如何在 spss 中执行二次回归
当两个变量具有线性关系时,通常可以使用 简单线性回归来量化它们的关系。
然而,当两个变量具有非线性关系时,简单线性回归就不能很好地发挥作用。在这些情况下,您可以尝试使用二次回归。
本教程介绍如何在 SPSS 中执行二次回归。
示例:SPSS 中的二次回归
假设我们想了解工作时间与幸福感之间的关系。我们有以下关于 16 名不同的人每周工作时数和报告的幸福程度(范围为 0 到 100)的数据:
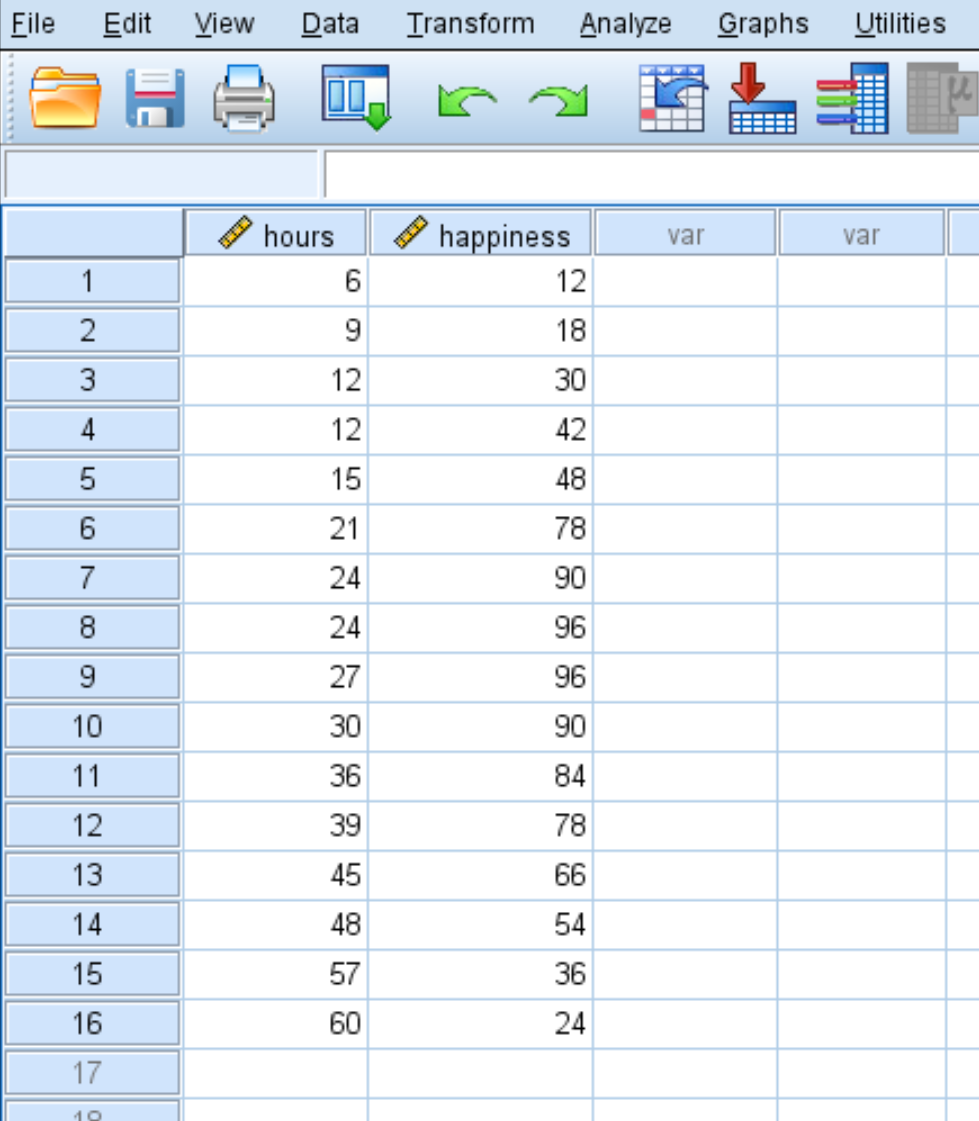
