如何在 sas 中进行模糊匹配(附示例)
通常,您可能希望根据不完全匹配的字符串在 SAS 中连接两组数据。
这通常称为模糊匹配。
在 SAS 中执行模糊匹配的最简单方法是将SOUNDEX函数与COMPGED函数结合使用。
这两个函数用于量化字符串之间的相似度,可以用来“匹配”相似的字符串。
以下示例展示了如何使用这些函数在 SAS 中执行模糊匹配。
示例:如何在 SAS 中执行模糊匹配
假设我们在 SAS 中有以下数据集,其中包含有关球队名称和各个篮球运动员得分的信息:
/*create first dataset*/
data data1;
input team $points;
datalines ;
Mavs 19
Nets 22
Kings 34
Warriors 19
Magic 32
;
run ;
/*view dataset*/
proc print data =data1;
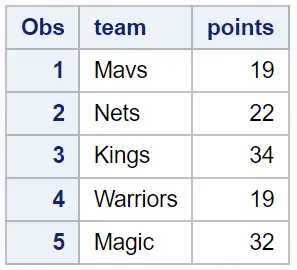
假设我们有另一个数据集,其中包含各个篮球运动员的球队名称和助攻数:
/*create second dataset*/
data data2;
input team $assists;
datalines ;
Netts 8
Majick 7
Keengs 8
Warriors 12
Mavs 4
;
run ;
/*view dataset*/
proc print data =data2;
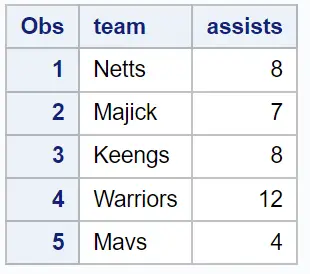
请注意,此数据集中的许多团队名称与之前数据集中的团队名称相似但不完全相同。
我们可以在 SAS 中使用以下语法来执行模糊匹配,并根据相似的团队名称将这两个数据集放在一起:
/*use fuzzy matching to merge datasets based on similar team names*/ data data3; setdata1 ; tmp1= soundex (team); /*encode team names from data1 */ do i=1 to nobs; set data2( rename =(team=team2)) point =i nobs =nobs; tmp2= soundex (team2); /*encode team names from data2* / dif= compged (tmp1,tmp2); /*determine similarity between team names */ if dif<=50 then do ; drop i tmp1 tmp2 dif; /*dr op unnecessary variables*/ output ; end ; end ; run ; /*view resulting dataset*/ proc print data=data3;
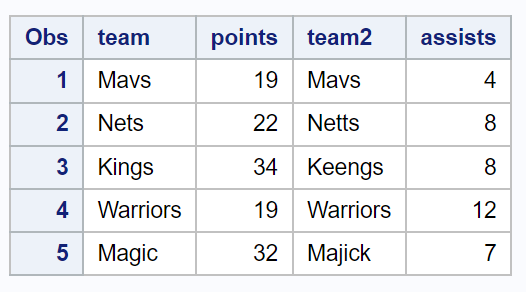
SOUNDEX和COMPGED函数能够根据团队名称的相似性来匹配团队名称,并生成合并两个数据集的最终数据集。
其他资源
以下教程解释了如何在 SAS 中执行其他常见任务:
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多