如何在 python 中执行简单的线性回归(逐步)
简单线性回归是一种我们可以用来理解单个解释变量和单个响应变量之间关系的技术。
该技术找到一条最“适合”数据的线,并采用以下形式:
ŷ = b 0 + b 1 x
金子:
- ŷ : 估计响应值
- b 0 :回归线的原点
- b 1 :回归线的斜率
该方程可以帮助我们理解解释变量和响应变量之间的关系,并且(假设它具有统计显着性)它可以用于在给定解释变量值的情况下预测响应变量的值。
本教程提供有关如何在 Python 中执行简单线性回归的分步说明。
第 1 步:加载数据
对于此示例,我们将为 15 名学生创建一个包含以下两个变量的假数据集:
- 某些考试的学习总小时数
- 考试成绩
我们将尝试使用小时数作为解释变量、检查结果作为响应变量来拟合一个简单的线性回归模型。
以下代码展示了如何在 Python 中创建这个假数据集:
import pandas as pd #create dataset df = pd. DataFrame ({' hours ': [1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14], ' score ': [64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89]}) #view first six rows of dataset df[0:6] hours score 0 1 64 1 2 66 2 4 76 3 5 73 4 5 74 5 6 81
第 2 步:可视化数据
在拟合简单的线性回归模型之前,我们必须首先将数据可视化以理解它。
首先,我们要确保小时数和分数之间的关系近似线性,因为这是简单线性回归的 基本假设。
我们可以创建一个简单的散点图来可视化两个变量之间的关系:
import matplotlib.pyplot as plt plt. scatter (df.hours, df.score) plt. title (' Hours studied vs. Exam Score ') plt. xlabel (' Hours ') plt. ylabel (' Score ') plt. show ()
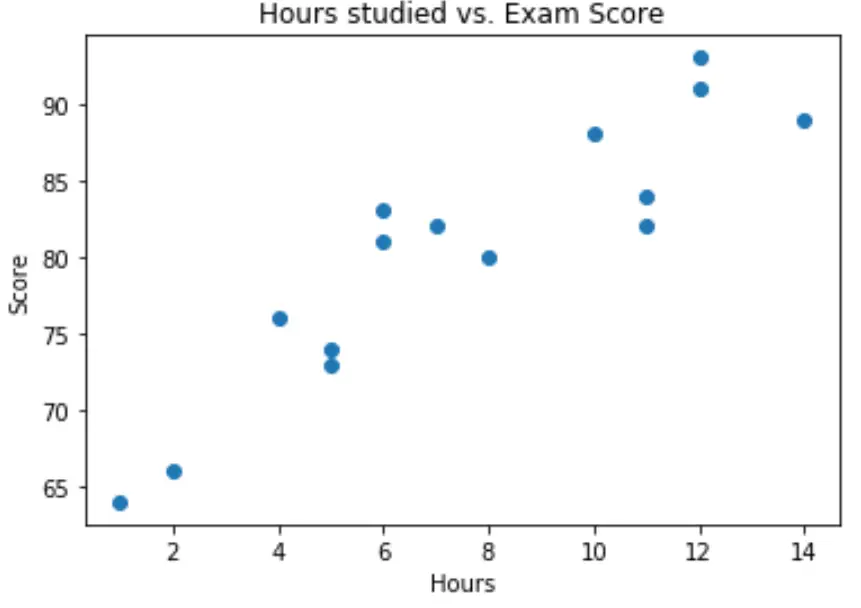