使用以下步骤在 SPSS 中执行二次回归。
步骤 1:可视化数据。
在执行二次回归之前,让我们创建一个散点图来可视化工作时间和幸福感之间的关系,以验证这两个变量实际上具有二次关系。
单击“图表”选项卡,然后单击“图表生成器” :
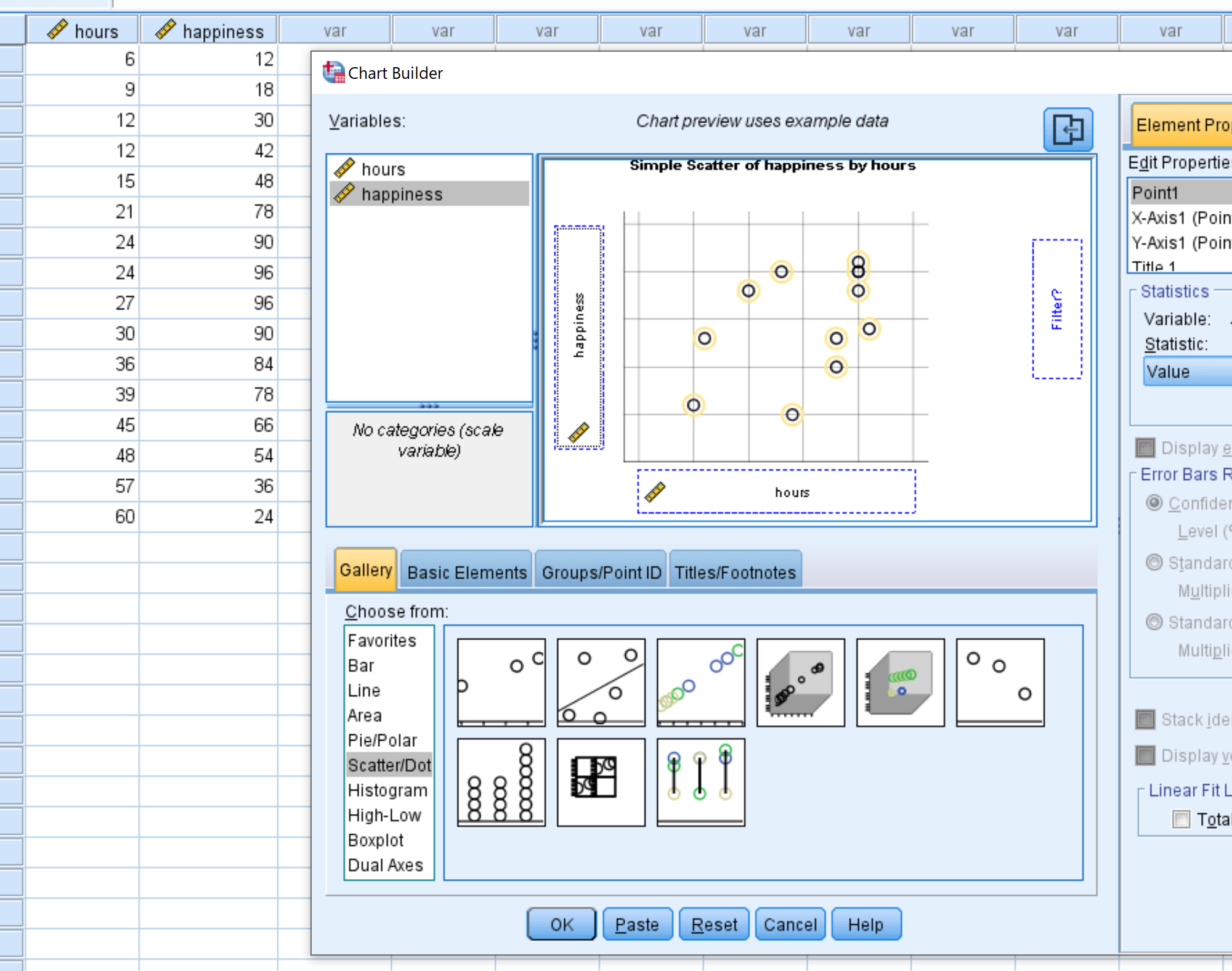
在出现的新窗口中,从“选择范围”列表中选择“散点/点” 。然后将标记为Simple Scatter的图表拖到主编辑窗口中。在 x 轴上拖动变量“小时” ,在 y 轴上拖动“幸福感” 。然后单击“确定” 。
将出现以下散点图:
