R 中的偏最小二乘法(一步一步)
机器学习中最常见的问题之一是多重共线性。当数据集中的两个或多个预测变量高度相关时,就会发生这种情况。
发生这种情况时,模型可能能够很好地拟合训练数据集,但它可能在从未见过的新数据集上表现不佳,因为它与训练数据集过度拟合。训练集。
解决这个问题的一种方法是使用一种称为 偏最小二乘法的方法,其工作原理如下:
- 标准化预测变量和响应变量。
- 计算p 个原始预测变量的M 个线性组合(称为“PLS 分量”),这些组合解释了响应变量和预测变量中的大量变化。
- 使用最小二乘法拟合线性回归模型,并使用 PLS 分量作为预测变量。
- 使用k 折交叉验证来找到模型中保留的 PLS 组件的最佳数量。
本教程提供了如何在 R 中执行偏最小二乘法的分步示例。
第1步:加载必要的包
在 R 中执行偏最小二乘的最简单方法是使用pls包中的函数。
#install pls package (if not already installed) install.packages(" pls ") load pls package library(pls)
步骤 2:拟合偏最小二乘模型
在此示例中,我们将使用名为mtcars的内置 R 数据集,其中包含不同类型汽车的数据:
#view first six rows of mtcars dataset
head(mtcars)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3,460 20.22 1 0 3 1
对于此示例,我们将使用hp作为响应变量并使用以下变量作为预测变量来拟合偏最小二乘 (PLS) 模型:
- 英里/加仑
- 展示
- 拉屎
- 重量
- 快秒
以下代码显示了如何使 PLS 模型适合此数据。请注意以下参数:
- scale=TRUE :这告诉 R 数据集中的每个变量都应该缩放为均值 0 和标准差 1。这确保了如果以不同的单位进行测量,则预测变量不会对模型产生太大影响。
- validation=”CV” :这告诉 R 使用k 折交叉验证来评估模型性能。请注意,默认情况下使用 k=10 折叠。另请注意,您可以指定“LOOCV”来代替执行留一交叉验证。
#make this example reproducible set.seed(1) #fit PCR model model <- plsr(hp~mpg+disp+drat+wt+qsec, data=mtcars, scale= TRUE , validation=" CV ")
步骤3:选择PLS组件的数量
一旦我们拟合了模型,我们需要确定要保留多少个 PLS 组件。
为此,只需查看通过 k 交叉验证计算出的测试均方根误差(测试 RMSE):
#view summary of model fitting
summary(model)
Data:
Y dimension: 32 1
Fit method: kernelpls
Number of components considered: 5
VALIDATION: RMSEP
Cross-validated using 10 random segments.
(Intercept) 1 comp 2 comps 3 comps 4 comps 5 comps
CV 69.66 40.57 35.48 36.22 36.74 36.67
adjCV 69.66 40.41 35.12 35.80 36.27 36.20
TRAINING: % variance explained
1 comp 2 comps 3 comps 4 comps 5 comps
X 68.66 89.27 95.82 97.94 100.00
hp 71.84 81.74 82.00 82.02 82.03
