R 中钻石数据集的完整指南
钻石数据集是 R 中ggplot2包中内置的数据集。
它包含 53,940 颗不同钻石的 10 个不同变量(如价格、颜色、净度等)的测量结果。
本教程介绍如何在 R 中探索、总结和可视化钻石数据集。
加载钻石数据集
由于钻石数据集是 ggplot2 中的内置数据集,因此我们首先需要安装(如果尚未安装)并加载 ggplot2 包:
#install ggplot2 if not already installed
install. packages (' ggplot2 ')
#load ggplot2
library (ggplot2)
加载 ggplot2 后,我们可以使用data()函数加载钻石数据集:
data(diamonds)
我们可以使用head()函数查看数据集的前六行:
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price xyz
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
总结钻石数据集
我们可以使用summary()函数快速总结数据集中的每个变量:
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair: 1610 D: 6775 SI1:13065 Min. :43.00
1st Qu.:0.4000 Good: 4906 E: 9797 VS2:12258 1st Qu.:61.00
Median: 0.7000 Very Good: 12082 F: 9542 SI2: 9194 Median: 61.80
Mean: 0.7979 Premium: 13791 G: 11292 VS1: 8171 Mean: 61.75
3rd Qu.:1.0400 Ideal:21551 H:8304 VVS2:5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1: 3655 Max. :79.00
D: 2808 (Other): 2531
table price xyz Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median: 57.00 Median: 2401 Median: 5.700 Median: 5.710 Median: 3.530
Mean: 57.46 Mean: 3933 Mean: 5.731 Mean: 5.735 Mean: 3.539
3rd Qu.: 59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10,740 Max. :58,900 Max. :31,800
对于每个数值变量,我们可以看到以下信息:
- 最小值:最小值。
- 第一个 Qu :第一个四分位数(第 25 个百分位数)的值。
- 中位数:中值。
- 平均值:平均值。
- 第三曲:第三个四分位数(第 75 个百分位数)的值。
- 最大值:最大值。
对于数据集中的分类变量(切工、颜色和净度),我们会看到每个值的频率计数。
例如,对于cut变量:
- Fair :该值出现 1,610 次。
- 好:该值出现 4,906 次。
- 非常好:该值出现了 12,082 次。
- Premium :该值出现 13,791 次。
- 理想:该值出现 21,551 次。
我们可以使用dim()函数获取数据集的行数和列数维度:
#display rows and columns
dim(diamonds)
[1] 53940 10
我们可以看到数据集有53,940行和10列。
我们还可以使用names()函数来显示数据框的列名称:
