人口对比样本:有什么区别?
在统计学中,我们通常希望收集数据,以便能够回答某些研究问题。
例如,我们可能想回答以下问题:
1.佛罗里达州迈阿密的家庭收入中位数是多少?
2.某个海龟种群的平均重量是多少?
3.某县支持某项法律的居民比例是多少?
在每种情况下,我们都想回答一个关于总体的问题,它代表了我们想要测量的所有可能的单个元素。
然而,我们不是收集总体中每个个体的数据,而是收集总体样本的数据,该样本代表总体的一部分。
人口:我们想要测量的每个可能的个体项目。
样本:人口的一部分。
这是三个介绍性示例中总体与样本的示例。
示例 1:佛罗里达州迈阿密的家庭收入中位数是多少?
整个人口可能由 500,000 个家庭组成,但我们只能收集总共 2,000 个家庭的样本数据。

2. 某个海龟种群的平均重量是多少?
总种群可能包括 800 只海龟,但我们只能收集 30 只海龟样本的数据。

3. 某县支持某项法律的居民比例是多少?
总人口可能有 50,000 人,但我们只能收集 1,000 人样本的数据。

为什么要使用样本?
我们通常收集样本数据而不是整个群体的数据有几个原因,包括:
1 .收集整个人口的数据需要很长时间。例如,如果我们想知道佛罗里达州迈阿密的家庭收入中位数,可能需要几个月甚至几年的时间才能收集每个家庭的收入。当我们收集所有这些数据时,人口可能已经发生变化,或者我们感兴趣的研究问题可能不再发生。
2. 收集整个人口的数据成本太高。收集总体中每个个体的数据通常成本太高,因此我们选择收集样本数据。
3. 收集整个人口的数据是不可能的。在许多情况下,根本不可能收集人口中每个人的数据。例如,找到特定感兴趣群体中的每只海龟并对其进行称重可能极其困难。
通过收集样本数据,我们能够更快、更低成本地收集有关特定人群的信息。
如果我们的样本能够代表总体,那么我们就可以将一个样本的结果以高置信度推广到更大的总体。
代表性样本的重要性
当我们从总体中收集样本时,理想情况下我们希望样本类似于总体的“迷你版本”。
例如,假设我们想了解某个学区共有 5000 名学生的学生的电影偏好。由于单独调查每个学生会花费太长时间,因此我们可以抽取 100 名学生作为样本,询问他们的偏好。
如果总学生人数为 50% 女孩和 50% 男孩,那么如果我们的样本包含 90% 男孩和仅 10% 女孩,则该样本将不具有代表性。
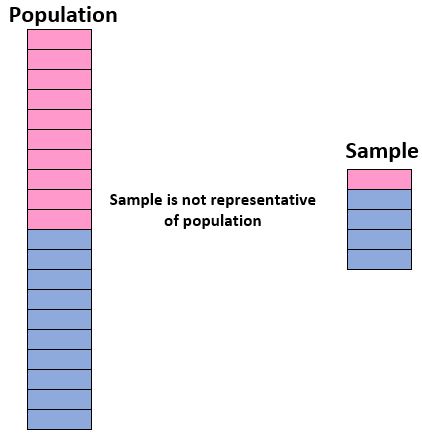
或者,如果总人口中新生、大二、大三和大四的比例相等,那么如果我们的样本只包括新生,那么它就没有代表性。
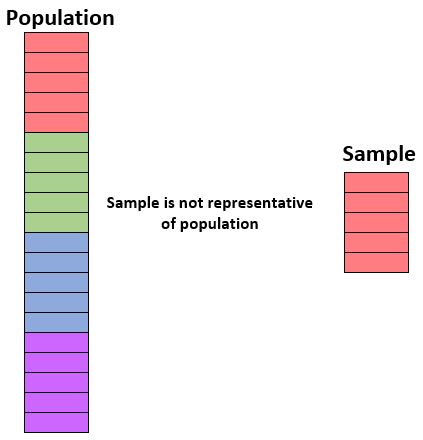
如果样本中个体的特征与总体中个体的特征密切匹配,则样本代表总体。
当这种情况发生时,我们可以自信地将样本的结果推广到总体。
如何获取样品
我们可以使用许多不同的方法来获取样本群体。
为了最大限度地提高获得代表性样本的机会,我们可以使用以下三种方法之一:
简单随机抽样:使用随机数生成器或随机选择方法随机选择个体。
系统随机抽样:将总体中的每个成员按一定顺序排列。选择一个随机起点并从n 中选择一个成员作为样本的一部分。
分层随机抽样:将总体分为几组。从每个组中随机选择一些成员作为样本的一部分。
在每种方法中,总体中的每个个体都有相同的概率被包含在样本中。这最大限度地提高了获得总体“迷你版”样本的机会。
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多