从图中我们可以看出,这种关系似乎是线性的。随着小时数的增加,分数也趋于线性增加。
然后我们可以创建一个箱线图来可视化考试结果的分布并检查异常值。默认情况下,如果某个观测值是第三个四分位 (Q3) 上方四分位距的 1.5 倍或第一个四分位 (Q1) 下方四分位距的 1.5 倍,则 Python 将其定义为离群值。
如果观察值异常,箱线图中会出现一个小圆圈:
df. boxplot (column=[' score '])
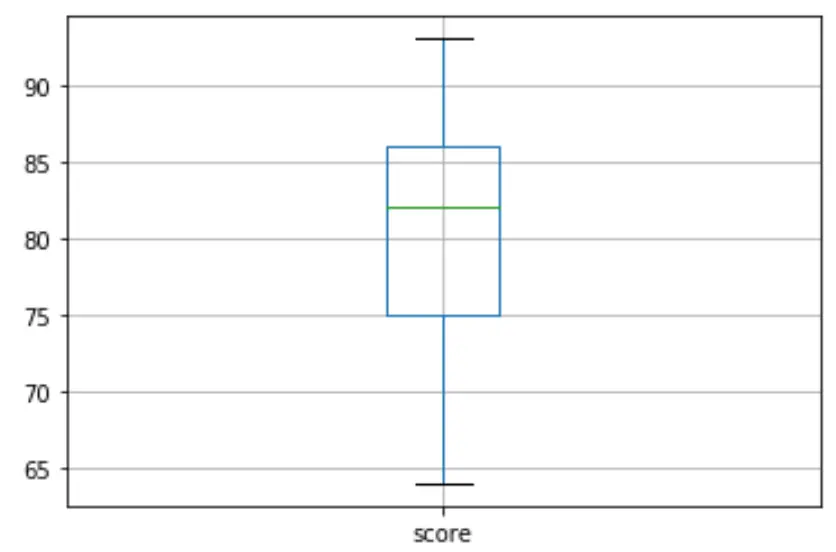
箱线图中没有小圆圈,这意味着我们的数据集中没有异常值。
步骤 3:执行简单的线性回归
一旦我们确认变量之间的关系是线性的并且不存在异常值,我们就可以继续使用小时作为解释变量和分数作为响应变量来拟合一个简单的线性回归模型:
注意:我们将使用statsmodels 库中的OLS() 函数来拟合回归模型。
import statsmodels.api as sm #define response variable y = df[' score '] #define explanatory variable x = df[[' hours ']] #add constant to predictor variables x = sm. add_constant (x) #fit linear regression model model = sm. OLS (y,x). fit () #view model summary print ( model.summary ()) OLS Regression Results ==================================================== ============================ Dept. Variable: R-squared score: 0.831 Model: OLS Adj. R-squared: 0.818 Method: Least Squares F-statistic: 63.91 Date: Mon, 26 Oct 2020 Prob (F-statistic): 2.25e-06 Time: 15:51:45 Log-Likelihood: -39,594 No. Observations: 15 AIC: 83.19 Df Residuals: 13 BIC: 