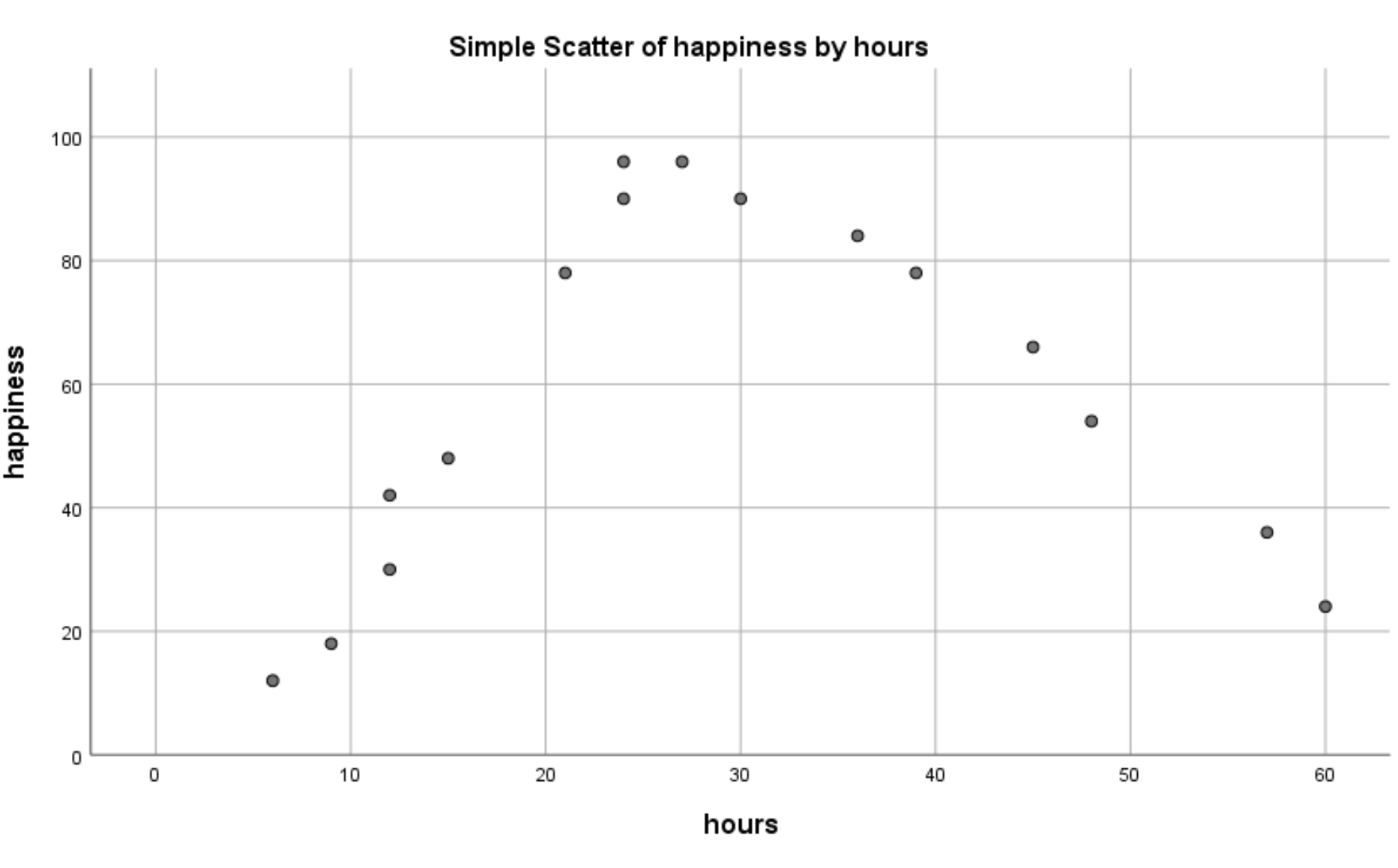
我们可以清楚地看到,工作时间和幸福感之间存在非线性关系。这告诉我们二次回归是在这种情况下使用的合适技术。
步骤 2:创建一个新变量。
在执行二次回归之前,我们需要创建2小时的预测变量。
单击“转换”选项卡,然后单击“计算变量” :
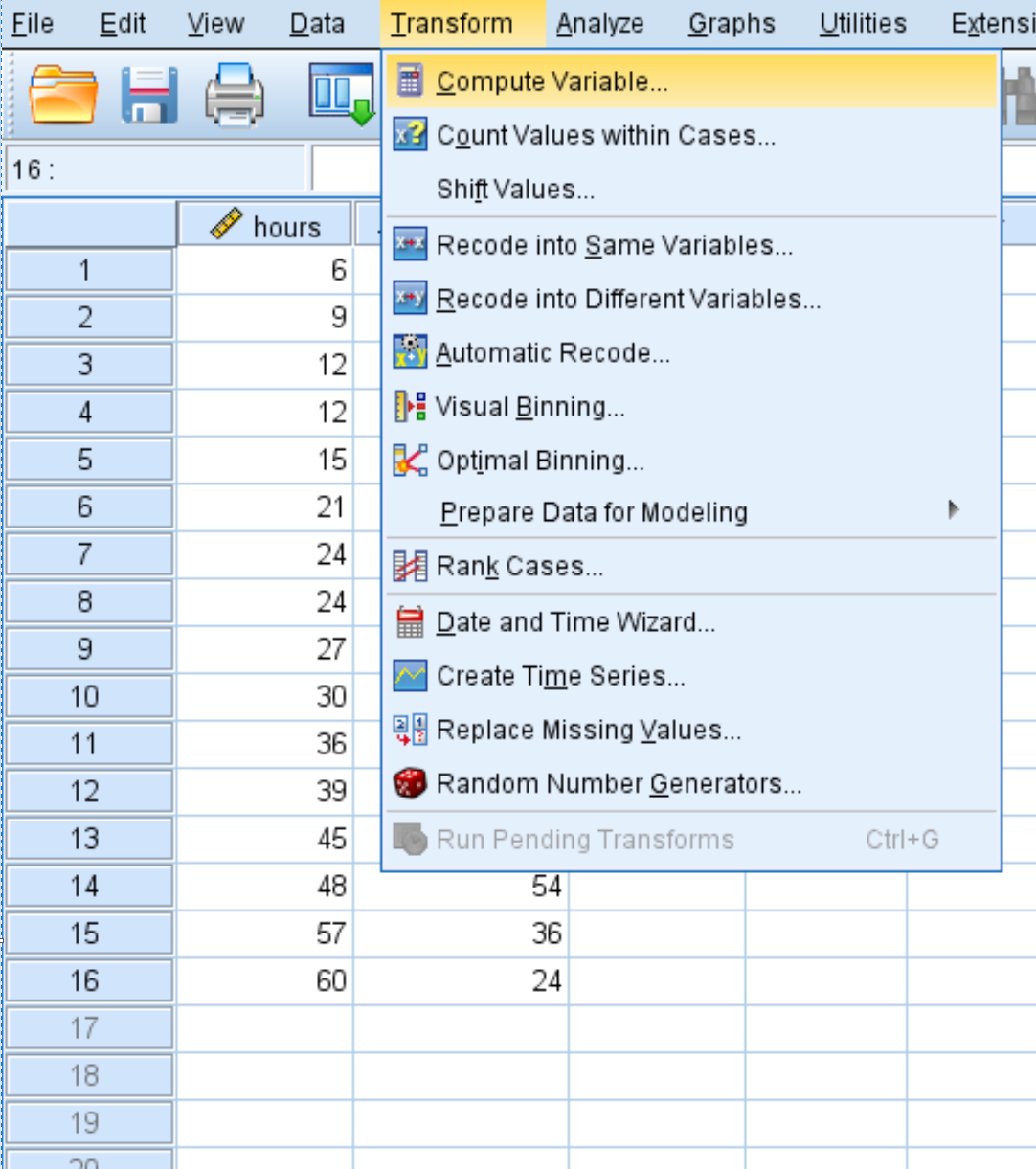
在出现的新窗口中,将目标变量命名为hours2并将其设置为hours*hours :
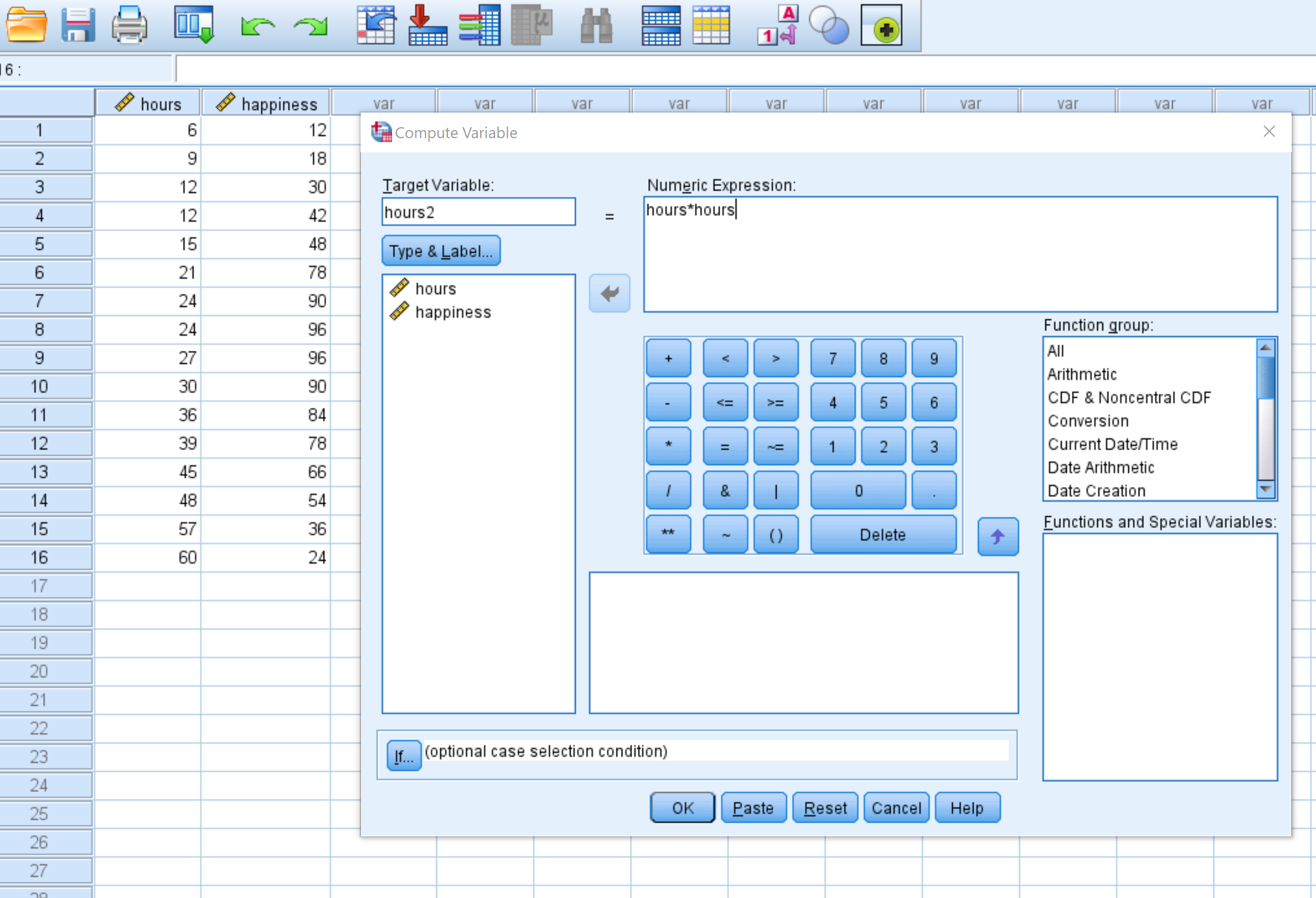