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] “y” “z”
可视化钻石数据集
我们还可以创建绘图来可视化数据集的值。
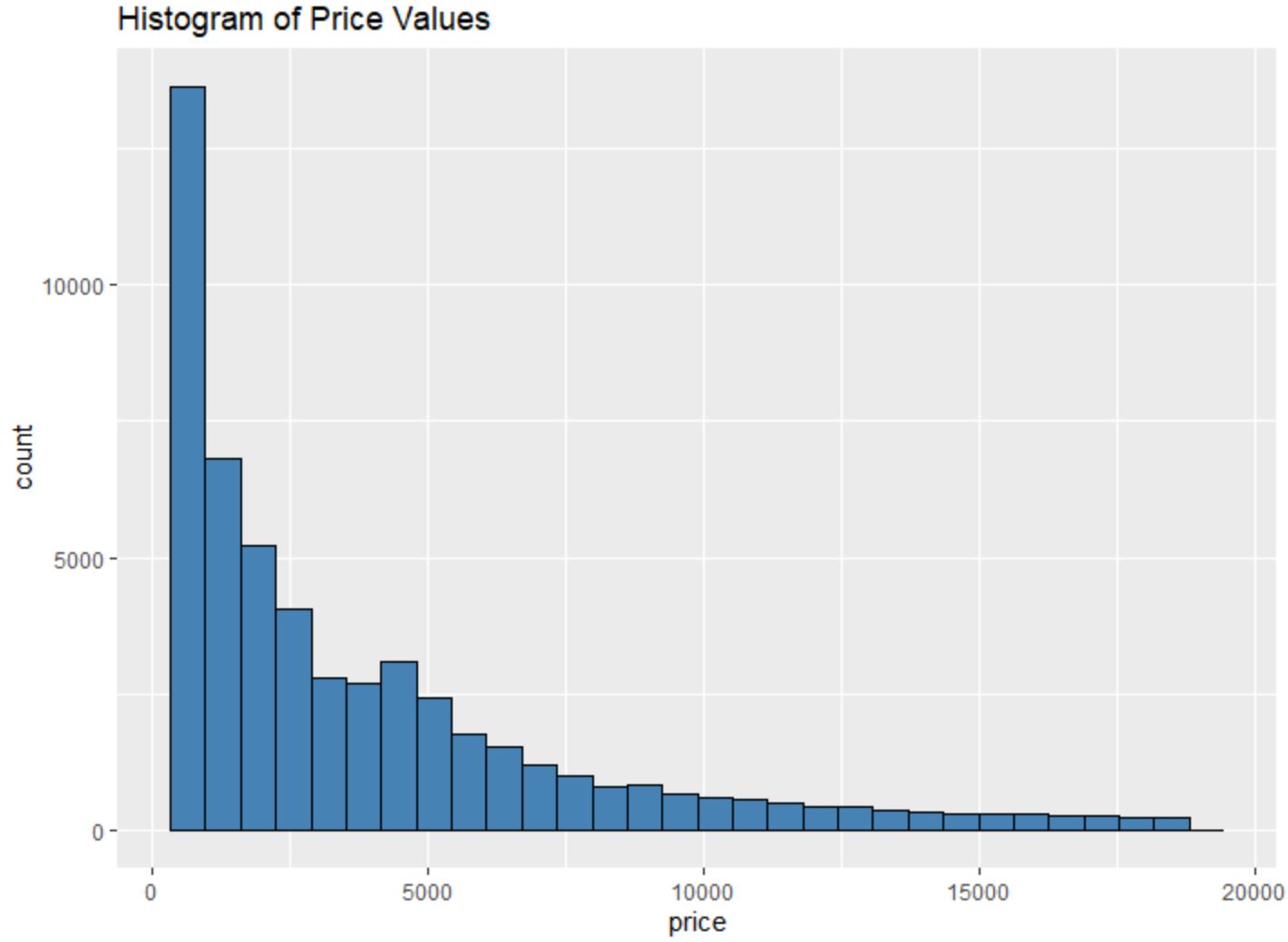
例如,我们可以使用geom_histogram()函数创建某个变量值的直方图:
#create histogram of values for price
ggplot(data=diamonds, aes (x=price)) +
geom_histogram(fill=" steelblue ", color=" black ") +
ggtitle(" Histogram of Price Values ")
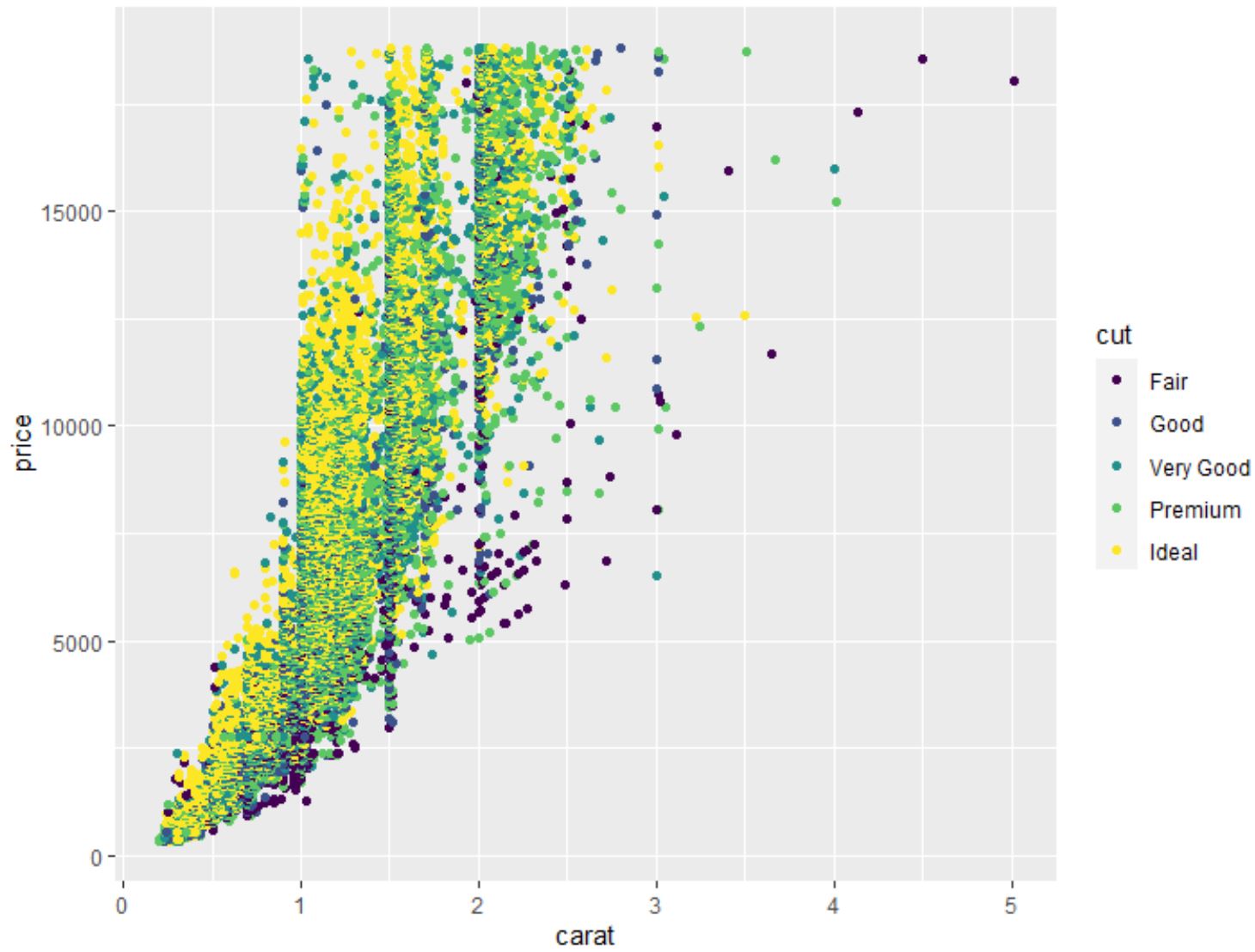
我们还可以使用geom_point()函数创建任意变量成对组合的点云:
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes (x=carat, y=price, color=cut)) +
geom_point()
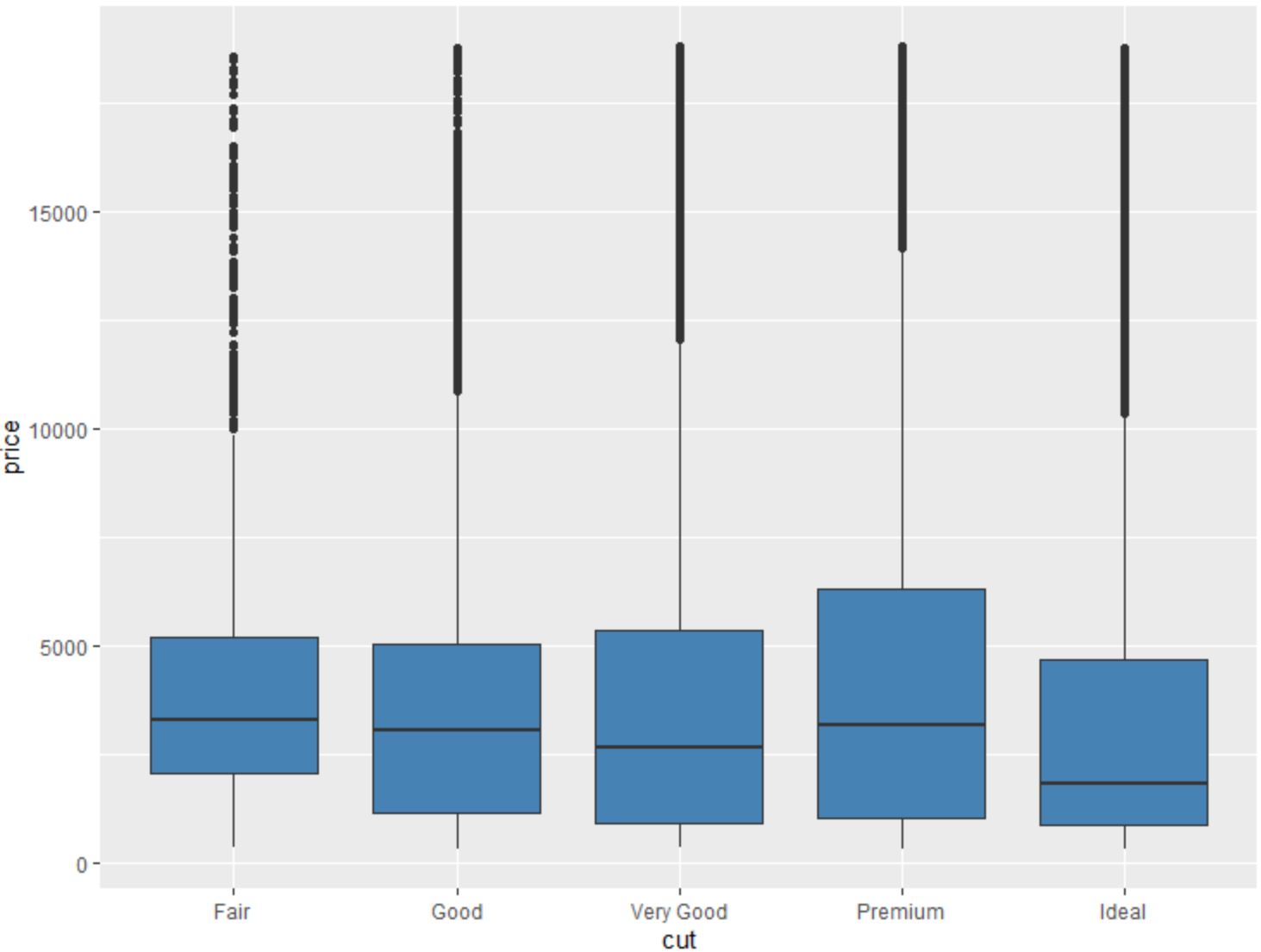
我们还可以使用geom_boxplot()函数创建由另一个变量分组的变量的箱线图:
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes (x=cut, y=price)) +
geom_boxplot(fill=" steelblue ")
使用这些 ggplot2 函数,我们可以了解有关钻石数据集中变量的很多信息。
其他资源
以下教程解释了如何在 R 中探索其他数据集:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多