统计中的残差是什么?
残差是回归分析中观测值与预测值之间的差异。
计算方法如下:
残差 = 观测值 – 预测值
回想一下,线性回归的目标是量化一个或多个预测变量与响应变量之间的关系。为此,线性回归会找到最“适合”数据的线,称为最小二乘回归线。
该线为数据集中的每个观测值生成预测,但回归线做出的预测不太可能与观测值完全匹配。
预测值和观测值之间的差异就是残差。如果我们绘制观测值并叠加拟合回归线,则每个观测值的残差将是观测值与回归线之间的垂直距离:

如果观测值大于回归线的预测值,则观测值具有正残差。
相反,如果观测值小于回归线的预测值,则观测值具有负残差。
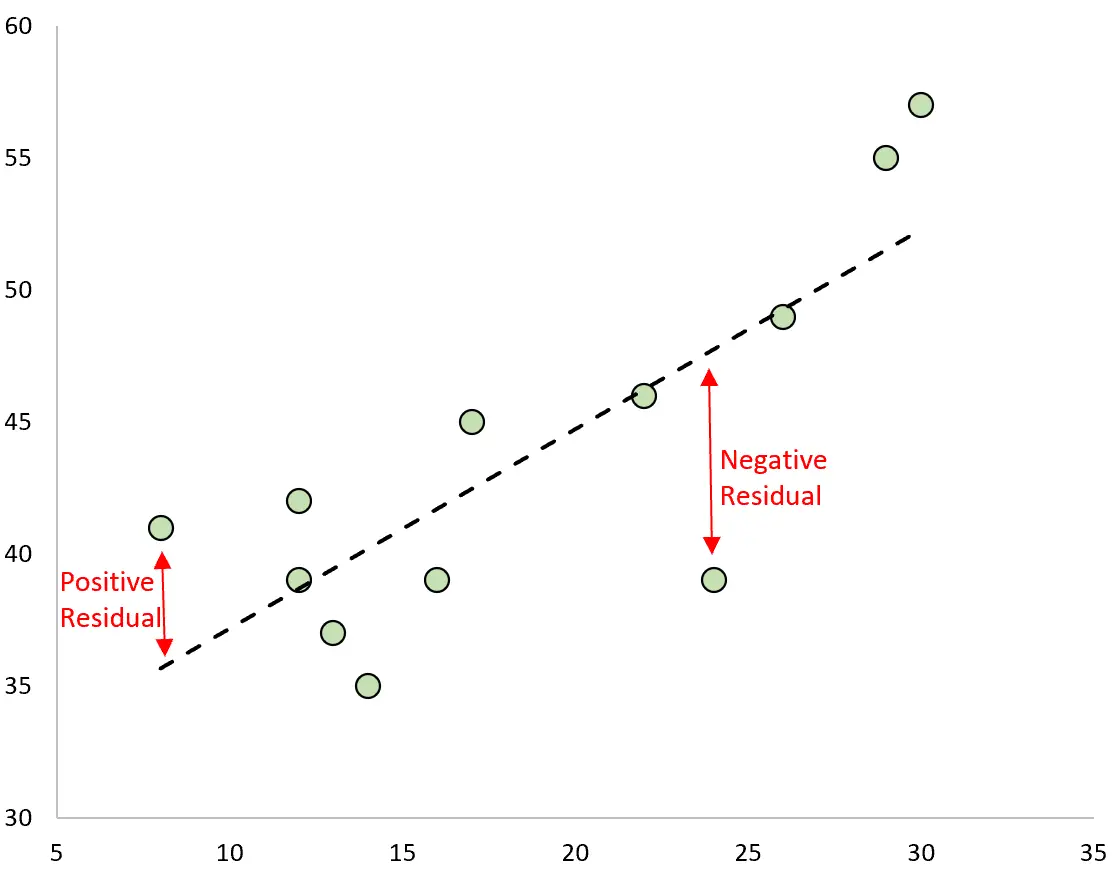
一些观测值将具有正残差,而另一些观测值将具有负残差,但所有残差加起来为零。
残差计算示例