单击“确定”后, hours2变量将出现在新列中:
步骤 3:执行二次回归。
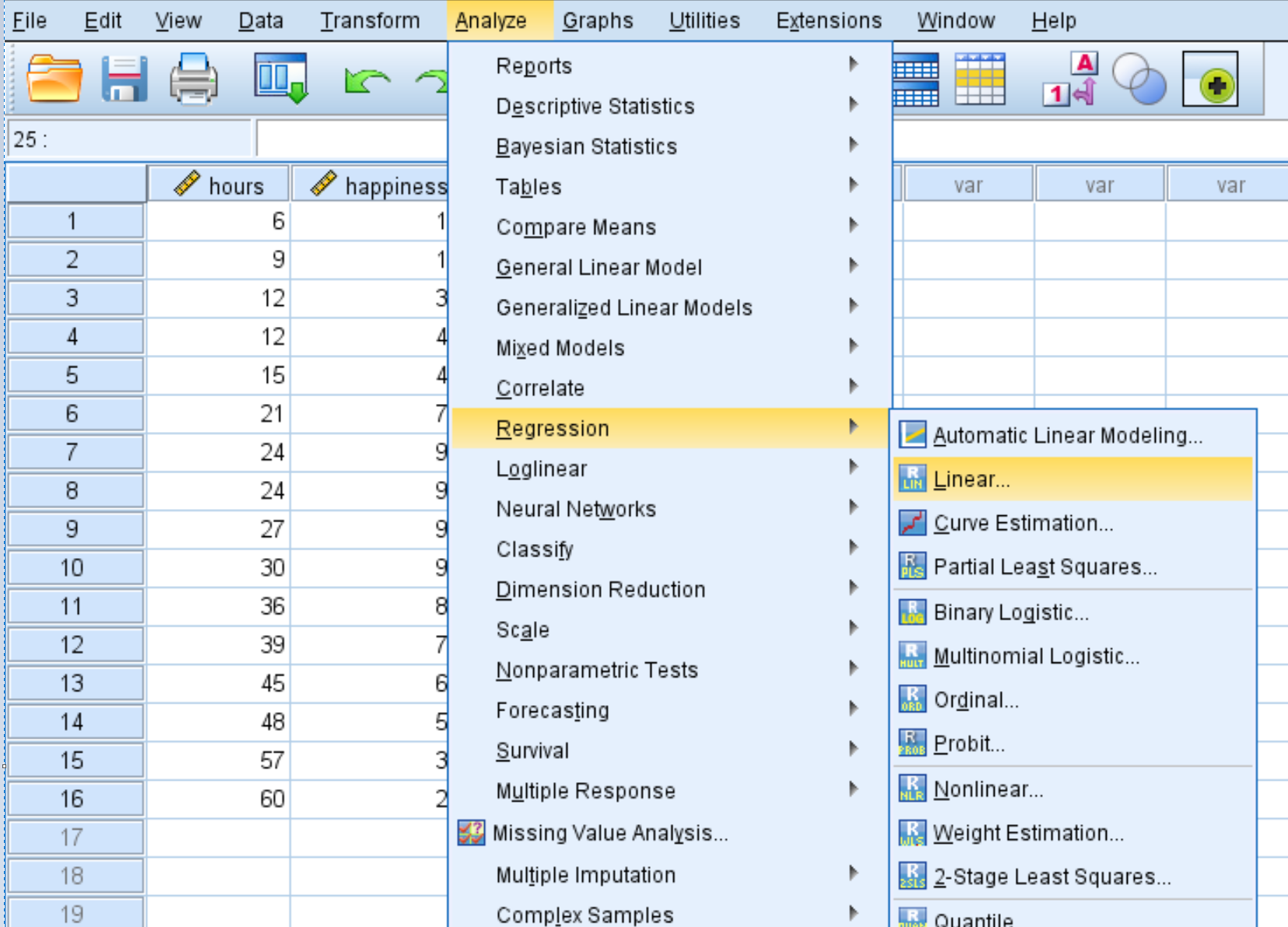
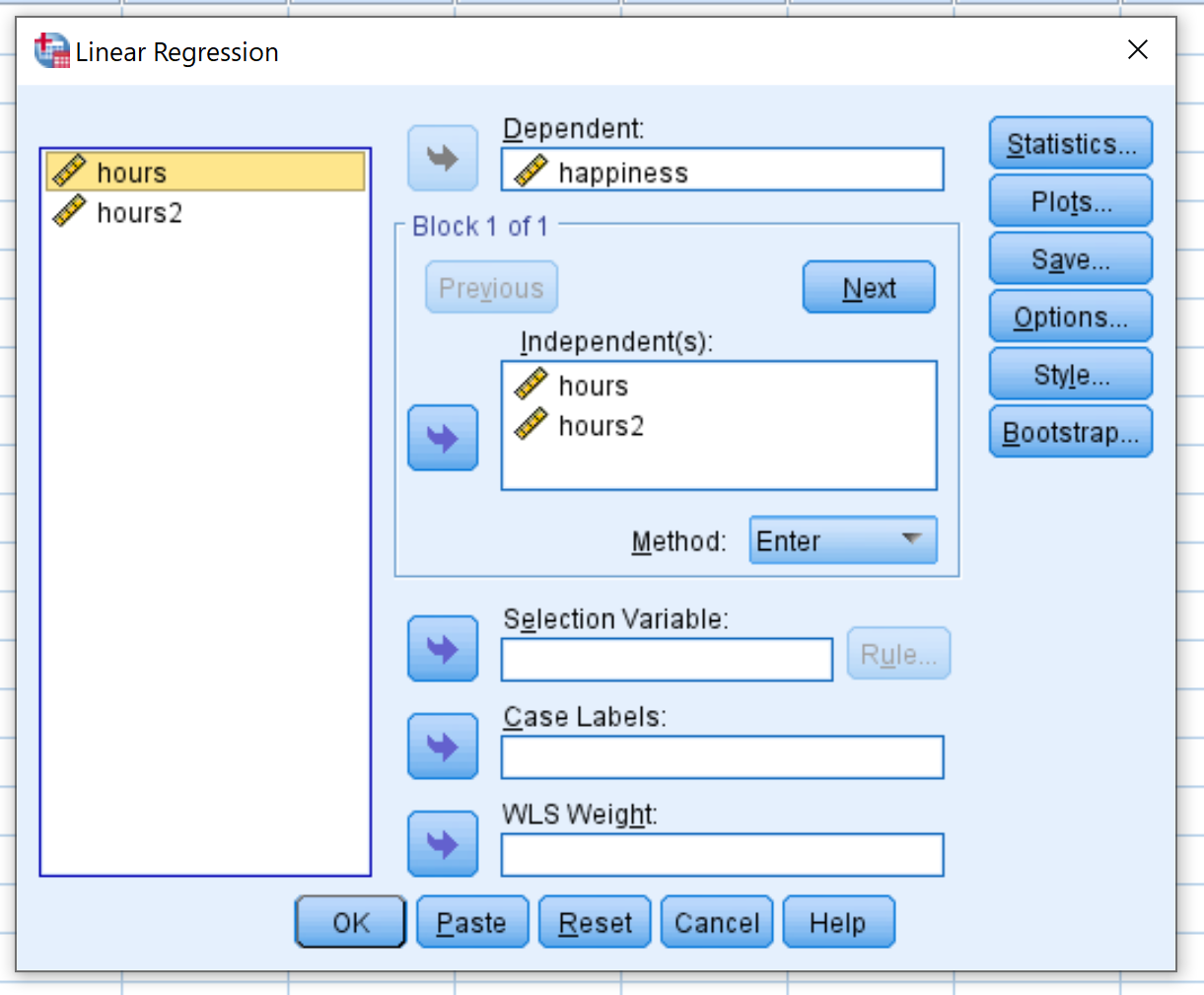
接下来,我们将执行二次回归。单击“分析”选项卡,然后单击“回归” ,然后单击“线性” :
在出现的新窗口中,将幸福拖到标记为“Dependent”的框中。将Hours和Hours2拖动到标记为 Independent(s) 的框中。然后单击“确定” 。
