阳性预测值与敏感性:有什么区别?
评估分类模型性能的最常见方法之一是创建混淆矩阵,该矩阵根据数据集的实际结果总结了模型的预测结果。
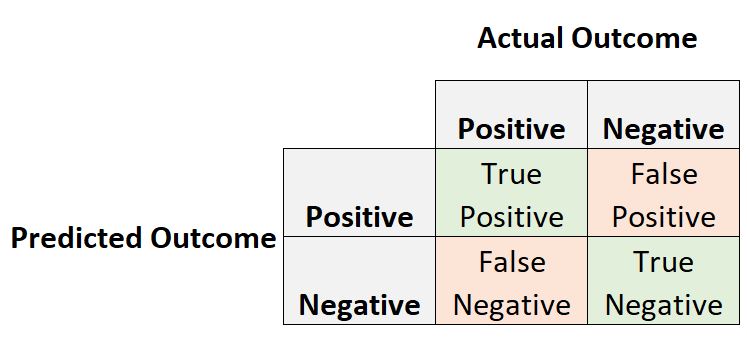
我们在混淆矩阵中经常感兴趣的两个指标是阳性预测值和敏感性。
阳性预测值是具有阳性预测结果的观察结果实际上具有阳性结果的概率。
计算方法如下:
阳性预测值= 真阳性 /(真阳性 + 假阳性)

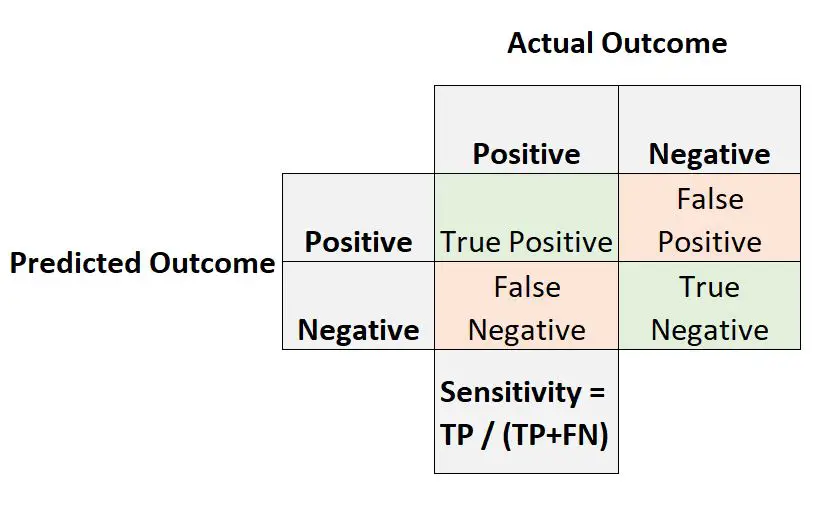
敏感性是指具有阳性结果的观测实际上具有阳性预测结果的概率。
计算方法如下:
灵敏度= 真阳性 /(真阳性 + 假阴性)
以下示例展示了如何在实践中计算这两个指标。
示例:阳性预测值和敏感性的计算
假设一位医生使用逻辑回归模型来预测 400 人是否患有某种疾病。
以下混淆矩阵总结了模型所做的预测:
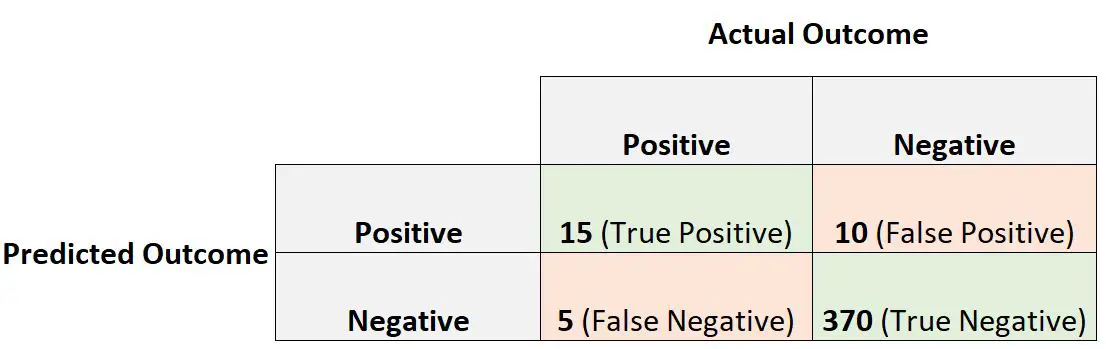
我们将按如下方式计算阳性预测值:
- 阳性预测值= 真阳性 /(真阳性 + 假阳性)
- 阳性预测值= 15 / (15 + 10)
- 阳性预测值= 0.60
这告诉我们,收到阳性检测结果的人实际上患有这种疾病的概率是0.60 。
我们将按如下方式计算灵敏度:
- 灵敏度= 真阳性 /(真阳性 + 假阴性)
- 灵敏度= 15 / (15 + 5)
- 灵敏度= 0.75
这告诉我们,患有这种疾病的人实际上收到阳性检测结果的概率是0.75 。
其他资源
以下教程解释了如何在不同的统计软件中创建混淆矩阵:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多