如何在 python 中执行标签编码(带有示例)
在机器学习中,我们通常希望将分类变量转换为某种类型的数字格式,以便算法可以轻松使用。
实现此目的的一种方法是使用标签编码,它根据字母顺序为每个分类值分配一个整数值。
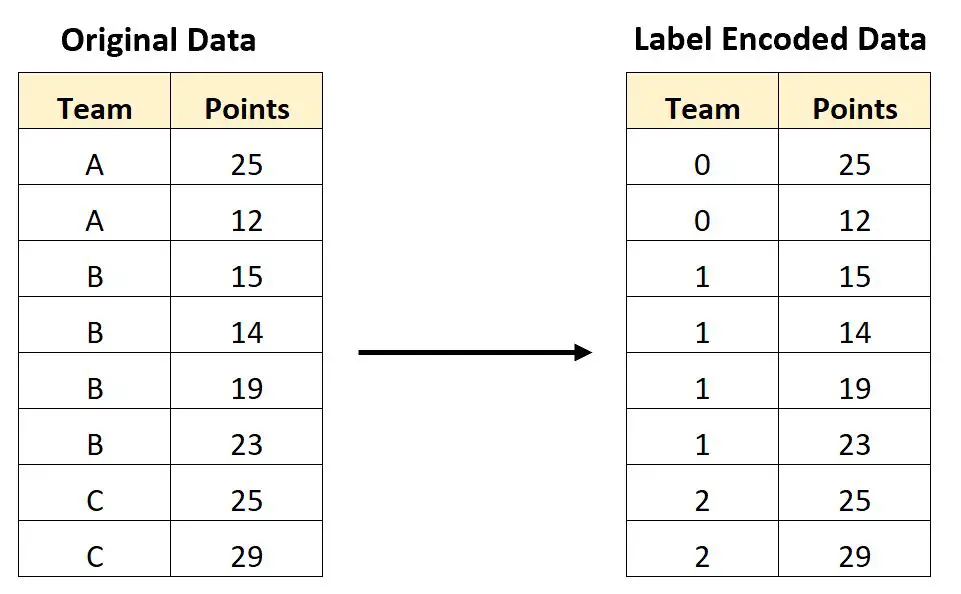
例如,以下屏幕截图显示了如何将名为Team的分类变量的每个唯一值转换为基于字母顺序的整数值:
您可以使用以下语法在Python中执行标签编码:
from sklearn. preprocessing import LabelEncoder #create instance of label encoder lab = LabelEncoder() #perform label encoding on 'team' column df[' my_column '] = lab. fit_transform (df[' my_column '])
以下示例展示了如何在实践中使用此语法。
示例:在 Python 中编码标签
假设我们有以下 pandas DataFrame:
import pandas as pd
#createDataFrame
df = pd. DataFrame ({' team ': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'],
' points ': [25, 12, 15, 14, 19, 23, 25, 29]})
#view DataFrame
print (df)
team points
0 to 25
1 to 12
2 B 15
3 B 14
4 B 19
5 B 23
6 C 25
7 C 29
我们可以使用以下代码进行标签编码,将team列中的每个分类值转换为整数值:
from sklearn. preprocessing import LabelEncoder #create instance of label encoder lab = LabelEncoder() #perform label encoding on 'team' column df[' team '] = lab. fit_transform (df[' team ']) #view updated DataFrame print (df) team points 0 0 25 1 0 12 2 1 15 3 1 14 4 1 19 5 1 23 6 2 25 7 2 29
从结果我们可以看出:
- 每个“A”值已转换为0 。
- 每个“B”值已转换为1 。
- 每个“C”值都转换为2 。
请注意,您还可以使用inverse_transform()函数来获取team列的原始值:
#display original team labels lab. inverse_transform (df[' team ']) array(['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'], dtype=object)
其他资源
以下教程解释了如何在 Python 中执行其他常见任务:
如何在 Pandas 中将分类变量转换为数值
如何在 Pandas 中将布尔值转换为整数值
如何使用 Factorize() 将字符串编码为 Pandas 中的数字
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多