第 4 步:解释结果。
单击“确定”后,二次回归结果将显示在新窗口中。
我们感兴趣的第一个表称为模型摘要:

以下是如何解释此表中最相关的数字:
- R 方:这是可以由解释变量解释的响应变量方差的比例。在此示例中, 90.9%的幸福感变化可以通过小时和小时2变量来解释。
- 标准。估计误差:标准误差是观测值与回归线之间的平均距离。在此示例中,观测值与回归线平均偏差9,519个单位。
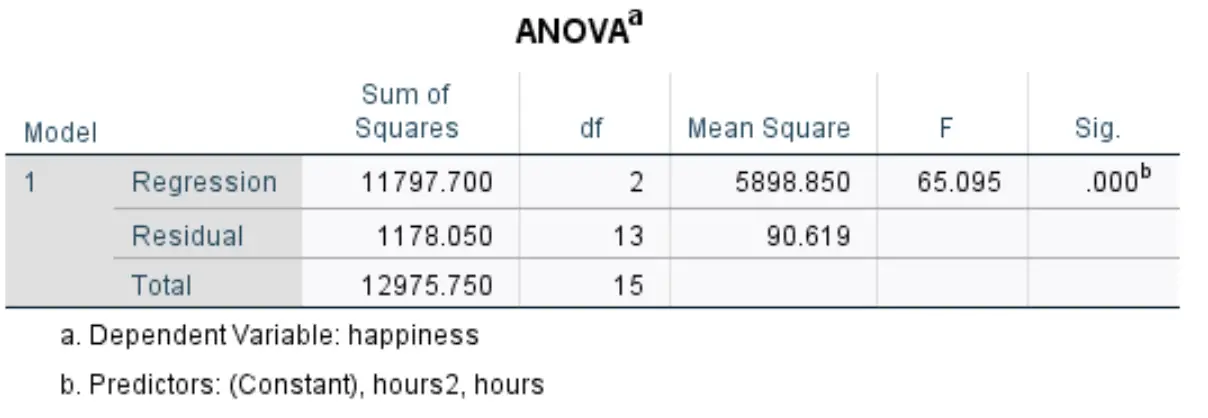
我们感兴趣的下一个表称为方差分析:
以下是如何解释此表中最相关的数字:
