决策树与随机森林:有什么区别?
决策树是一种机器学习模型,当一组预测变量和响应变量之间的关系是非线性时使用。
决策树背后的基本思想是使用一组预测变量构建一棵“树”,该树使用决策规则预测响应变量的值。
例如,我们可以使用预测变量“打球年数”和“平均本垒打”来预测职业棒球运动员的年薪。
使用此数据集,决策树模型可能如下所示:
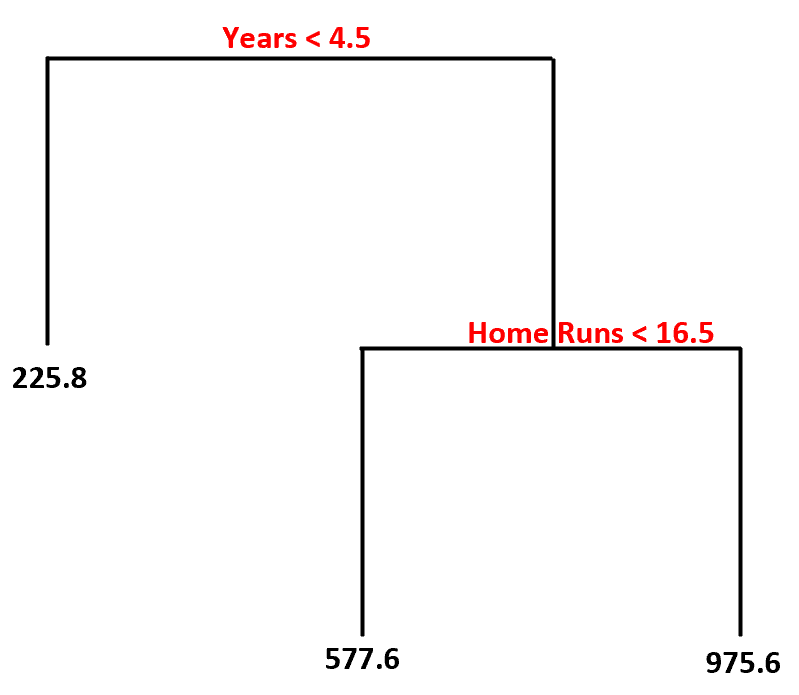
以下是我们如何解释这个决策树:
- 打球时间少于 4.5 年的球员的预计薪水为$225.8k 。
- 平均打球时间超过 4.5 年且本垒打少于 16.5 个的球员的预计薪水为$577.6K 。
- 拥有 4.5 年或以上经验、平均 16.5 个或以上本垒打的球员的预期薪水为$975.6K 。
决策树的主要优点是它可以快速适应数据集,并且可以使用上面的“树”图清晰地可视化和解释最终模型。
主要缺点是决策树往往会过度拟合训练数据集,这意味着它可能在未见过的数据上表现不佳。这也可能受到数据集中异常值的严重影响。
决策树的扩展是称为随机森林的模型,它本质上是一组决策树。
以下是我们创建随机森林模型的步骤:
1.从原始数据集中获取引导样本。
2.对于每个引导样本,使用预测变量的随机子集创建决策树。
3.对每棵树的预测进行平均以获得最终模型。
随机森林的优势在于,它们在未见过的数据上的表现往往比决策树好得多,并且不太容易出现异常值。
随机森林的缺点是无法可视化最终模型,如果您没有足够的计算能力或者您正在使用的数据集非常庞大,那么构建它们可能需要很长时间。
优点和缺点:决策树与决策树随机森林
下表总结了决策树与随机森林相比的优点和缺点:
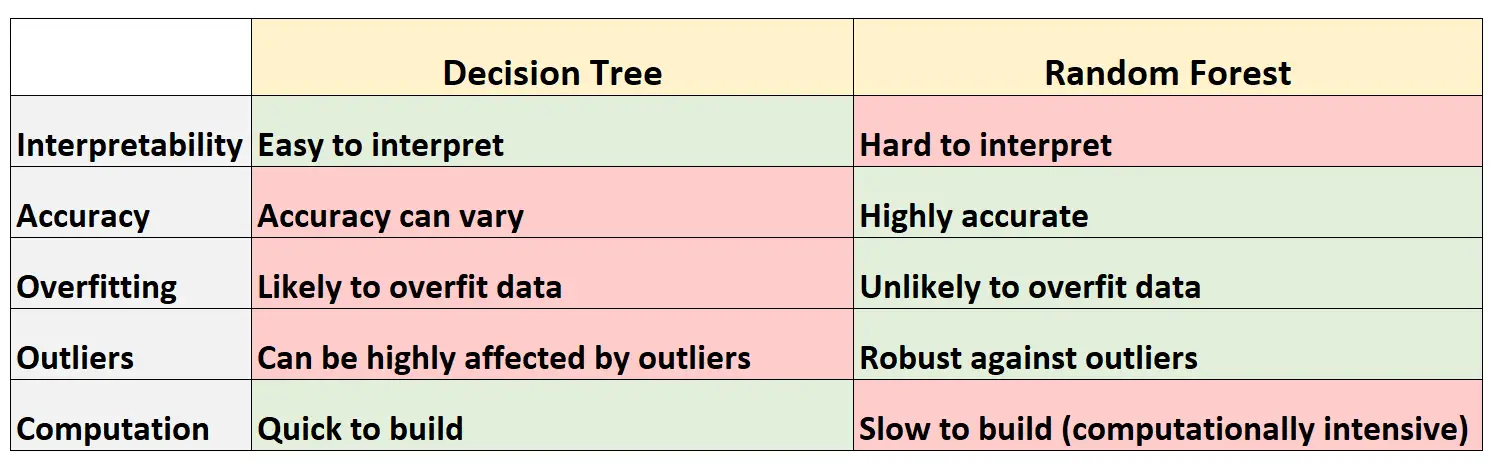
以下是表中每一行的简要说明:
1. 可解释性
决策树很容易解释,因为我们可以创建树图来可视化和理解最终模型。
相反,我们无法可视化随机森林,并且通常很难理解最终的随机森林模型如何做出决策。
2. 准确度
由于决策树可能会过度拟合训练数据集,因此它们在未见过的数据集上往往表现较差。
相反,随机森林在未见过的数据集上往往非常准确,因为它们避免了过度拟合训练数据集。
3. 过拟合
如前所述,决策树通常会过度拟合训练数据:这意味着它们可能会适应数据集的“噪声”,而不是真正的底层模型。
相反,由于随机森林仅使用某些预测变量来构建每个单独的决策树,因此最终的树往往会被装饰,这意味着随机森林模型不太可能过度拟合数据集。
4. 异常值
决策树非常容易受到异常值的影响。
相反,由于随机森林模型会构建许多单独的决策树,然后取这些树的预测平均值,因此它受异常值影响的可能性要小得多。
5. 计算
决策树可以快速适应数据集。
相反,随机森林的计算量更大,并且可能需要很长时间才能创建,具体取决于数据集的大小。
何时使用决策树或随机森林
一般来说:
如果您想快速创建非线性模型并能够轻松解释模型如何做出决策,则应该使用决策树。
但是,如果您拥有大量计算能力并且想要创建一个可能非常准确的模型而不用担心如何解释模型,则应该使用随机森林。
在现实世界中,机器学习工程师和数据科学家经常使用随机森林,因为它们非常准确,而且现代计算机和系统通常可以处理以前无法处理的大型数据集。
其他资源
以下教程介绍了决策树和随机森林模型:
以下教程解释了如何在 R 中拟合决策树和随机森林:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多