如何从 r 中的 csv 文件读取特定行
您可以使用以下方法从 R 中的 CSV 文件读取特定行:
方法 1:从特定行导入 CSV 文件
df <- read. csv (" my_data.csv ", skip= 2 )
此特定示例将跳过 CSV 文件的前两行,并导入从第三行开始的文件的所有其他行。
方法 2:导入行满足条件的 CSV 文件
library (sqldf) df <- read. csv . sql (" my_data.csv ", sql = " select * from file where `points` > 90 ", eol = " \n ")
此特定示例将仅从 CSV 文件导入“points”列中的值大于 90 的行。
以下示例展示了如何在实践中通过以下名为my_data.csv的 CSV 文件使用这些方法:
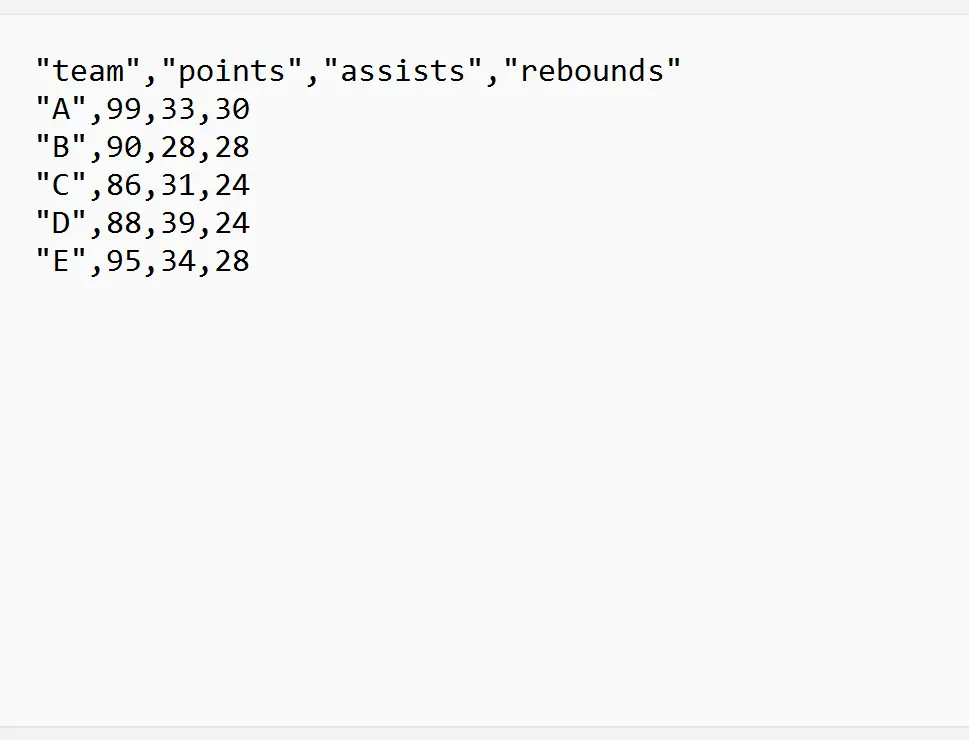
示例 1:从特定行导入 CSV 文件
以下代码显示如何导入 CSV 文件并忽略文件的前两行:
#import data frame and skip first two rows
df <- read. csv (' my_data.csv ', skip= 2 )
#view data frame
df
B X90 X28 X28.1
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
请注意,导入 CSV 文件时,前两行(团队 A 和 B)被忽略。
默认情况下,R 尝试使用下一个可用行的值作为列名。
要重命名列,您可以使用名称()函数,如下所示:
#rename columns
names(df) <- c(' team ', ' points ', ' assists ', ' rebounds ')
#view updated data frame
df
team points assists rebounds
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
示例 2:导入行满足条件的 CSV 文件
假设我们只想从 CSV 文件中导入点列中的值大于 90 的行。
我们可以使用sqldf包中的read.csv.sql函数来执行此操作:
library (sqldf)
#only import rows where points > 90
df <- read. csv . sql (" my_data.csv ",
sql = " select * from file where `points` > 90 ", eol = " \n ")
#view data frame
df
team points assists rebounds
1 “A” 99 33 30
2 “E” 95 34 28
请注意,仅导入了 CSV 文件中“points”列中的值大于 90 的两行。
注意#1 :在这个例子中,我们使用eol参数来指定文件中的“行尾”由\n指示,它代表换行符。
注意#2:在此示例中,我们使用了简单的 SQL 查询,但您可以编写更复杂的查询来按更多条件过滤行。
其他资源
以下教程解释了如何在 R 中执行其他常见任务:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多