假设我们有以下数据集,总共有 12 个观测值:
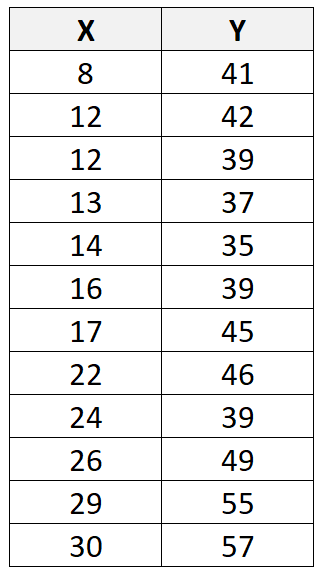
如果我们使用统计软件(如R 、 Excel 、 Python 、 Stata等)对该数据集拟合线性回归线,我们会发现最佳拟合线是:
y = 29.63 + 0.7553x
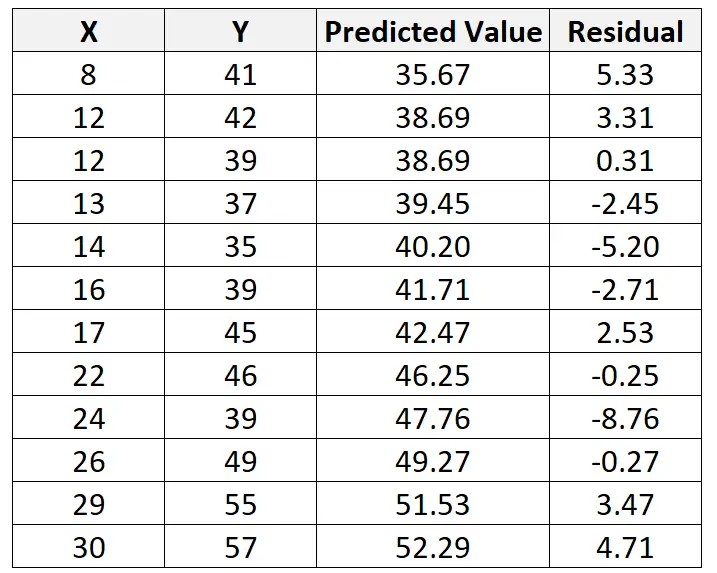
使用这条线,我们可以根据 X 的值计算每个 Y 值的预测值。例如,第一个观测值的预测值将是:
y = 29.63 + 0.7553*(8) = 35.67
然后我们可以计算该观测值的残差,如下所示:
残差 = 观测值 – 预测值 = 41 – 35.67 = 5.33
我们可以重复这个过程来找到每个观察的残差:
如果我们创建一个散点图来使用拟合回归线可视化观测值,我们将看到一些观测值位于线上方,而其他观测值位于线下方:
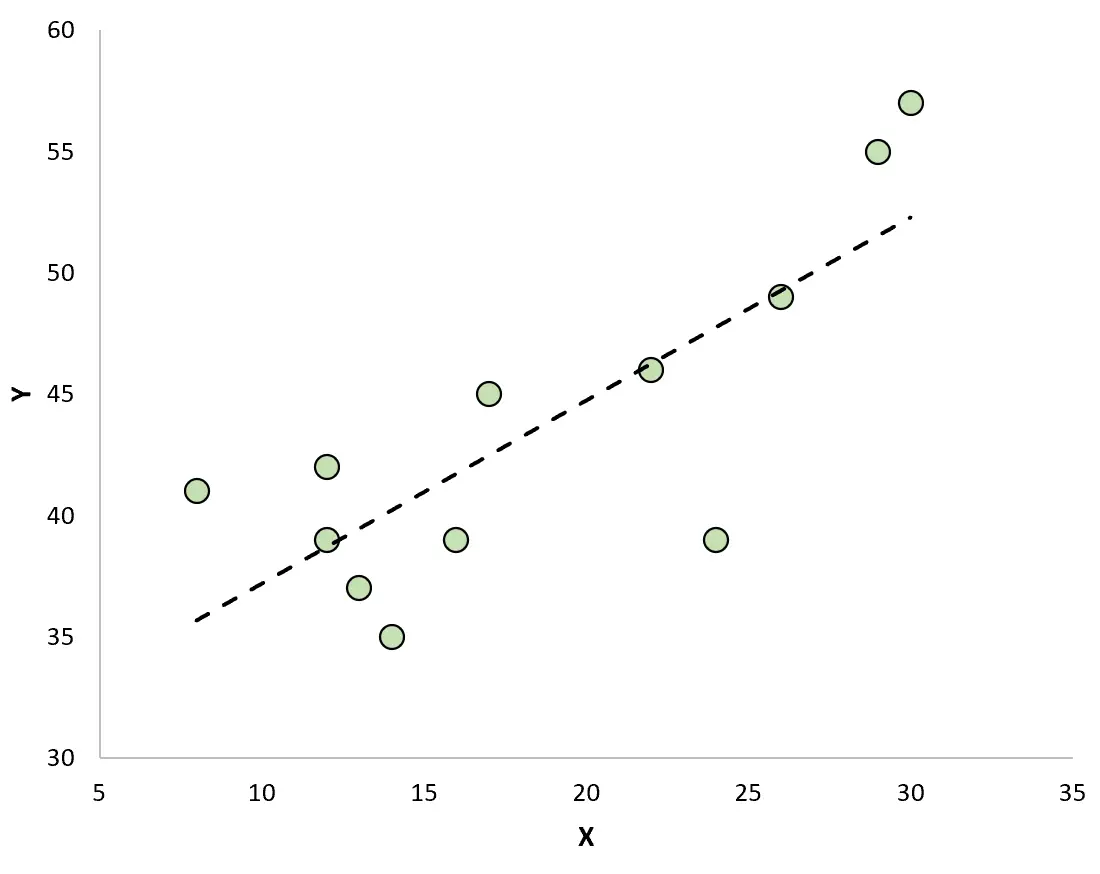
残留物的性质
残基具有以下性质:
- 数据集中的每个观测值都有相应的残差。因此,如果数据集总共包含 100 个观测值,则模型将生成 100 个预测值,从而总共产生 100 个残差。
- 所有残差之和为零。
- 残差的平均值为零。
残留物在实践中如何使用?
实际上,在回归中使用残差有以下三个不同的原因:
1. 评估模型的充分性。
一旦我们生成了拟合回归线,我们就可以计算残差平方和 (RSS) ,它是所有残差平方和。 RSS 越低,回归模型对数据的拟合效果越好。
2. 检查正态性假设。
线性回归的关键假设之一是残差呈正态分布。
