统计学中的y hat是什么?
在统计学中,术语y hat (写作ŷ )是指线性回归模型中响应变量的估计值。
我们一般会写出一个估计回归方程如下:
ŷ = β 0 + β 1 x
金子:
- ŷ : 响应变量的估计值
- β 0 :预测变量为零时响应变量的平均值
- β 1 :与预测变量增加一个单位相关的响应变量的平均变化
例如,假设我们有以下数据集,显示了六名不同学生的学习小时数以及他们的期末考试成绩:
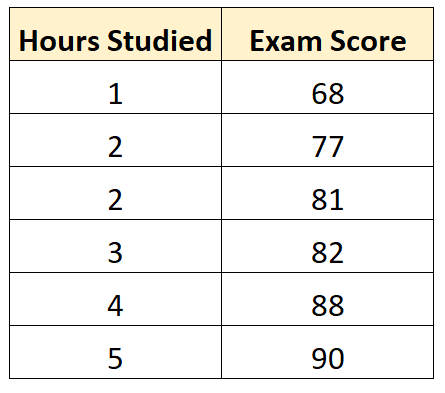
假设我们使用统计软件(如R 、 Excel 、Python ,甚至手动)使用研究时间作为预测变量来拟合以下回归模型,并检查结果作为响应变量:
分数 = 66.615 + 5.0769*(小时)
该模型中回归系数的解释方法如下:
- 零学时学生的平均考试成绩为66,615 分。
- 每多学习一小时,考试成绩平均就会增加5.0769分。
我们可以使用这个回归方程根据学习的小时数来估计给定学生的分数。
例如,学习 3 小时的学生应获得以下分数:
分数 = 66.615 + 5.0769*(3) = 81.85
为什么使用 Y 帽?
统计中的“帽子”符号用于表示任何“估计”术语。例如, ŷ用于表示估计响应变量。
通常,当我们拟合线性回归模型时,我们使用总体中的数据样本,因为这比为总体中每个可能的观察收集数据更方便且更省时。
因此,当我们找到回归方程时,我们只是估计预测变量和响应变量之间的真实关系。
这就是为什么我们在回归方程中使用 ŷ 项而不是 y。
其他资源
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多