84.60 Model: 1 Covariance Type: non-robust ==================================================== ============================ coef std err t P>|t| [0.025 0.975] -------------------------------------------------- ---------------------------- const 65.3340 2.106 31.023 0.000 60.784 69.884 hours 1.9824 0.248 7.995 0.000 1.447 2.518 ==================================================== ============================ Omnibus: 4,351 Durbin-Watson: 1,677 Prob(Omnibus): 0.114 Jarque-Bera (JB): 1.329 Skew: 0.092 Prob(JB): 0.515 Kurtosis: 1.554 Cond. No. 19.2 ==================================================== ============================
从模型总结中我们可以看出,拟合的回归方程为:
分数 = 65.334 + 1.9824*(小时)
这意味着每多学习一小时,平均考试成绩就会增加1.9824分。原始值65,334告诉我们零学习时间的学生的平均预期考试成绩。
我们还可以使用这个方程根据学生学习的小时数找到预期的考试成绩。例如,学习 10 小时的学生应获得85.158的考试成绩:
分数 = 65.334 + 1.9824*(10) = 85.158
以下是如何解释模型摘要的其余部分:
- P>|t| :这是与模型系数相关的 p 值。由于小时数的 p 值 (0.000) 显着小于 0.05,因此我们可以说小时数和分数之间存在统计上显着的关联。
- R 平方:这个数字告诉我们,考试成绩的变化百分比可以用学习的小时数来解释。一般来说,回归模型的 R 平方值越大,解释变量越能预测响应变量的值。在这种情况下, 83.1%的分数差异可以用学习时间来解释。
