促进机器学习的简单介绍
大多数监督机器学习算法都基于使用单一预测模型,如线性回归、逻辑回归、岭回归等。
然而, 装袋和随机森林等方法基于原始数据集的重复引导样本构建了许多不同的模型。对新数据的预测是通过计算各个模型的预测平均值来进行的。
与仅使用单个预测模型的方法相比,这些方法往往会提高预测准确性,因为它们使用以下过程:
另一种能够在预测准确性方面提供更大改进的方法称为提升。
什么是升压?
Boosting 是一种可用于任何类型模型的方法,但最常用于决策树。
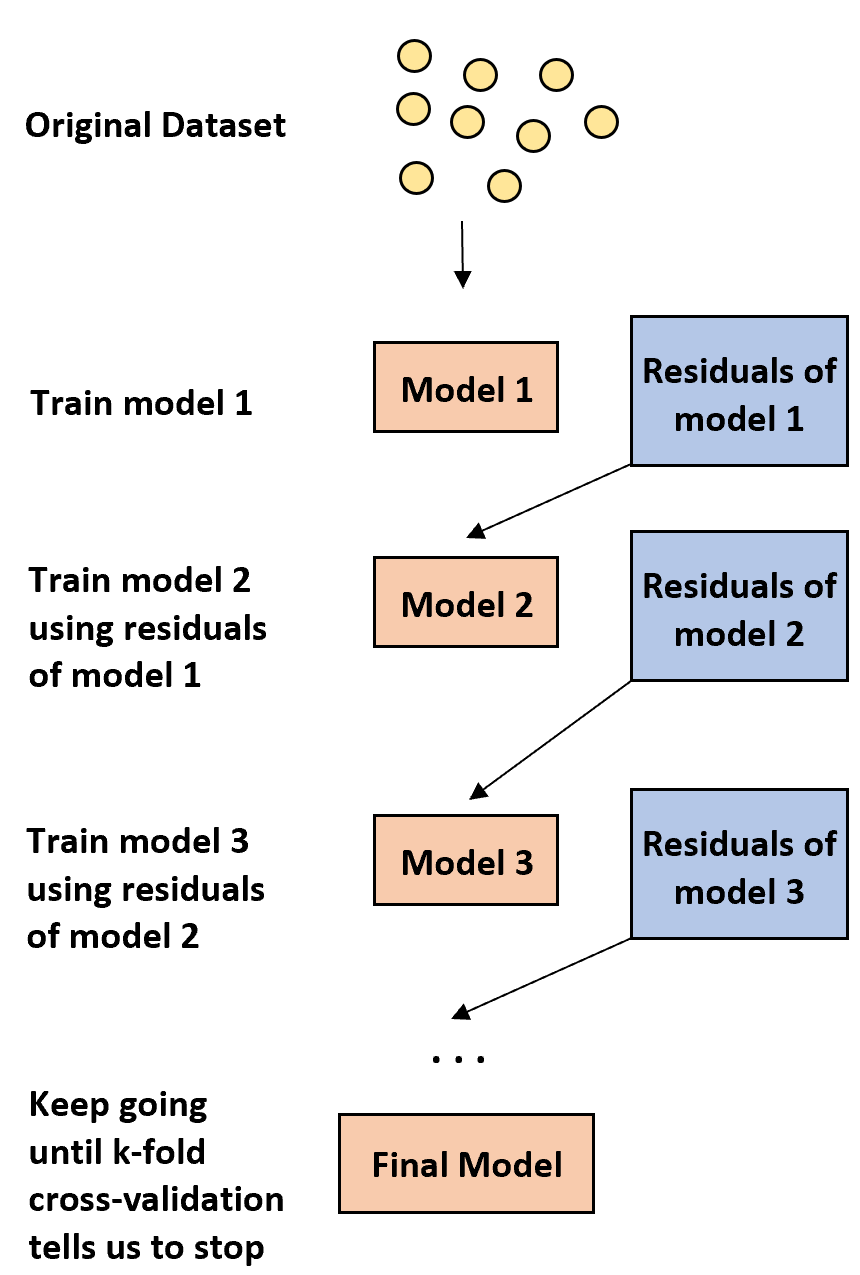
boosting 背后的想法很简单:
1. 首先,建立弱模型。
- “弱”模型是指错误率仅比随机估计稍好一点的模型。
- 在实践中,这通常是只有一个或两个分区的决策树。
2. 接下来,根据前一个模型的残差构建另一个弱模型。
- 在实践中,我们使用先前模型的残差(即我们预测中的错误)来拟合新模型,该模型稍微提高了总体错误率。
3. 继续这个过程,直到 k 折交叉验证告诉我们停止。
- 在实践中,我们使用k 折交叉验证来确定何时应该停止开发增强模型。
使用这种方法,我们可以从一个弱模型开始,通过顺序构建新的树来提高前一棵树的性能,从而继续“提高”其性能,直到获得具有高预测精度的最终模型。
为什么提升会起作用?
事实证明,Boosting 能够产生所有机器学习中一些最强大的模型。
在许多行业中,增强模型被用作生产中的参考模型,因为它们往往优于所有其他模型。
增强模板工作得这么好的原因可以归结为理解一个简单的想法:
1.首先,改进的模型构建了预测精度较低的弱决策树。据说该决策树具有低方差和高偏差。
2.由于改进后的模型遵循了先前决策树的顺序改进过程,因此整体模型能够缓慢地减少每一步的偏差,而不会显着增加方差。
3.最终的拟合模型往往具有足够低的偏差和方差,从而使模型能够对新数据产生较低的测试错误率。
提升的优点和缺点
Boosting 的明显优势在于,与几乎所有其他类型的模型相比,它能够生成具有高预测精度的模型。
一个潜在的缺点是拟合的改进模型很难解释。尽管它可以提供预测新数据响应值的巨大能力,但很难解释它实现这一目标的确切过程。
在实践中,大多数数据科学家和机器学习从业者创建改进的模型,因为他们希望能够准确预测新数据的响应值。因此,改进模型难以解释这一事实通常不是问题。
实践中的助推器
在实践中,有许多类型的算法用于提升,包括:
根据数据集的大小和计算机的处理能力,其中一种方法可能优于另一种方法。
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多