结果中有两个有趣的表:
1. 验证:RMSEP
该表告诉我们通过 k 倍交叉验证计算出的 RMSE 检验。我们可以看到以下内容:
- 如果我们在模型中仅使用原始项,则检验的 RMSE 为69.66 。
- 如果我们添加第一个 PLS 分量,RMSE 测试将降至40.57。
- 如果我们添加第二个 PLS 分量,RMSE 测试将降至35.48。
我们可以看到,添加额外的 PLS 组件实际上会导致测试的 RMSE 增加。因此,看来在最终模型中仅使用两个 PLS 组件是最佳选择。
2. 训练:解释方差百分比
该表告诉我们 PLS 分量解释的响应变量的方差百分比。我们可以看到以下内容:
- 仅使用第一个 PLS 分量,我们可以解释响应变量中68.66%的变异。
- 通过添加第二个 PLS 分量,我们可以解释响应变量中89.27%的变异。
请注意,我们仍然能够通过使用更多的 PLS 分量来解释更多的方差,但我们可以看到,添加两个以上的 PLS 分量实际上并不会增加太多解释的方差百分比。
我们还可以使用validationplot()函数将RMSE测试(以及MSE和R平方测试)可视化为PLS分量数量的函数。
#visualize cross-validation plots validationplot(model) validationplot(model, val.type=" MSEP ") validationplot(model, val.type=" R2 ")
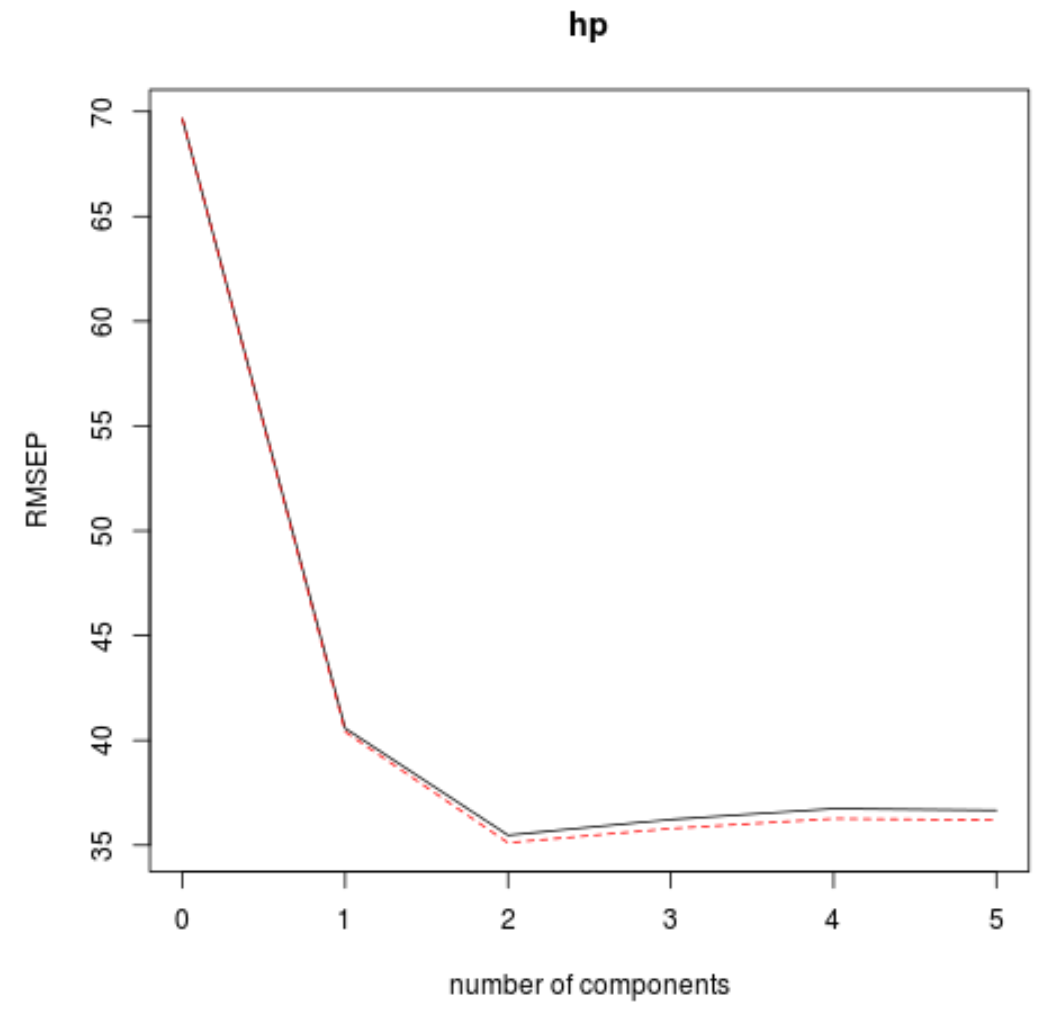
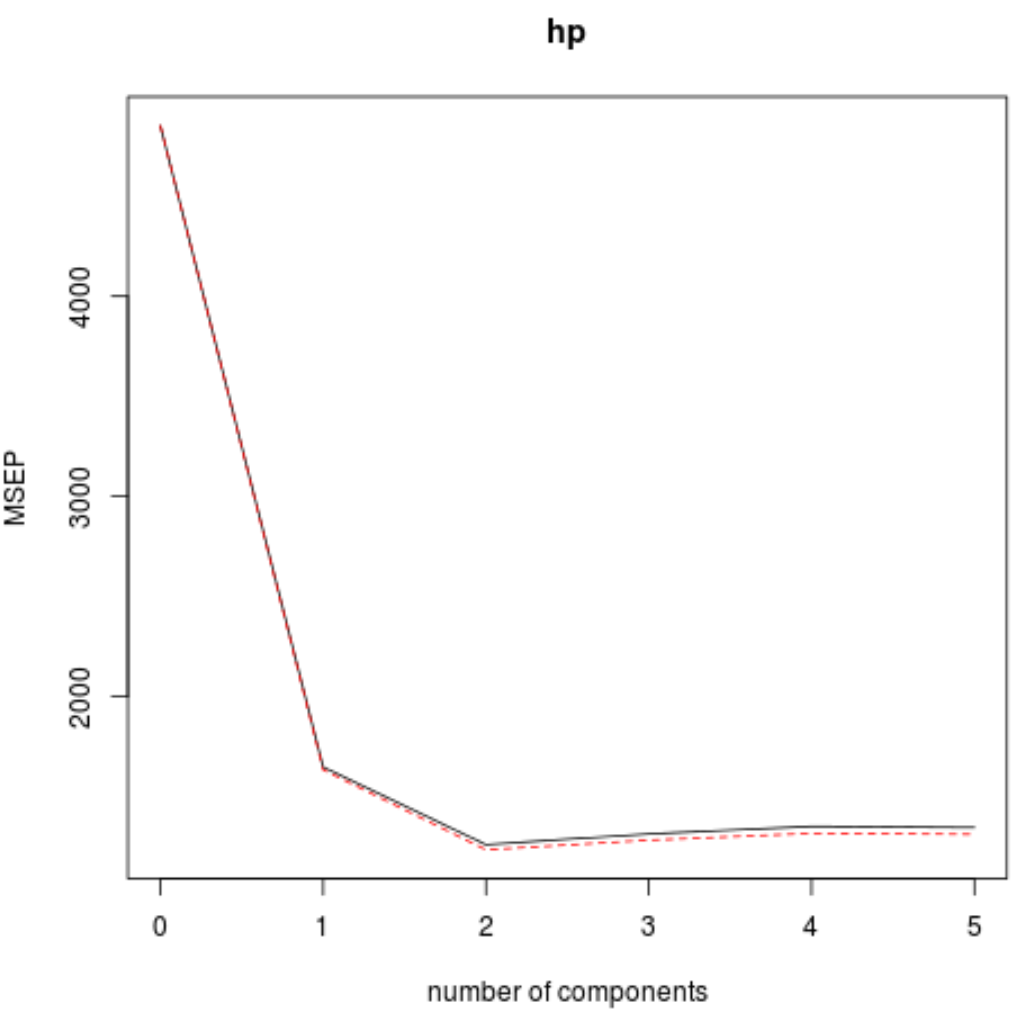
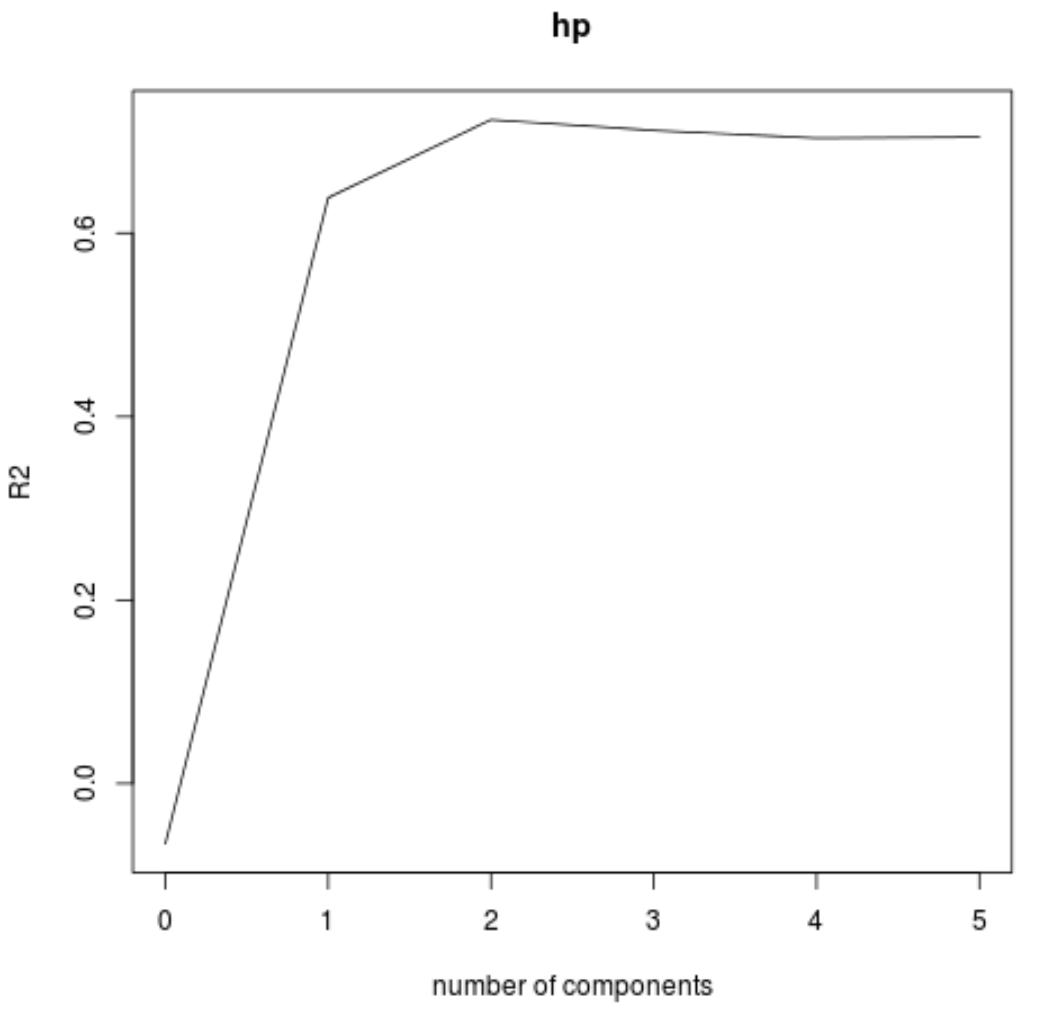
在每张图中,我们可以看到,通过添加两个 PLS 组件,模型拟合度有所提高,但当我们添加更多 PLS 组件时,模型拟合度往往会恶化。
