如何在sas中使用proc cluster(附示例)
聚类是一种机器学习技术,尝试在数据集中查找观察组。
目标是找到聚类,使得每个聚类内的观察结果彼此非常相似,而不同聚类中的观察结果彼此非常不同。
在 SAS 中进行聚类的最简单方法是使用PROC CLUSTER 。
以下示例展示了如何在实践中使用PROC CLUSTER 。
示例:如何在 SAS 中使用 PROC CLUSTER
假设我们有以下数据集,其中包含 20 名不同篮球运动员的得分、助攻和篮板信息:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
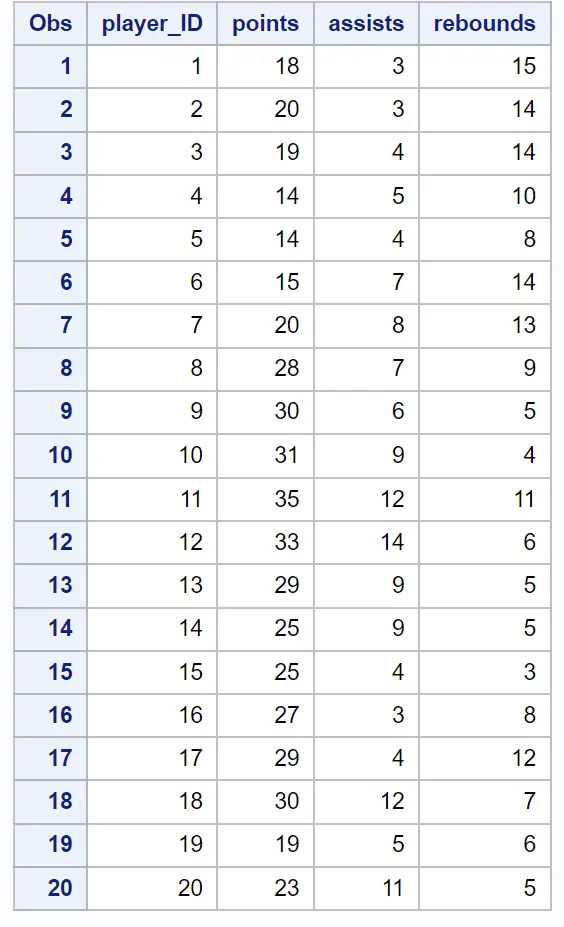
假设我们想要进行一些分组,以尝试识别具有相似统计数据的玩家“集群”。
以下代码展示了如何使用SAS中的PROC CLUSTER进行聚类:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
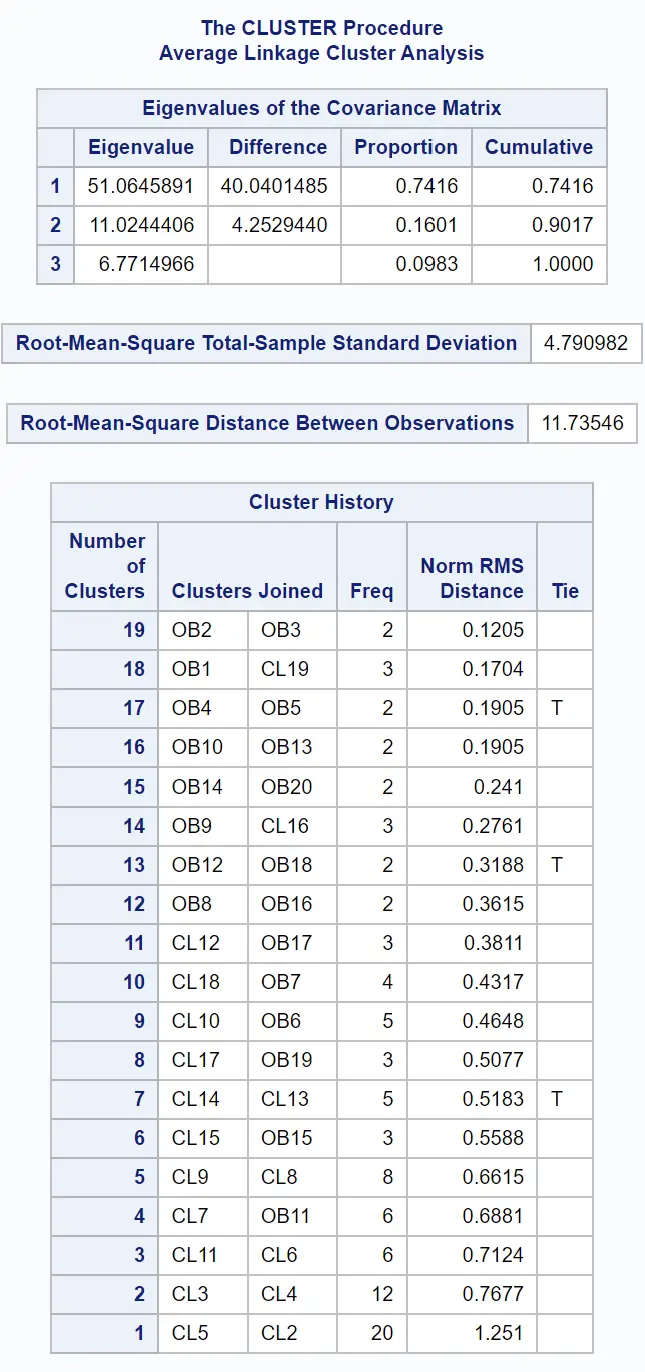
结果的第一个表提供了有关如何进行聚类的信息:
还生成了树状图,以便我们可以直观地检查数据集中观测值之间的相似性:
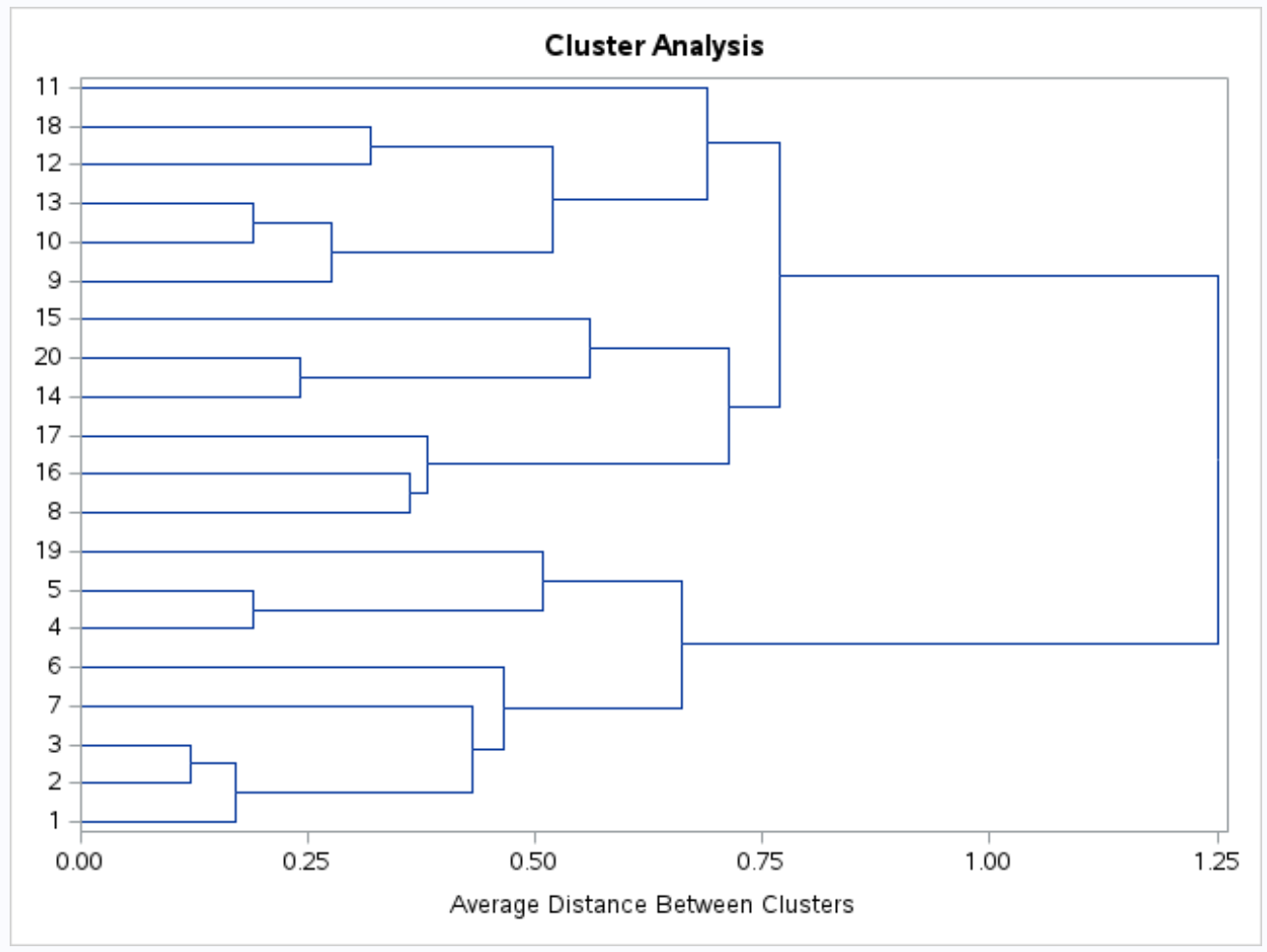
y 轴显示单个观测值,x 轴显示簇之间的平均距离。
看看这个树状图,观察结果似乎自然分为三组:
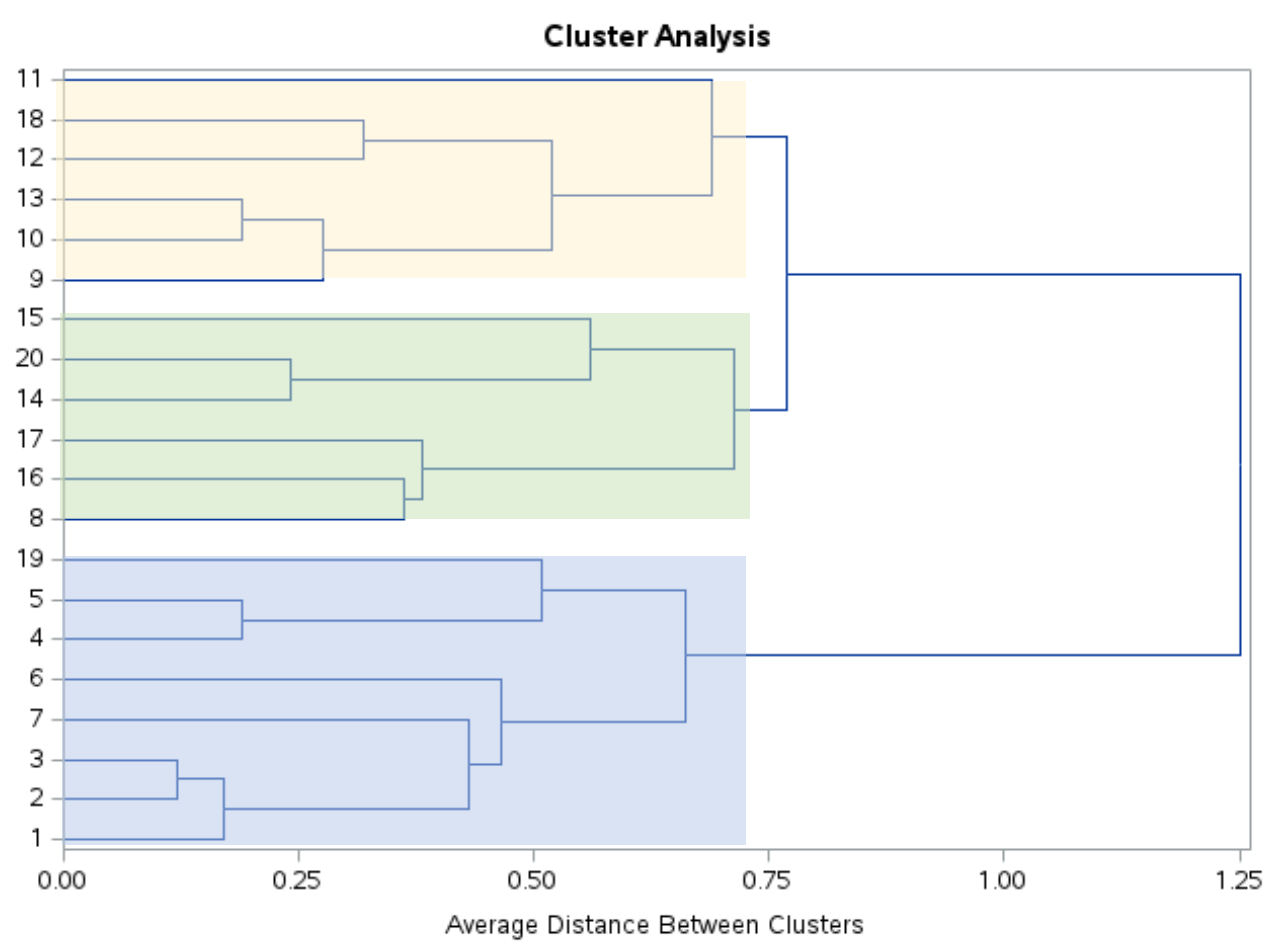
然后,我们可以使用ncl=3的PROC TREE语句来告诉 SAS 将原始数据集中的每个观测值分配给三个集群之一:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
生成的数据集显示每个原始观测值及其所属的簇:
