量的数量。示例包括:
- 房子的平方英尺数
- 一个城市的人口规模
- 个人年龄
然而,有时我们想使用分类变量作为预测变量。这些变量采用名称或标签,并且可以分为类别。示例包括:
- 眼睛颜色(例如“蓝色”、“绿色”、“棕色”)
- 性别(例如“男”、“女”)
- 婚姻状况(例如“已婚”、“单身”、“离婚”)
使用分类变量时,仅仅将 1、2、3 之类的值分配给“蓝色”、“绿色”和“棕色”之类的值是没有意义的,因为这样说是没有意义的那个绿色是双倍的。与蓝色或棕色一样丰富多彩的颜色是蓝色的三倍。
相反,解决方案是使用虚拟变量。这些是我们专门为回归分析创建的变量,它们采用两个值之一:零或一。
我们需要创建的虚拟变量的数量等于k -1,其中k是分类变量可以采用的不同值的数量。
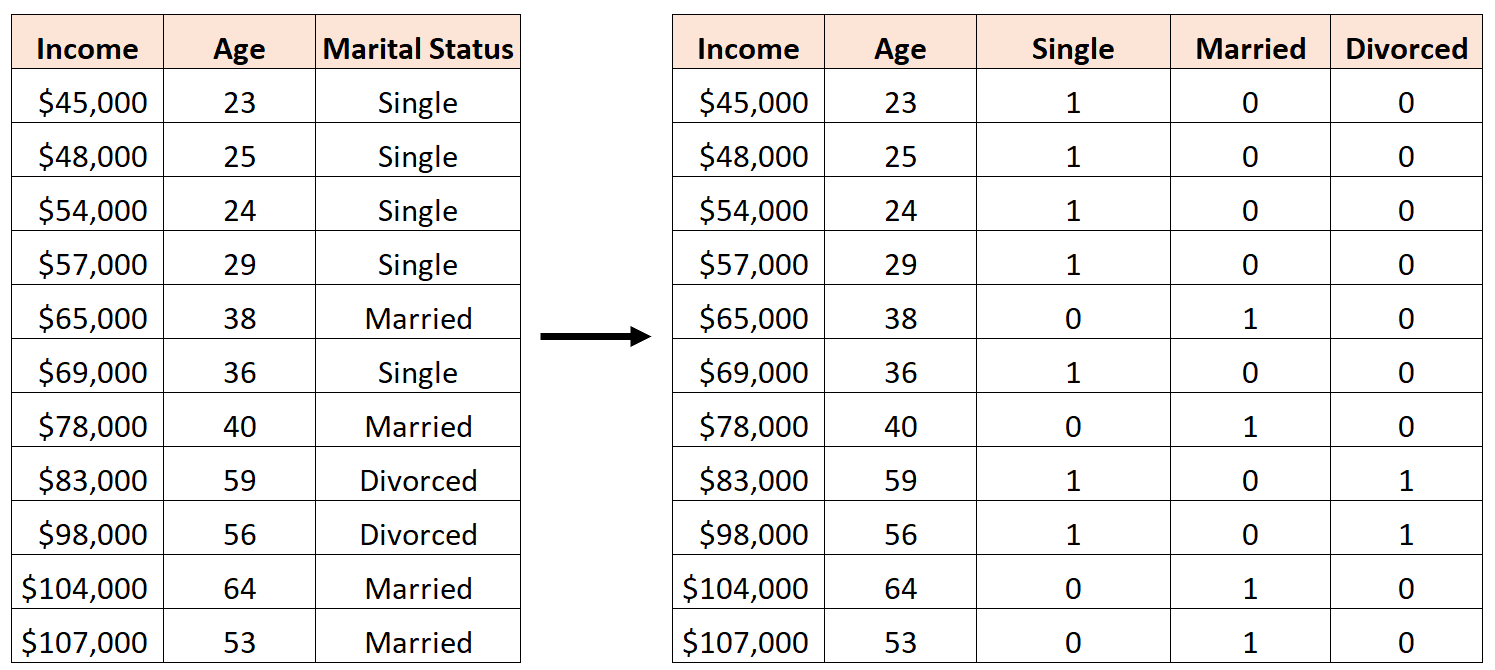
例如,假设我们有以下数据集,并希望使用婚姻状况和年龄来预测收入:

要将婚姻状况用作回归模型中的预测变量,我们需要将其转换为虚拟变量。
由于目前这是一个可以采用三个不同值(“单身”、“已婚”或“离婚”)的分类变量,因此我们需要创建k -1 = 3-1 = 2 个虚拟变量。
要创建这个虚拟变量,我们可以将“Single”保留为基值,因为它最常出现。因此,我们将婚姻状况转换为虚拟变量的方法如下:

然后,我们可以使用Age 、 Married和Divorced作为回归模型中的预测变量。
创建虚拟变量时,可能出现的问题称为虚拟变量陷阱。当我们创建k 个虚拟变量而不是k -1 个虚拟变量时,就会发生这种情况。
当这种情况发生时,至少有两个虚拟变量将遭受完美多重共线性。换句话说,它们将完全相关。这会导致回归系数及其相应 p 值的计算不正确。
虚拟变量陷阱:当创建的虚拟变量的数量等于分类值可以取的值的数量时。这会导致多重共线性,从而导致回归系数和 p 值的计算不正确。
例如,假设我们将婚姻状况转换为以下虚拟变量:
在这种情况下, “单身”和“已婚”完全相关,相关系数为 -1。
所以当我们进行多元线性回归时,回归系数计算将会不正确。
如何避免虚拟变量陷阱
您只需要记住一条规则即可避免陷入虚拟变量的陷阱:
如果分类变量可以采用k 个不同的值,则您应该只创建k-1 个虚拟变量以在回归模型中使用。
例如,假设您想要将分类变量“学年”转换为虚拟变量。假设该变量采用以下值:
- 一年级学生
- 二年级学生
- 初级
- 高级的
由于该变量可以采用 4 个不同的值,因此我们将仅创建 3 个虚拟变量。例如,我们的虚拟变量可以是:
- 如果是二年级学生, X 1 = 1;否则为 0
- 如果是初级,则X 2 = 1;否则为 0
- X 3 = 1 颗高级红豆杉;否则为 0
由于虚拟变量的数量比“学年”可以取的值的数量少1,因此我们可以避免虚拟变量陷阱和多重共线性问题。
其他资源
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多