如何在 python 中执行单变量分析:带有示例
术语单变量分析是指对一个变量的分析。你可以记住这一点,因为前缀“uni”的意思是“一个”。
对变量进行单变量分析有以下三种常见方法:
1. 汇总统计——测量值的中心和分布。
2. 频率表——描述不同值出现的频率。
3. 图表– 用于可视化值的分布。
本教程提供了如何使用以下 pandas DataFrame 执行单变量分析的示例:
import pandas as pd #createDataFrame df = pd. DataFrame ({' points ': [1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2], ' assists ': [5, 7, 7, 9, 12, 9, 9, 4, 6, 8, 8, 9, 3, 2, 6], ' rebounds ': [11, 8, 10, 6, 6, 5, 9, 12, 6, 6, 7, 8, 7, 9, 15]}) #view first five rows of DataFrame df. head () points assists rebounds 0 1.0 5 11 1 1.0 7 8 2 2.0 7 10 3 3.5 9 6 4 4.0 12 6
1. 计算汇总统计量
我们可以使用以下语法来计算 DataFrame 中“points”变量的各种汇总统计数据:
#calculate mean of 'points' df[' points ']. mean () 5.706666666666667 #calculate median of 'points' df[' points ']. median () 5.0 #calculate standard deviation of 'points' df[' points ']. std () 3.858287308169384
2. 创建频数表
我们可以使用以下语法为变量“points”创建频率表:
#create frequency table for 'points' df[' points ']. value_counts () 4.0 3 1.0 2 5.0 2 2.0 1 3.5 1 6.5 1 7.0 1 7.4 1 8.0 1 13.0 1 14.2 1 Name: points, dtype: int64
这告诉我们:
- 值4出现 3 次
- 值1出现两次
- 值5出现两次
- 值2出现 1 次
等等。
3. 创建图表