因此,最优模型仅包含前两个 PLS 分量。
第 4 步:使用最终模型进行预测
我们可以使用具有两个 PLS 组件的最终模型来对新观察结果进行预测。
以下代码演示了如何将原始数据集拆分为训练集和测试集,并使用具有两个 PLS 组件的最终模型对测试集进行预测。
#define training and testing sets train <- mtcars[1:25, c("hp", "mpg", "disp", "drat", "wt", "qsec")] y_test <- mtcars[26: nrow (mtcars), c("hp")] test <- mtcars[26: nrow (mtcars), c("mpg", "disp", "drat", "wt", "qsec")] #use model to make predictions on a test set model <- plsr(hp~mpg+disp+drat+wt+qsec, data=train, scale= TRUE , validation=" CV ") pcr_pred <- predict(model, test, ncomp= 2 ) #calculate RMSE sqrt ( mean ((pcr_pred - y_test)^2)) [1] 54.89609
我们看到测试的 RMSE 结果为54.89609 。这是测试集观测值的预测hp值和观察到的hp值之间的平均偏差。
请注意,具有两个主成分的等效主成分回归模型产生的测试 RMSE 为56.86549 。因此,对于该数据集,PLS 模型稍微优于 PCR 模型。
可以在此处找到此示例中 R 代码的完整用法。
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多