如何在 python 中执行 kpss 测试
KPSS 检验可用于确定时间序列是否具有平稳趋势。
该检验使用以下原假设和备择假设:
- H 0 :时间序列具有平稳趋势。
- H A :时间序列没有固定趋势。
如果检验的p 值低于一定的显着性水平(例如 α = 0.05),则我们拒绝原假设并得出时间序列不具有平稳趋势的结论。
否则,我们将无法拒绝原假设。
以下示例展示了如何在 Python 中执行 KPSS 测试。
示例 1:Python 中的 KPSS 测试(使用平稳数据)
首先,让我们在 Python 中创建一些要使用的假数据:
import numpy as np
import matplotlib. pyplot as plt
#make this example reproducible
n.p. random . seed ( 1 )
#create time series data
data = np. random . normal (size= 100 )
#create line plot of time series data
plt. plot (data)
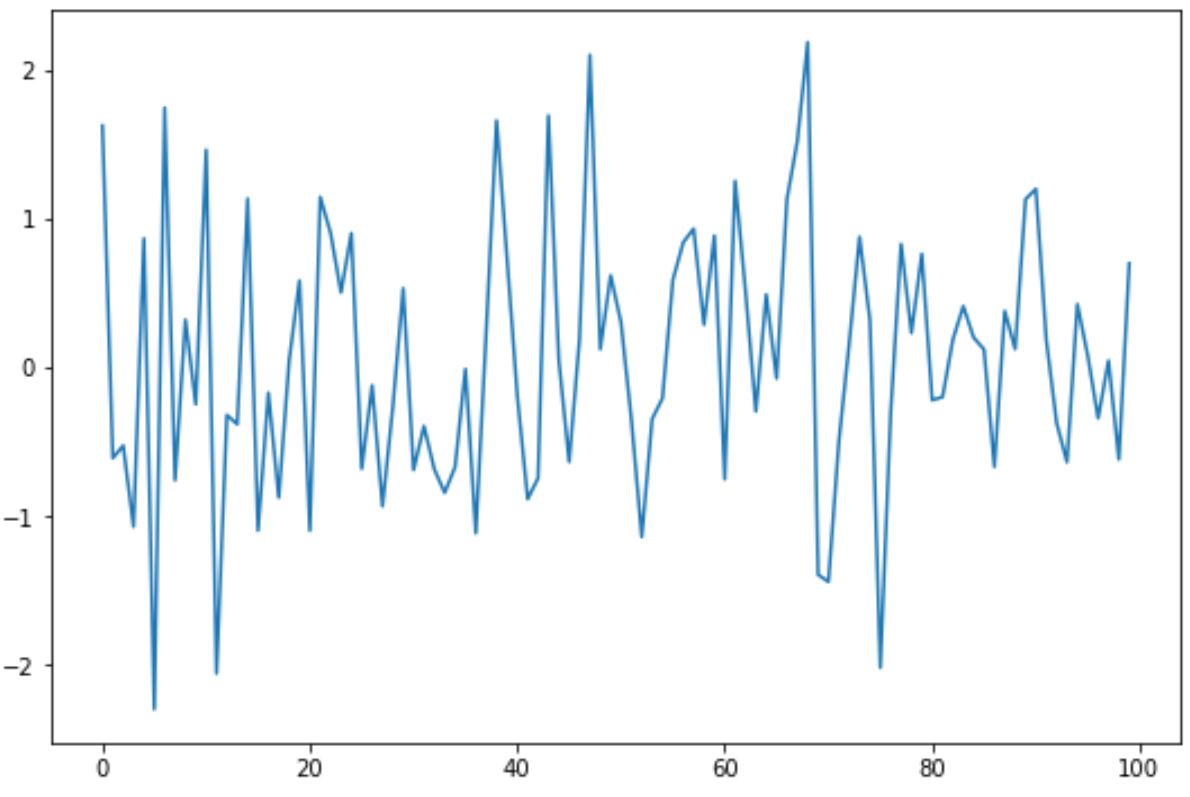
我们可以使用statsmodels包中的kpss()函数对此时间序列数据执行 KPSS 测试:
import statsmodels. api as sm
#perform KPSS test
sm. tsa . stattools . kpss (data, regression=' ct ')
(0.0477617848370993,
0.1,
1,
{'10%': 0.119, '5%': 0.146, '2.5%': 0.176, '1%': 0.216})
InterpolationWarning: The test statistic is outside of the range of p-values available
in the look-up table. The actual p-value is greater than the p-value returned.