我们可以使用以下语法为“points”变量创建箱线图:
import matplotlib. pyplot as plt df. boxplot (column=[' points '], grid= False , color=' black ')
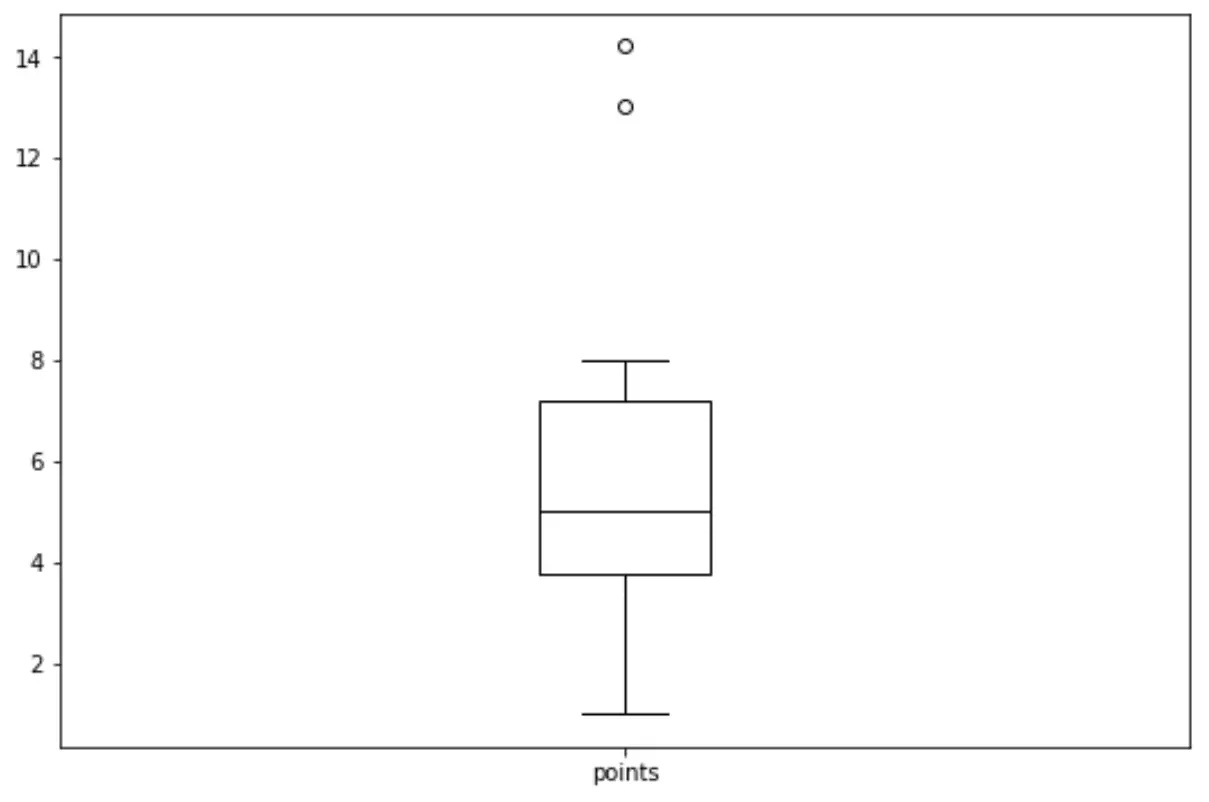
我们可以使用以下语法为“points”变量创建直方图:
import matplotlib. pyplot as plt df. hist (column=' points ', grid= False , edgecolor=' black ')
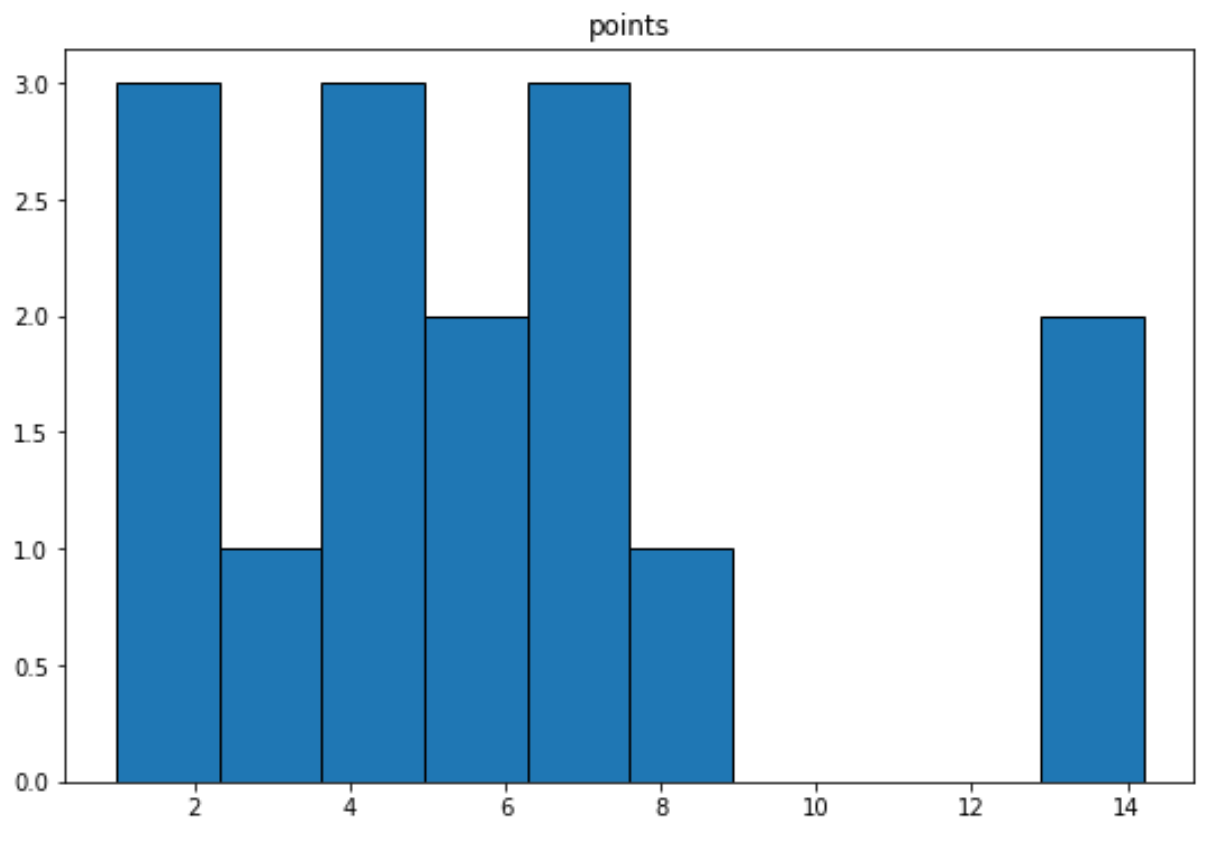
我们可以使用以下语法为“points”变量创建密度曲线:
import seaborn as sns sns. kdeplot (df[' points '])
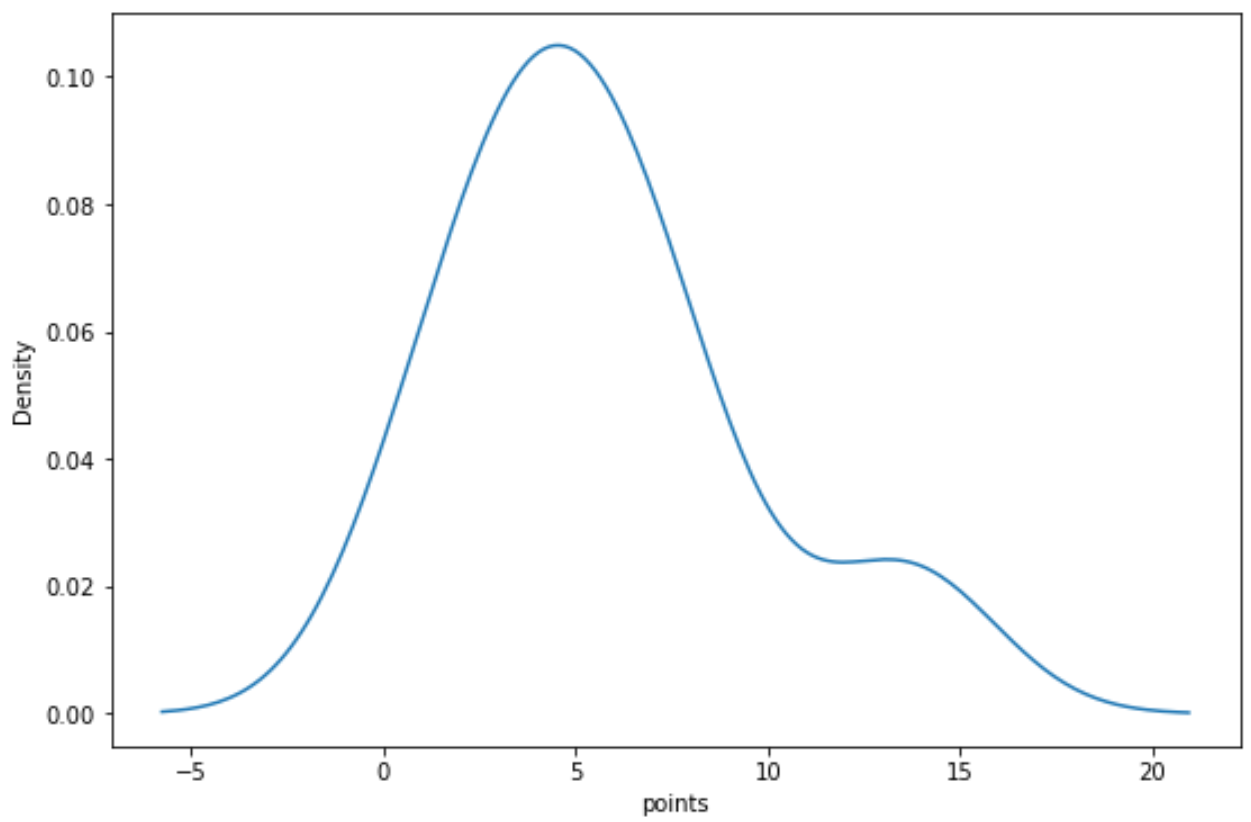
这些图表中的每一个都为我们提供了一种独特的方式来可视化“点”变量值的分布。
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多