- F 统计量和 p 值: F 统计量 ( 63.91 ) 和相应的 p 值 ( 2.25e-06 ) 告诉我们回归模型的整体显着性,即模型中的解释变量是否有助于解释变异。在响应变量中。由于此示例中的 p 值小于 0.05,因此我们的模型具有统计显着性,并且小时数被认为有助于解释分数变化。
第 4 步:创建残差图
将简单线性回归模型拟合到数据后,最后一步是创建残差图。
线性回归的关键假设之一是回归模型的残差近似正态分布,并且在解释变量的每个水平上都是同方差的。如果不满足这些假设,我们的回归模型的结果可能会产生误导或不可靠。
为了验证是否满足这些假设,我们可以创建以下残差图:
残差与拟合值图:该图对于确认同方差性很有用。 x 轴显示拟合值,y 轴显示残差。只要残差看起来在零值周围随机且均匀地分布在整个图中,我们就可以假设不违反同方差性:
#define figure size fig = plt. figure (figsize=(12.8)) #produce residual plots fig = sm.graphics. plot_regress_exog (model, ' hours ', fig=fig)
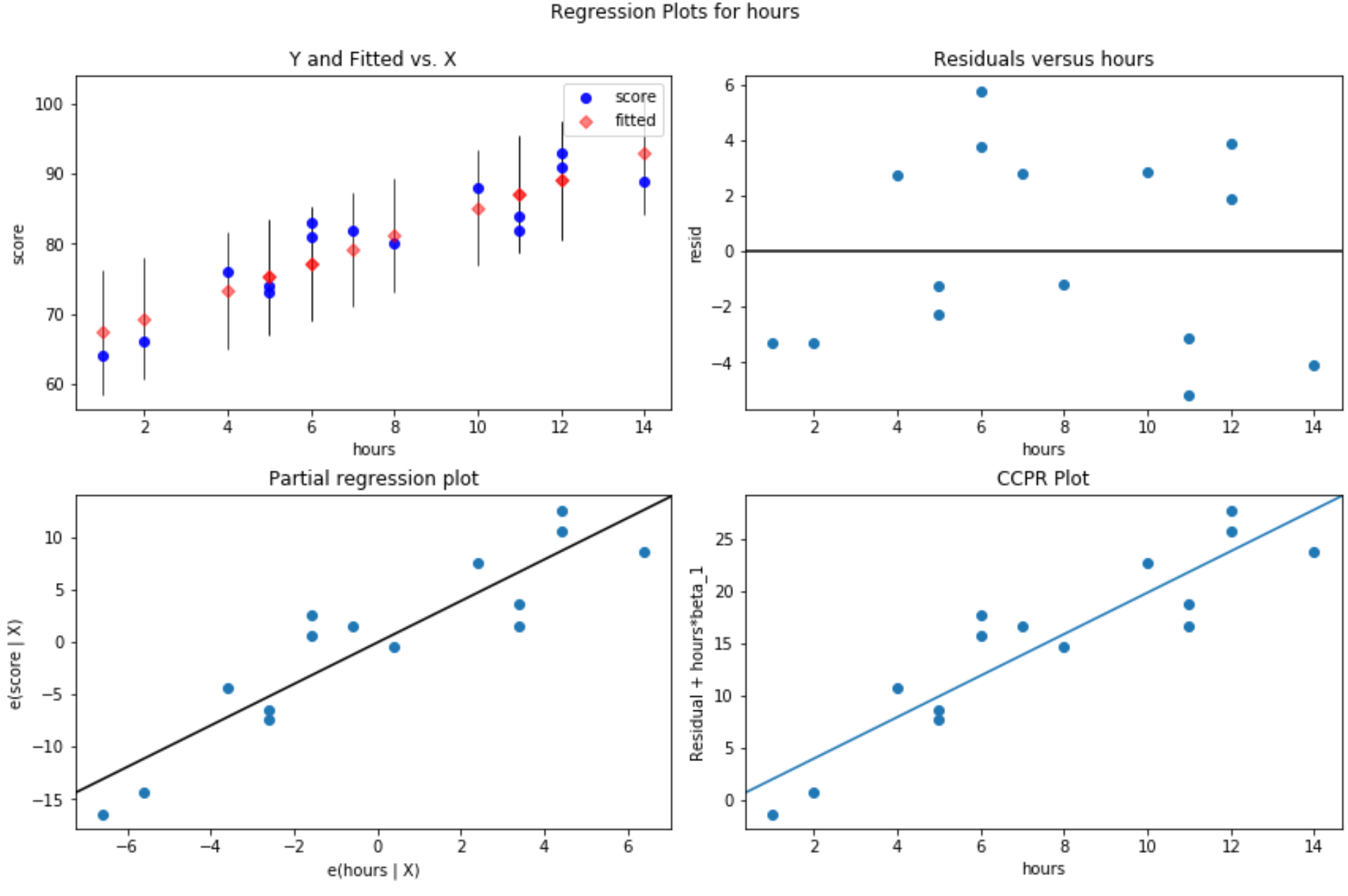
产生了四个地块。右上角的是残差图与调整后的图。该图上的 x 轴显示预测变量点的实际值,y 轴显示该值的残差。
由于残差似乎随机分散在零附近,这表明异方差性不是解释变量的问题。
QQ 图:该图可用于确定残差是否服从正态分布。如果图中的数据值大致呈 45 度角直线分布,则数据呈正态分布:
#define residuals res = model. reside #create QQ plot fig = sm. qqplot (res, fit= True , line=" 45 ") plt.show()
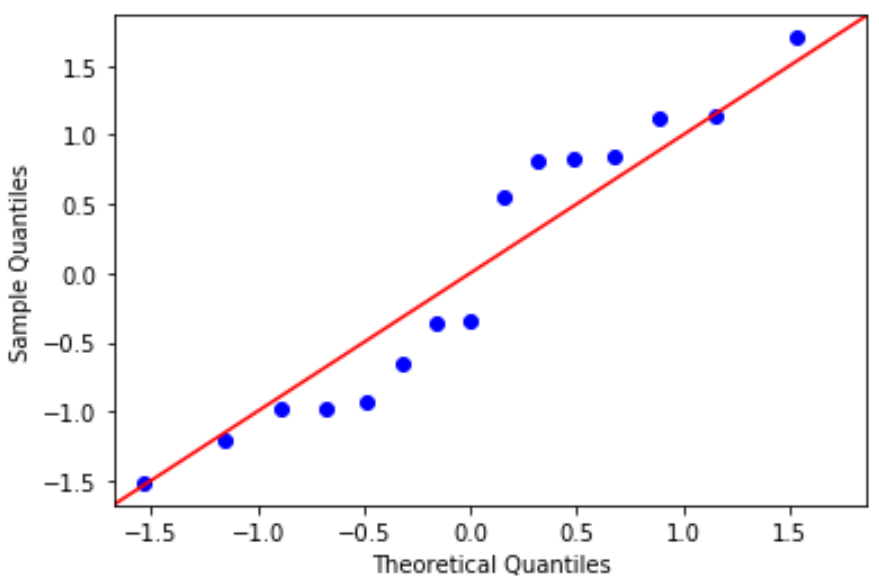
残差稍微偏离 45 度线,但不足以引起严重关注。我们可以假设满足正态性假设。
由于残差呈正态分布且同方差,我们验证了简单线性回归模型的假设得到满足。因此,我们模型的输出是可靠的。
本教程中使用的完整 Python 代码可以在此处找到。
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多