Pandas:如何在读取 excel 文件时跳行
将 Excel 文件读入 pandas DataFrame 时,可以使用以下方法跳过行:
方法一:跳过特定行
#import DataFrame and skip row in index position 2 df = pd. read_excel (' my_data.xlsx ', skiprows=[ 2 ])
方法 2:忽略多个特定行
#import DataFrame and skip rows in index positions 2 and 4 df = pd. read_excel (' my_data.xlsx ' , skiprows=[2,4 ] )
方法3:忽略前N行
#import DataFrame and skip first 2 rows df = pd. read_excel (' my_data.xlsx ', skiprows= 2 )
以下示例展示了如何在实践中使用以下名为player_data.xlsx的 Excel 文件使用每种方法:
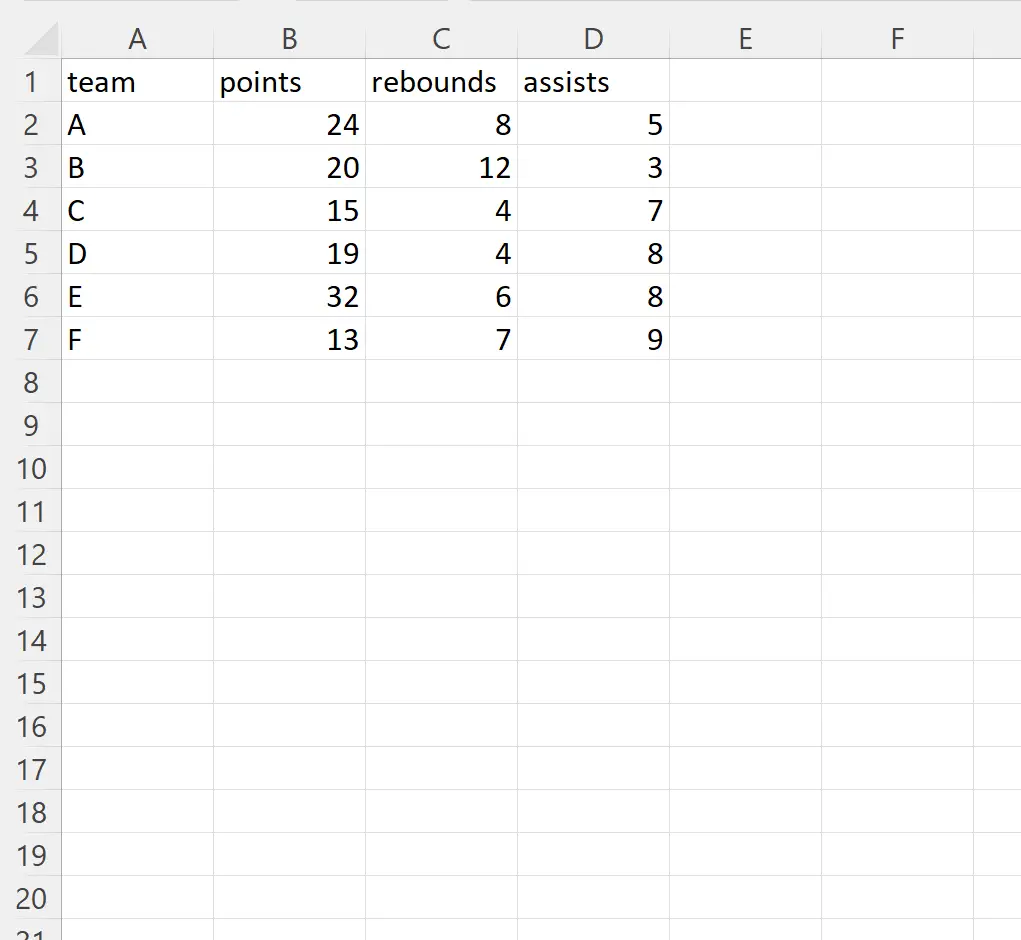
示例 1:忽略特定行
我们可以使用以下代码导入Excel文件并忽略索引位置2处的行:
import pandas as pd #import DataFrame and skip row in index position 2 df = pd. read_excel (' player_data.xlsx ', skiprows=[ 2 ]) #view DataFrame print (df) team points rebound assists 0 to 24 8 5 1 C 15 4 7 2 D 19 4 8 3 E 32 6 8 4 F 13 7 9
请注意,将 Excel 文件导入 pandas DataFrame 时,索引位置 2 处的行(团队“B”)被忽略。
注意:Excel 文件的第一行被视为第 0 行。
示例 2:忽略多个特定行
我们可以使用以下代码导入Excel文件并忽略索引位置2和4中的行:
import pandas as pd #import DataFrame and skip rows in index positions 2 and 4 df = pd. read_excel (' player_data.xlsx ', skiprows=[ 2,4 ] ) #view DataFrame print (df) team points rebound assists 0 to 24 8 5 1 C 15 4 7 2 E 32 6 8 3 F 13 7 9
请注意,将 Excel 文件导入 pandas DataFrame 时,索引位置 2 和 4 中的行(包含“B”和“D”组)被忽略。
示例 3:忽略前 N 行
我们可以使用以下代码导入Excel文件并忽略前两行:
import pandas as pd #import DataFrame and skip first 2 rows df = pd. read_excel (' player_data.xlsx ', skiprows= 2 ) #view DataFrame print (df) B 20 12 3 0 C 15 4 7 1 D 19 4 8 2 E 32 6 8 3 F 13 7 9
请注意,Excel 文件的前两行已被跳过,下一个可用行(团队“B”)已成为 DataFrame 的标题行。
其他资源
以下教程解释了如何在 Python 中执行其他常见任务:
如何使用 Pandas 读取 Excel 文件
如何将 Pandas DataFrame 导出到 Excel
如何将 NumPy 数组导出到 CSV 文件
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多