如何在 r 中进行 one-hot 编码
One-hot 编码用于将分类变量转换为机器学习算法可以使用的格式。
one-hot 编码的基本思想是创建新变量,用值 0 和 1 来表示原始分类值。
例如,下图显示了我们如何进行单热编码,将包含团队名称的分类变量转换为仅包含 0 和 1 值的新变量:
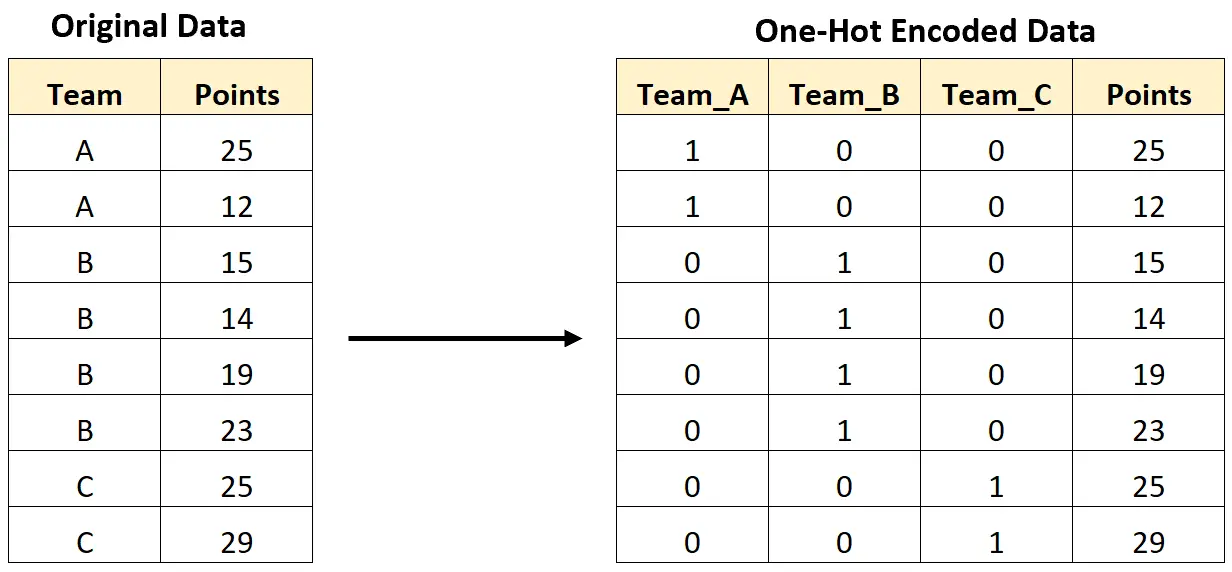
以下分步示例展示了如何在 R 中对这一精确数据集进行一次性编码。
第 1 步:创建数据
首先,我们在 R 中创建以下数据框:
#create data frame df <- data. frame (team=c('A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'), points=c(25, 12, 15, 14, 19, 23, 25, 29)) #view data frame df team points 1 to 25 2 to 12 3 B 15 4 B 14 5 B 19 6 B 23 7 C 25 8 C 29
第2步:执行one-hot编码
接下来,让我们使用caret包的dummyVars()函数对数据框中的“team”变量进行一次性编码:
library ( caret) #define one-hot encoding function dummy <- dummyVars(" ~ . ", data=df) #perform one-hot encoding on data frame final_df <- data. frame (predict(dummy, newdata=df)) #view final data frame final_df teamA teamB teamC points 1 1 0 0 25 2 1 0 0 12 3 0 1 0 15 4 0 1 0 14 5 0 1 0 19 6 0 1 0 23 7 0 0 1 25 8 0 0 1 29
请注意,由于原始“团队”列包含三个唯一值,因此数据框中已添加三个新列。
另请注意,原始的“团队”列已从数据框中删除,因为不再需要它。
One-hot 编码已完成,我们现在可以将此数据集输入到我们选择的任何机器学习算法中。
注意:您可以在此处找到dummyVars()函数的完整在线文档。
其他资源
以下教程提供了有关使用分类变量的更多信息:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多