不对称和扁平化
本文解释了统计学中的偏度和峰度。因此,您将找到这两个概念的定义、如何计算偏度和峰度、它们的公式是什么,以及用于计算任何数据样本的偏度和峰度的在线计算器。
什么是偏度和峰度?
偏度和峰度是两种统计度量,用于描述分布的形状,而无需将其绘制成图表。更具体地说,偏度表示分布的对称程度(或偏度),而峰度表示分布围绕其均值的集中程度。
在统计学中,偏度和峰度也称为形状度量。
👉您可以使用下面的在线计算器来计算任何数据集的偏度和峰度。
不对称
在统计学中,偏度是指示分布相对于其均值的对称(或不对称)程度的度量。简而言之,偏度是一个统计参数,用于确定分布的对称(或不对称)程度,而无需以图形方式表示。
因此,非对称分布是指均值左侧的值与其右侧的值数量不同的分布。另一方面,在对称分布中,均值左侧和右侧有相同数量的值。
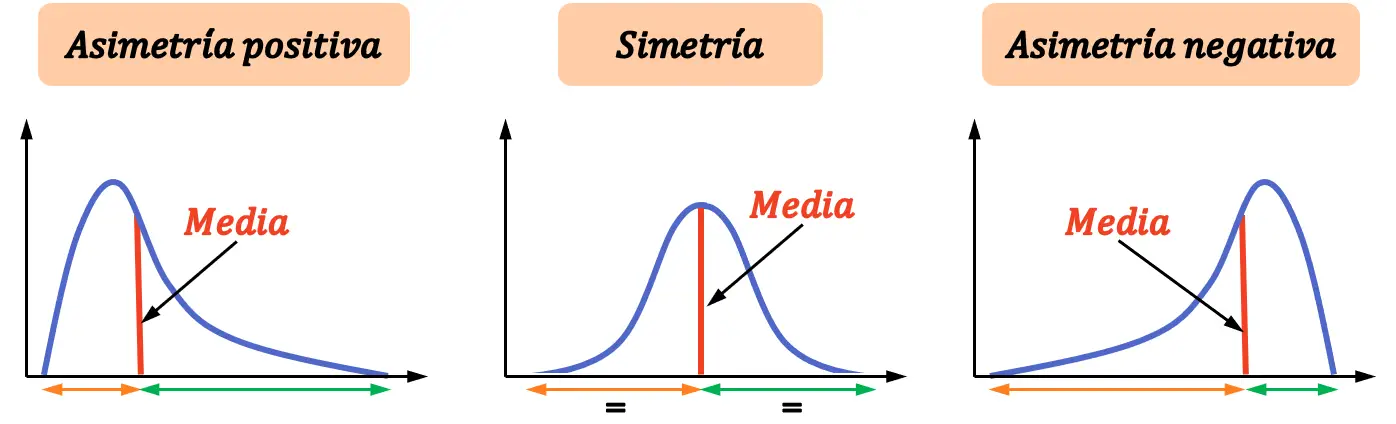
因此,我们区分三种类型的不对称:
- 正不对称:分布在均值右侧的不同值多于在其左侧的值。
- 对称性:分布在均值左侧和均值右侧具有相同数量的值。
- 负偏度:分布在均值左侧的不同值多于在其右侧的值。
不对称系数
偏度系数或不对称指数是一种统计系数,有助于确定分布的不对称性。因此,通过计算不对称系数,可以知道分布呈现什么类型的不对称性,而不必以图形方式表示它。
尽管计算不对称系数有不同的公式,我们将在下面看到它们,但无论使用哪种公式,不对称系数的解释始终如下:
- 如果 的偏度系数为正,则分布为正偏态。
- 如果 的不对称系数等于 0,则分布是对称的。
- 如果 的偏度系数为负,则分布为负偏态。
Fisher 不对称系数
Fisher 偏度系数等于均值的三阶矩除以样本标准差。因此, Fisher不对称系数的计算公式为:

等效地,可以使用以下两个公式中的任意一个来计算Fisher系数:

![\displaystyle\gamma_1=\frac{\operatorname{E}[X^3] - 3\mu\sigma^2 - \mu^3}{\sigma^3}](https://statorials.org/wp-content/ql-cache/quicklatex.com-92f7c8482d520258f24cc0166d898d1e_l3.png "Rendered by QuickLaTeX.com")
金子

是数学期望,

算术平均值,

标准差和

数据总数。
另一方面,如果数据已分组,则可以使用以下公式:

在这种情况下哪里

它是阶级的标志

课程的绝对频率。
皮尔逊不对称系数
皮尔逊偏度系数等于样本均值与众数之差除以其标准差(或标准差)。因此,皮尔逊不对称系数的公式如下:

金子

是皮尔逊系数,
算术平均值,

时尚和
标准差。
请记住,只有在单峰分布(即数据中只有一种众数)的情况下,才能计算皮尔逊偏度系数。
鲍利不对称系数
鲍利偏度系数等于第三个四分位数加上第一个四分位数之和减去中位数的两倍除以第三个四分位数和第一个四分位数之间的差。因此,该不对称系数的公式如下:

