如何使用 pandas get dummies – pd.get_dummies
在统计学中,我们使用的数据集通常包含分类变量。
这些是带有名称或标签的变量。示例包括:
- 婚姻状况(“已婚”、“单身”、“离婚”)
- 吸烟状况(“吸烟者”、“非吸烟者”)
- 眼睛颜色(“蓝色”、“绿色”、“淡褐色”)
- 教育程度(例如“高中”、“学士学位”、“硕士学位”)
在调整机器学习算法(如线性回归、逻辑回归、随机森林等)时,我们经常将分类变量转换为虚拟变量,虚拟变量是用于表示数据分类的数值变量。
例如,假设我们有一个包含分类变量Gender的数据集。要使用该变量作为回归模型中的预测变量,首先需要将其转换为虚拟变量。
要创建这个虚拟变量,我们可以选择一个值(“男性”)来代表 0,另一个值(“女性”)代表 1:
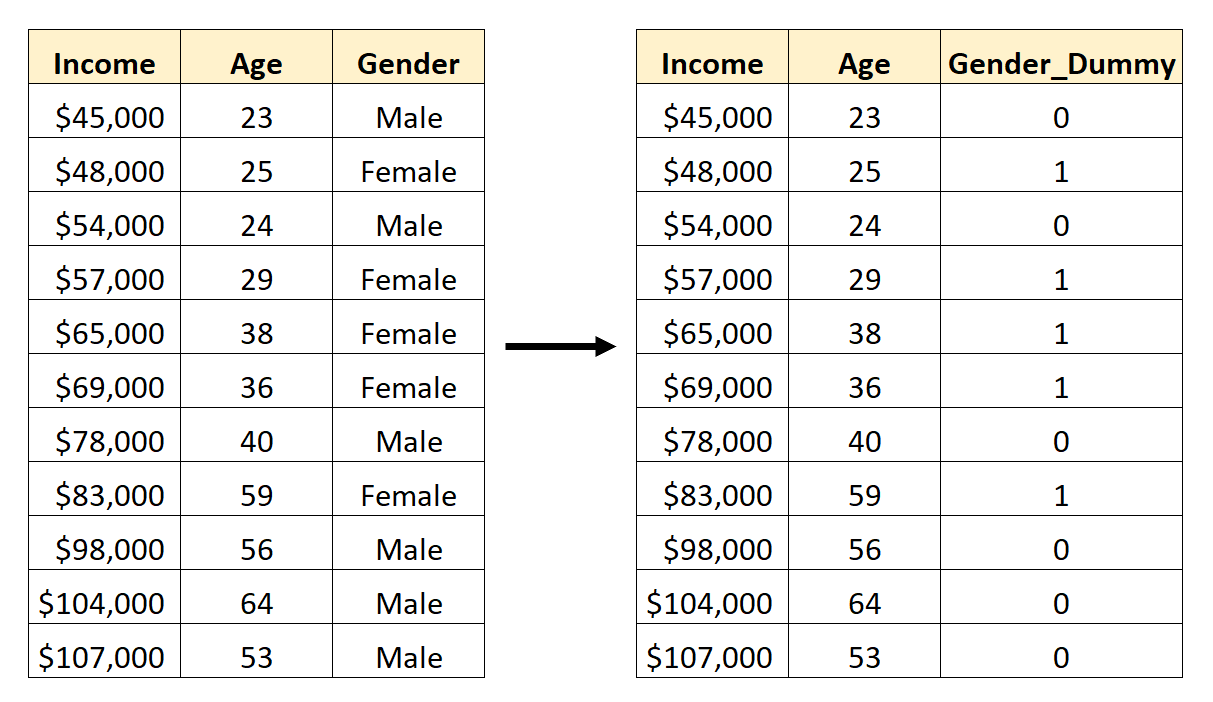
如何在 Pandas 中创建虚拟变量
要为 pandas DataFrame 中的变量创建虚拟变量,我们可以使用pandas.get_dummies()函数,该函数使用以下基本语法:
pandas.get_dummies(数据,前缀=无,列=无,drop_first=False)
金子:
- data :pandas DataFrame 的名称
- prefix :添加到新虚拟变量列开头的字符串
- columns :要转换为虚拟变量的列的名称
- drop_first :是否删除第一个虚拟变量列
以下示例展示了如何在实践中使用此功能。
示例 1:创建单个虚拟变量
假设我们有以下 pandas DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M']}) #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M
我们可以使用pd.get_dummies()函数将性别转换为虚拟变量:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender '], drop_first= True ) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1
性别列现在是一个虚拟变量,其中:
- 值0代表“女性”
- 值为1代表“男性”
示例 2:创建多个虚拟变量
假设我们有以下 pandas DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M'], ' college ': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']}) #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y
我们可以使用pd.get_dummies()函数将性别和大学转换为虚拟变量:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender ', ' college '], drop_first= True ) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1
性别列现在是一个虚拟变量,其中:
- 值0代表“女性”
- 值为1代表“男性”
大学列现在是一个虚拟变量,其中:
- 值0代表“否”大学
- 值1表示“是”上大学
其他资源
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多