如何计算回归截距的置信区间
简单线性回归用于量化预测变量和响应变量之间的关系。
此方法查找与一组数据最“匹配”的行,并采用以下形式:
ŷ = b 0 + b 1 x
金子:
- ŷ : 估计响应值
- b 0 :回归线的原点
- b 1 :回归线的斜率
- x :预测变量的值
我们通常对 b 1的值感兴趣,它告诉我们与预测变量增加一单位相关的响应变量的平均变化。
然而,在极少数情况下,我们也对b0的值感兴趣,它告诉我们当预测变量为零时响应变量的平均值。
我们可以使用以下公式计算真实总体常数 β 0值的置信区间:
β 0的置信区间:b 0 ± t α/2, n-2 * se(b 0 )
以下示例展示了如何在实践中计算截距的置信区间。
示例:回归截距的置信区间
假设我们想要拟合一个简单的线性回归模型,使用学习时间作为预测变量,考试成绩作为特定班级 15 名学生的响应变量:
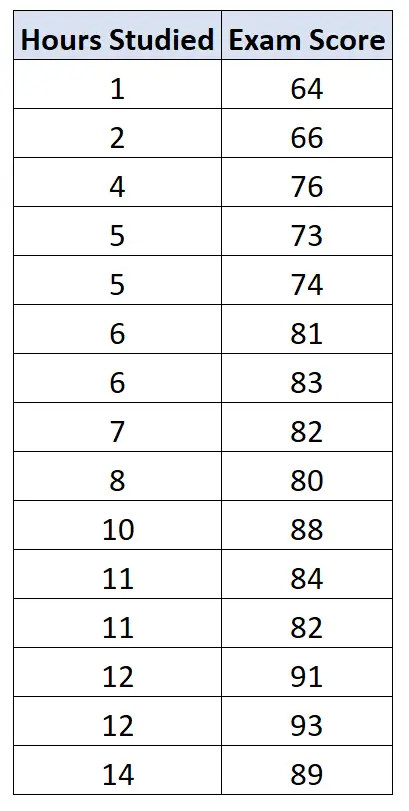
以下代码展示了如何在 R 中拟合这个简单的线性回归模型:
#create data frame df <- data. frame (hours=c(1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14), score=c(64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89)) #fit simple linear regression model fit <- lm(score ~ hours, data=df) #view summary of model summary(fit) Call: lm(formula = score ~ hours, data = df) Residuals: Min 1Q Median 3Q Max -5,140 -3,219 -1,193 2,816 5,772 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 65,334 2,106 31,023 1.41e-13 *** hours 1.982 0.248 7.995 2.25e-06 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.641 on 13 degrees of freedom Multiple R-squared: 0.831, Adjusted R-squared: 0.818 F-statistic: 63.91 on 1 and 13 DF, p-value: 2.253e-06
使用结果中的系数估计,我们可以编写拟合的简单线性回归模型,如下所示:
分数 = 65.334 + 1.982*(学习时间)
截距值为 65.334。这告诉我们,学习零小时的学生的估计平均考试成绩是65,334 。
我们可以使用以下公式计算截距的 95% 置信区间:
- β 0的 95% CI:b 0 ± t α/2,n-2 * se(b 0 )
- β 0的 95% CI:65.334 ± t 0.05/2.15-2 * 2.106
- β 0的 95% CI:65.334 ± 2.1604 * 2.106
- β 0的 95% CI:[60.78, 69.88]
我们对此的解释是,我们有 95% 的确定零学时学生的实际平均考试成绩在 60.78 到 69.88 之间。
注意:我们使用逆 t 分布计算器来查找临界 t 值,该值对应于 13 个自由度的 95% 置信水平。
计算回归截距置信区间的注意事项
在实践中,我们通常不会计算回归截距的置信区间,因为解释模型回归中的截距值通常没有意义。
例如,假设我们拟合一个回归模型,该模型使用篮球运动员的身高作为预测变量,将场均得分作为响应变量。
球员不可能身高为零英尺,因此在此模型中按字面解释拦截是没有意义的。
有无数这样的场景,其中预测变量不能取零值。因此,解释模型的原始值或为原点创建置信区间是没有意义的。
例如,考虑模型中的以下潜在预测变量:
- 房屋面积
- 汽车的长度
- 一个人的体重
这些预测变量中的每一个都不能取零值。因此,在任何这些情况下计算回归模型的起源的置信区间都是没有意义的。
其他资源
以下教程提供有关线性回归的其他信息:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多