以下是如何解释结果:
- KPSS 检验统计量: 0.04776
- p 值: 0.1
- 截断偏移参数: 1
- 10% 、 5% 、 2.5%和1%的临界值
p 值为0.1 。由于该值不小于0.05,因此我们无法拒绝KPSS检验的原假设。
这意味着我们可以假设时间序列具有平稳趋势。
注 1 :p 值实际上仍然大于 0.1,但 kpss() 函数产生的最低值是 0.1。
注2 :您必须使用regression=’ct’参数来指定检验的原假设是数据具有平稳趋势。
示例 2:Python 中的 KPSS 测试(使用非平稳数据)
首先,让我们在 Python 中创建一些要使用的假数据:
import numpy as np
import matplotlib. pyplot as plt
#make this example reproducible
n.p. random . seed ( 1 )
#create time series data
data =np. array ([0, 3, 4, 3, 6, 7, 5, 8, 15, 13, 19, 12, 29, 15, 45, 23, 67, 45])
#create line plot of time series data
plt. plot (data)
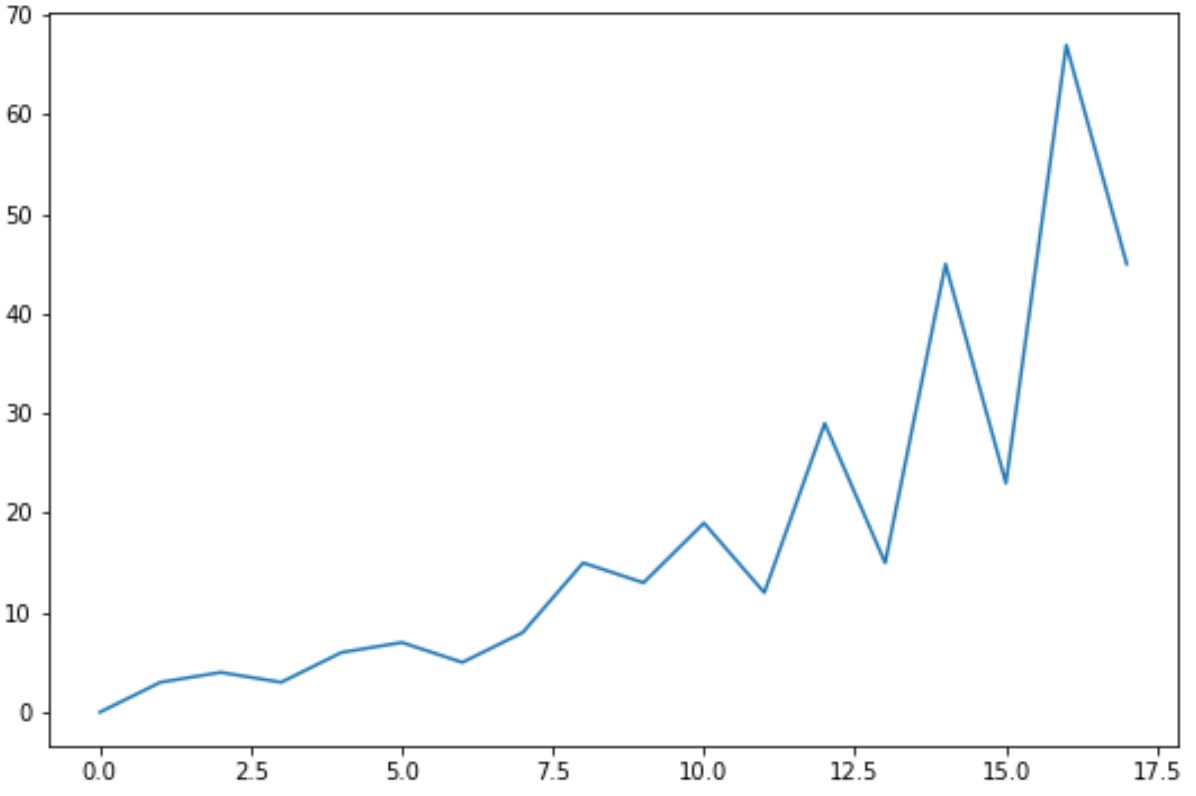
同样,我们可以使用statsmodels包中的kpss()函数对此时间序列数据执行 KPSS 测试:
import statsmodels. api as sm
#perform KPSS test
sm. tsa . stattools . kpss (data, regression=' ct ')
(0.15096358910843685,
0.04586367574296928,
3,
{'10%': 0.119, '5%': 0.146, '2.5%': 0.176, '1%': 0.216})
以下是如何解释结果:
- KPSS 检验统计量: 0.1509
- p 值: 0.0458
- 截断偏移参数: 3
- 10% 、 5% 、 2.5%和1%的临界值
p 值为0.0458 。该值小于 0.05,我们拒绝 KPSS 检验的原假设。
这意味着时间序列不是平稳的。
注意:您可以在此处的statsmodels 包中找到 kpss() 函数的完整文档。
其他资源
以下教程提供了有关如何在 Python 中使用时间序列数据的更多信息:
如何在 Python 中执行增强的 Dickey-Fuller 测试
如何使用 Python 执行 Mann-Kendall 趋势检验
如何在 Matplotlib 中绘制时间序列
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多