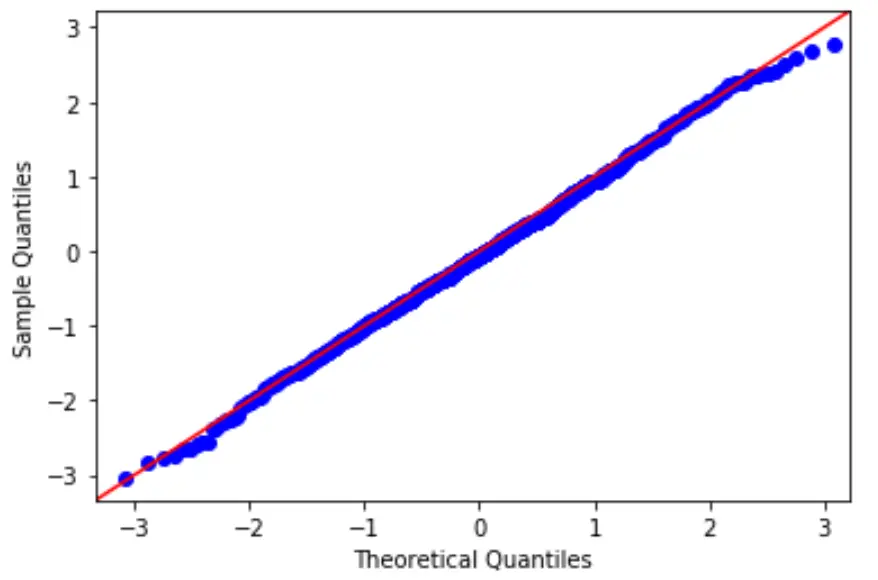
为了检验这个假设,我们可以创建 QQ 图,这是一种可以用来确定模型的残差是否服从正态分布的图。
如果图上的点大致形成一条直线对角线,则满足正态性假设。
3. 检查同方差假设。
线性回归的另一个关键假设是残差在 x 的每个水平上具有恒定方差。这称为同方差性。如果情况并非如此,残差就会出现异方差。
为了检查是否满足这个假设,我们可以创建一个残差图,它是一个散点图,显示相对于模型预测值的残差。
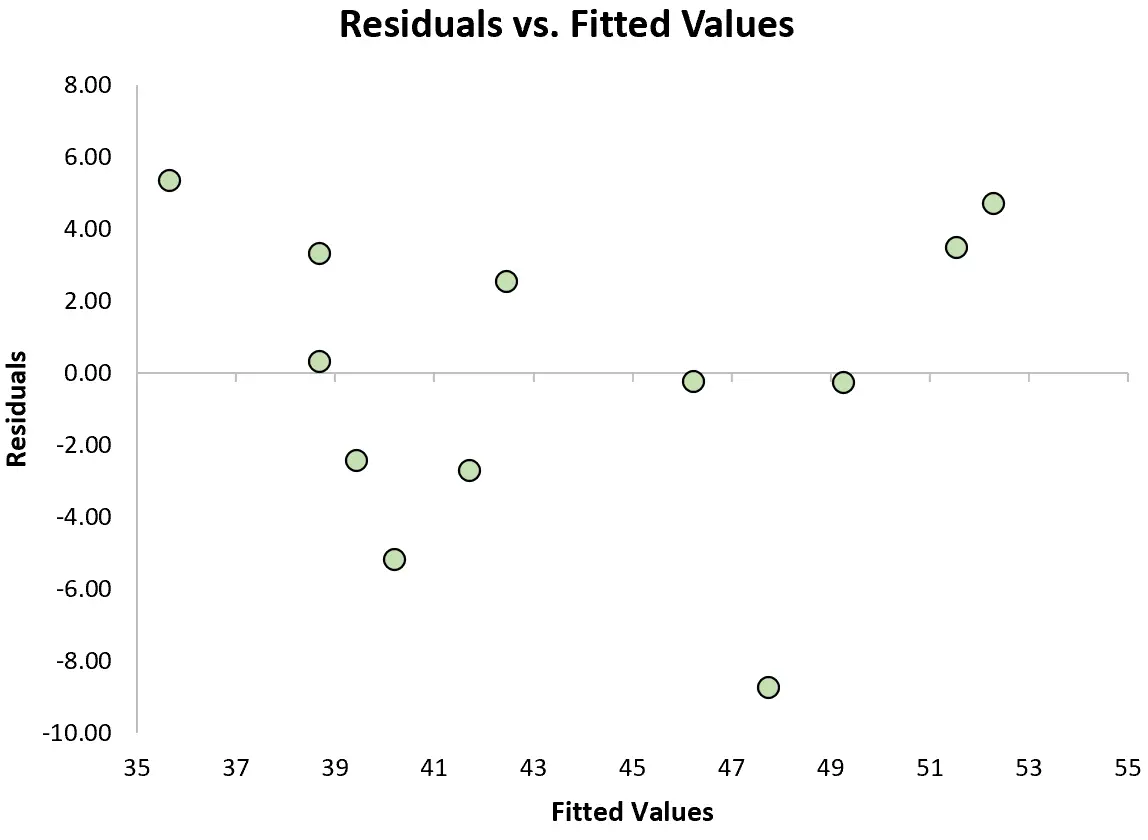
如果图中残差近似均匀分布在零附近,没有明显的趋势,那么我们通常说满足同方差假设。
其他资源
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多