异常值如何影响均值?
在统计学中,一组数据的平均数就是平均值。了解这一点很有用,因为它让我们了解数据集的“中心”在哪里。它是使用简单的公式计算的:
平均值=(观测值总和)/(观测值数量)
例如,假设我们有以下数据集:
[1,4,5,6,7]
数据集的平均值为 (1+4+5+6+7) / (5) = 4.6
但尽管平均值很有用且易于计算,但它有一个缺点:它可能会受到异常值的影响。特别是,数据集越小,异常值对均值的影响就越大。
为了说明这一点,请考虑以下经典示例:
酒吧里坐着十个人。十个人的平均收入是五万美元。突然,一个男人走了出来,比尔·盖茨走了进来。如今,酒吧里十个人的平均收入为 4000 万美元。
此示例显示异常值(比尔·盖茨)如何显着影响平均值。
小异常值和大异常值
异常值可能会因异常小或异常大而影响均值。在前面的例子中,比尔·盖茨的收入异常高,导致平均值具有误导性。
然而,异常低的值也会影响平均值。为了说明这一点,请考虑以下示例:
十名学生参加考试并获得以下成绩:
[0, 88, 90, 92, 94, 95, 95, 96, 97, 99]
平均分是84.6分。
但是,如果我们从数据集中删除分数“0”,则平均分数变为94 。
学生异常低的分数会降低整个数据集的平均值。
样本量和异常值
数据集的样本量越小,异常值影响均值的可能性就越大。
例如,假设我们有一个包含 100 份考试成绩的数据集,其中所有学生的得分至少为 90 分或更高,除了一名学生得分为零:
[ 0 , 90, 90, 92, 94, 95, 95, 96, 97, 99, 94, 90, 90, 92, 94, 95, 95, 96, 97, 99, 93, 90, 90, 92, 94 , 95, 95, 96, 97, 99, 93, 90, 90, 92, 94, 95, 95, 96, 97, 99, 93, 90, 90, 92, 94, 95, 95, 96, 97, 99 , 93, 90, 90, 92, 94, 95, 95, 96, 97, 99, 93, 90, 90, 92, 94, 95, 95, 96, 97, 99, 93, 90, 90, 92, 94 , 95, 95, 96, 97, 99, 93, 90, 90, 92, 94, 95, 95, 96, 97, 99, 93, 90, 90, 92, 94, 95, 95, 96, 97, 99 ]
平均值为93.18 。如果我们从数据集中删除“0”,平均值将为94.12 。这是一个相对较小的差异。这表明,如果数据集足够大,即使极端异常值也只会产生最小的影响。
如何处理异常值
如果您担心数据集中可能存在异常值,您有多种选择:
- 确保异常值不是数据输入错误的结果。有时,个人在保存数据时只是输入了错误的数据值。如果存在异常值,请首先验证输入的值是否正确并且没有错误。
- 为异常值指定一个新值。如果异常值是数据输入错误的结果,您可以决定为其分配一个新值,例如数据集的平均值或中位数。
- 删除异常值。如果该值确实是异常值,并且会对您的整体分析产生重大影响,则您可以选择将其删除。请务必在最终报告或分析中提及您删除了异常值。
使用中位数
找到数据集“中心”的另一种方法是使用中位数,通过将数据集中的所有单个值从小到大排序并找到中值来获得。
由于其计算方式,中位数受异常值的影响较小,并且在存在异常值时可以更好地捕获分布的中心位置。
例如,请考虑下图,该图显示了特定社区中房屋的平方英尺:
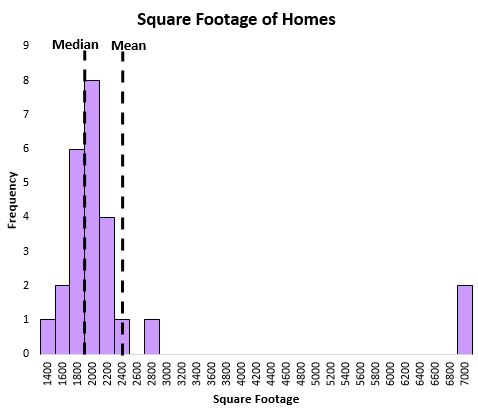
平均值很大程度上受到一些非常大的房屋的影响,而中位数则不然。因此,中位数比平均值更能捕捉该社区房屋的“典型”平方英尺。
进一步阅读:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多