如何在 r 中计算 dffits
在统计学中,我们经常想知道不同的观察结果对回归模型有何影响。
计算观测值影响的一种方法是使用称为DFFITS 的度量,它代表“拟合差异”。
该指标告诉我们,当我们忽略单个观察时,回归模型做出的预测会发生多少变化。
本教程展示了如何计算和可视化 R 模型中每个观测值的 DFFITS 的分步示例。
第 1 步:创建回归模型
首先,我们将使用 R 中内置的mtcars数据集创建一个多元线性回归模型:
#load the dataset data(mtcars) #fit a regression model model <- lm(mpg~disp+hp, data=mtcars) #view model summary summary(model) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 30.735904 1.331566 23.083 < 2nd-16 *** available -0.030346 0.007405 -4.098 0.000306 *** hp -0.024840 0.013385 -1.856 0.073679 . --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.127 on 29 degrees of freedom Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309 F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09
步骤 2:计算每个观测值的 DFFITS
接下来,我们将使用内置的dffits()函数来计算模型中每个观测值的 DFFITS 值:
#calculate DFFITS for each observation in the model dffits <- as . data . frame (dffits(model)) #display DFFITS for each observation challenges dffits(model) Mazda RX4 -0.14633456 Mazda RX4 Wag -0.14633456 Datsun 710 -0.19956440 Hornet 4 Drive 0.11540062 Hornet Sportabout 0.32140303 Valiant -0.26586716 Duster 360 0.06282342 Merc 240D -0.03521572 Merc 230 -0.09780612 Merc 280 -0.22680622 Merc 280C -0.32763355 Merc 450SE -0.09682952 Merc 450SL -0.03841129 Merc 450SLC -0.17618948 Cadillac Fleetwood -0.15860270 Lincoln Continental -0.15567627 Chrysler Imperial 0.39098449 Fiat 128 0.60265798 Honda Civic 0.35544919 Toyota Corolla 0.78230167 Toyota Corona -0.25804885 Dodge Challenger -0.16674639 AMC Javelin -0.20965432 Camaro Z28 -0.08062828 Pontiac Firebird 0.67858692 Fiat X1-9 0.05951528 Porsche 914-2 0.09453310 Lotus Europa 0.55650363 Ford Pantera L 0.31169050 Ferrari Dino -0.29539098 Maserati Bora 0.76464932 Volvo 142E -0.24266054
通常,我们会仔细观察 DFFITS 值高于阈值 2√ p/n的观测值,其中:
- p:模型中使用的预测变量的数量
- n:模型中使用的观测值数量
在此示例中,阈值为0.5 :
#find number of predictors in model p <- length (model$coefficients)-1 #find number of observations n <- nrow (mtcars) #calculate DFFITS threshold value thresh <- 2* sqrt (p/n) thresh [1] 0.5
我们可以根据观测值的 DFFITS 值对观测值进行排序,看看其中是否有任何超出阈值:
#sort observations by DFFITS, descending dffits[ order (-dffits[' dffits(model) ']), ] [1] 0.78230167 0.76464932 0.67858692 0.60265798 0.55650363 0.39098449 [7] 0.35544919 0.32140303 0.31169050 0.11540062 0.09453310 0.06282342 [13] 0.05951528 -0.03521572 -0.03841129 -0.08062828 -0.09682952 -0.09780612 [19] -0.14633456 -0.14633456 -0.15567627 -0.15860270 -0.16674639 -0.17618948 [25] -0.19956440 -0.20965432 -0.22680622 -0.24266054 -0.25804885 -0.26586716 [31] -0.29539098 -0.32763355
我们可以看到前五个观测值的 DFFITS 值大于 0.5,这意味着我们可能需要更仔细地研究这些观测值,以确定它们是否对模型有很大影响。
步骤 3:可视化每个观测值的 DFFITS
最后,我们可以创建一个快速图表来可视化每个观察的 DFFITS:
#plot DFFITS values for each observation plot(dffits(model), type = ' h ') #add horizontal lines at absolute values for threshold abline(h = thresh, lty = 2) abline(h = -thresh, lty = 2)
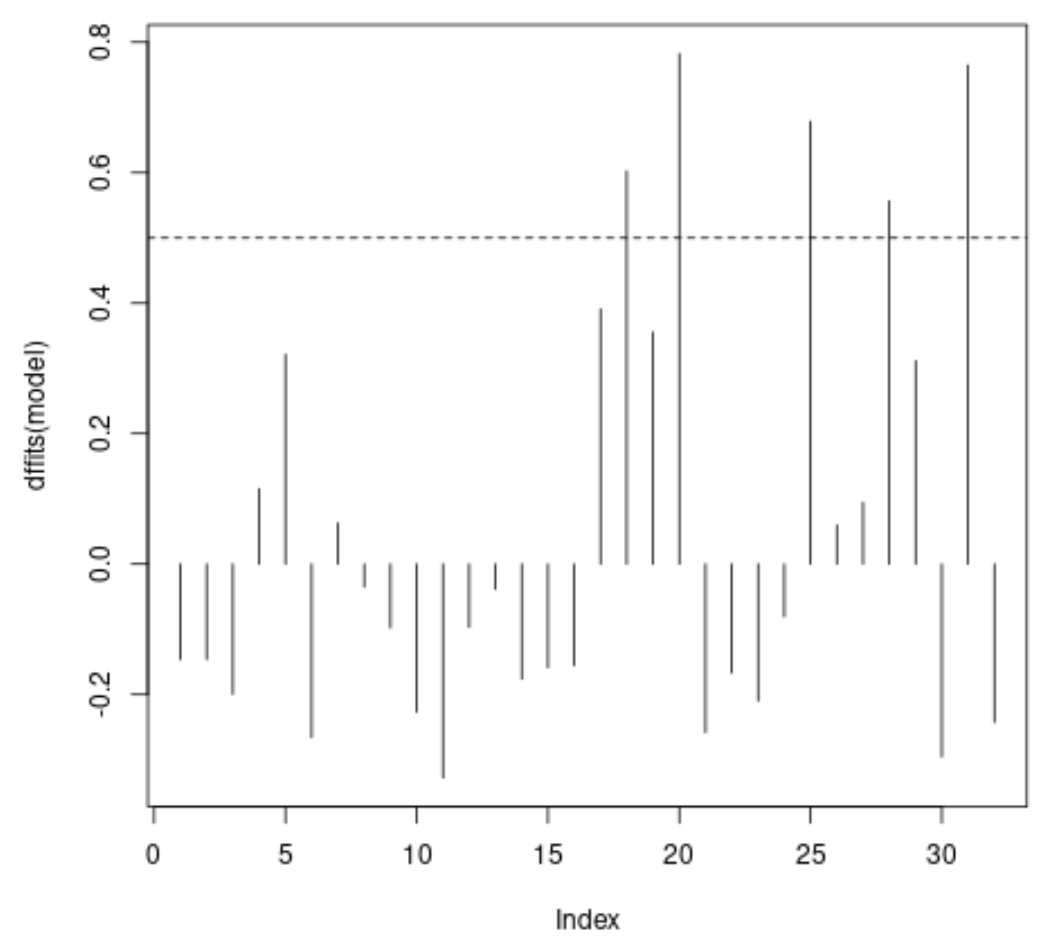
x 轴显示数据集中每个观测值的索引,y 值显示每个观测值对应的 DFFITS 值。
其他资源
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多