- F:这是回归模型的总体 F 统计量,计算方式为均方回归/均方残差。
- Sig:这是与总体 F 统计量相关的 p 值。这告诉我们回归模型作为一个整体是否具有统计显着性。在本例中,p 值等于 0.000,表明解释变量hours和hours 2组合与考试结果具有统计显着关联。
我们感兴趣的下表的标题是“系数” :
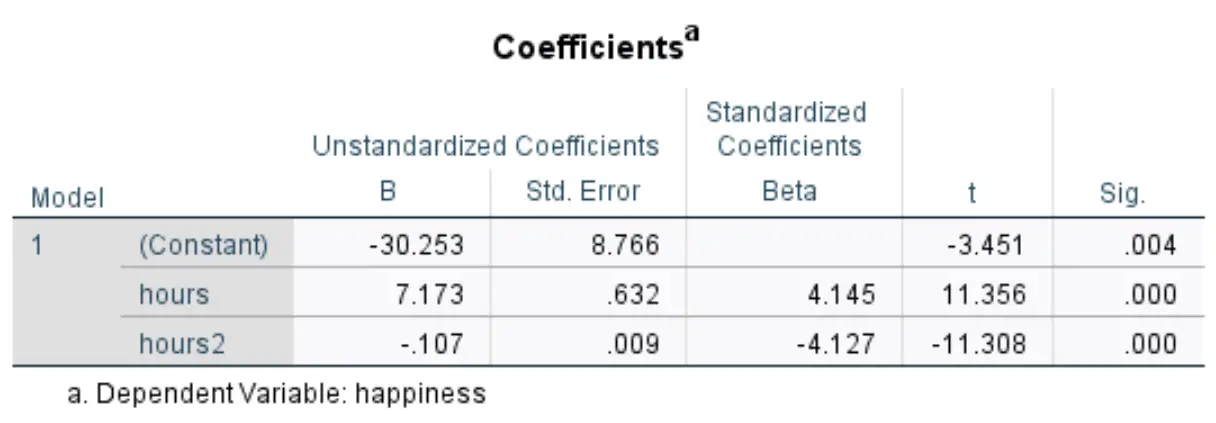
我们可以使用Unstandardized B列中的值来形成该数据集的估计回归方程:
估计幸福水平 = -30.253 + 7.173*(小时) – 0.107*(小时2 )
我们可以使用这个方程根据每周工作的小时数来找到个人的估计幸福水平。例如,一个每周工作 60 小时的人的幸福指数应该为 14.97:
估计幸福水平 = -30.253 + 7.173*(60) – 0.107*(60 2 ) = 14.97 。
相反,每周工作 30 小时的人的幸福指数应该为 88.65:
估计幸福水平 = -30.253 + 7.173*(30) – 0.107*(30 2 ) = 88.65 。
第五步:报告结果。
最后,我们想要报告二次回归的结果。以下是如何执行此操作的示例:
进行二次回归来量化个人工作小时数与其相应幸福水平(从 0 到 100 衡量)之间的关系。分析中使用了 16 人的样本。
结果表明,解释变量“小时”和“小时2 ”与响应变量幸福感之间存在统计显着关系(F(2, 13) = 65.095,p < 0.000)。
这两个解释变量共同解释了幸福感变异的 90.9%。
回归方程为:
估计幸福水平 = -30.253 + 7.173(小时)– 0.107( 2小时)
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多