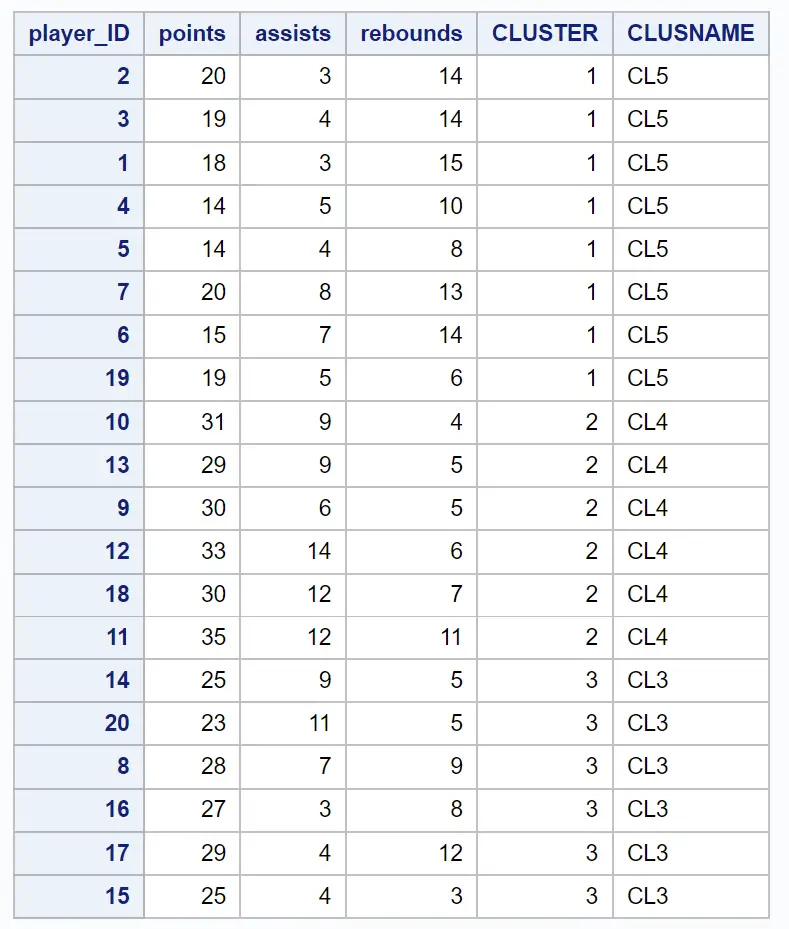
例如,我们可以看到: ID为2、3、1、4、5、7、6和19的玩家都属于集群1 。
这告诉我们,这八名球员在得分、助攻和篮板方面的变量是“相似的”。
注意:对于此示例,我们选择使用平均作为聚类的链接方法。有关可以使用的其他绑定方法的完整列表,请参阅SAS 文档。
其他资源
以下教程解释了如何在 SAS 中执行其他常见任务:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多