金子

和

这些分别是第一和第三四分位数

是分布的中位数。
扁平化
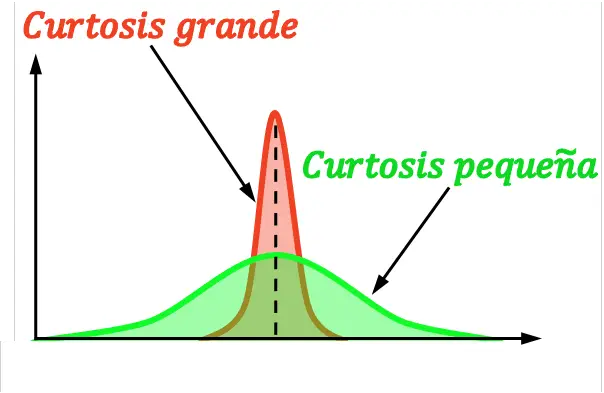
峰度,也称为偏度,表示分布在其均值周围的集中程度。换句话说,峰度表示分布是陡峭还是平坦。具体来说,分布的峰度越大,它就越陡(或越尖锐)。
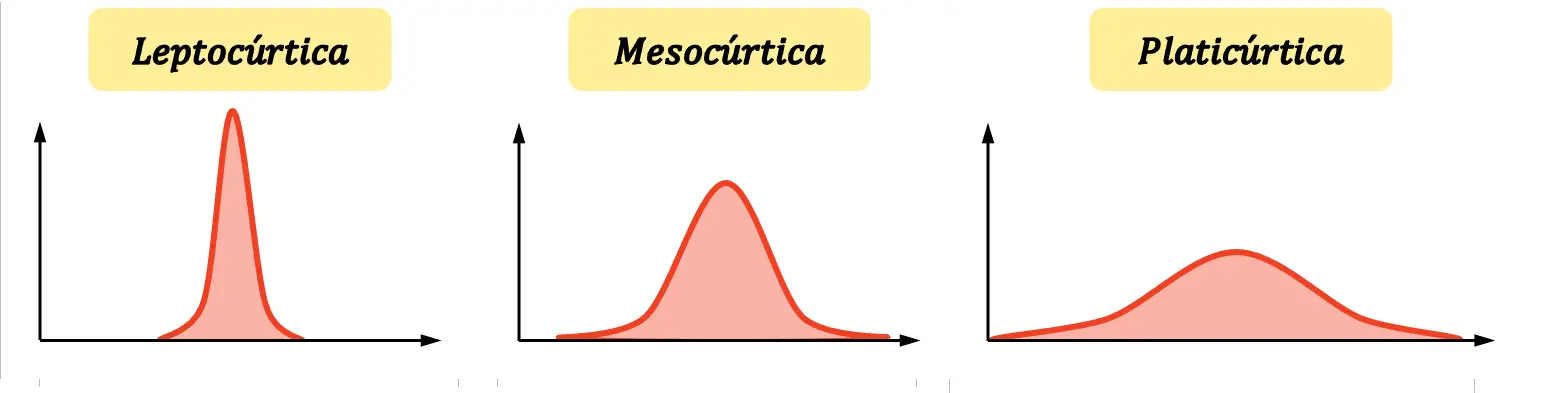
奉承有三种类型:
- Leptokurtic :分布非常尖锐,也就是说数据强烈集中在均值附近。更准确地说,尖峰分布被定义为比正态分布更尖锐的分布。
- 中峰:分布的峰度相当于正态分布的峰度。因此,它既不被认为是尖锐的,也不被认为是阿谀奉承的。
- Platykurtic :分布非常平坦,也就是说平均值周围的集中度较低。形式上,峰态分布被定义为比正态分布更平坦的分布。
请注意,不同类型的峰度是以正态分布的峰度为参考来定义的。
峰度系数
峰度系数的计算公式如下:

频率表中分组数据的峰度系数公式:

最后,按区间分组的数据的峰度系数公式:

金子:
-

是峰度系数。
-
是数据总数。
-
是该系列中的第 i 个数据点。
-
是分布的算术平均值。
-
是分布的标准偏差(或典型偏差)。
-
是 it 数据集的绝对频率。
-

是第i组的班级分数。
请注意,在所有峰度系数公式中,都减去 3,因为它是正态分布的峰度值。因此,峰度系数的计算是以正态分布的峰度为参考来进行的。这就是为什么有时在统计学中会计算出过度峰度。
计算出峰度系数后,必须对其进行如下解释,以确定峰度的类型:
- 如果峰度系数为正,则表示分布是尖峰的。
- 如果峰度系数为零,则意味着分布是中峰态的。
- 如果峰度系数为负,则表示分布是平峰的。
偏度和峰度计算器
将数据集输入以下计算器以计算其偏度和峰度系数,并确定其分布类型。数据必须用空格分隔,并使用句点作为小数点分隔符输入。
不对称性和峰度有什么用?
最后,我们将了解偏度和峰度在统计中的用途以及如何解释这两种类型的统计参数。
偏度和峰度用于定义概率分布的形状,而无需以图形方式表示。也就是说,计算偏度和峰度来确定它是什么类型的分布,而不需要将其绘制成图表,这通常需要花费大量的时间和精力。
此外,偏度和峰度值用于将分布曲线与正态分布进行比较。因为如果它们相似,这意味着要研究的分布可以近似于正态分布,因此可以应用几个统计定理。
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多