什么是评估者间的可靠性? (定义&;示例)
在统计学中,评估者间的可靠性是衡量多个评估者或法官之间一致性程度的一种方法。
它用于评估测试中不同项目产生的响应的可靠性。如果测试的评估者间信度较低,则可能表明测试项目令人困惑、不清楚,甚至没有帮助。
有两种常见的方法来衡量评估者间的可靠性:
1. 同意率
衡量评分者间可靠性的简单方法是计算评分者同意的项目的百分比。
这称为一致性百分比,它始终介于 0 和 1 之间,其中 0 表示评分者之间没有达成一致,1 表示评分者之间完全一致。
例如,假设要求两名评委对测试中的 10 个项目的难度进行评分,评分范围为 1 到 3。结果如下所示:
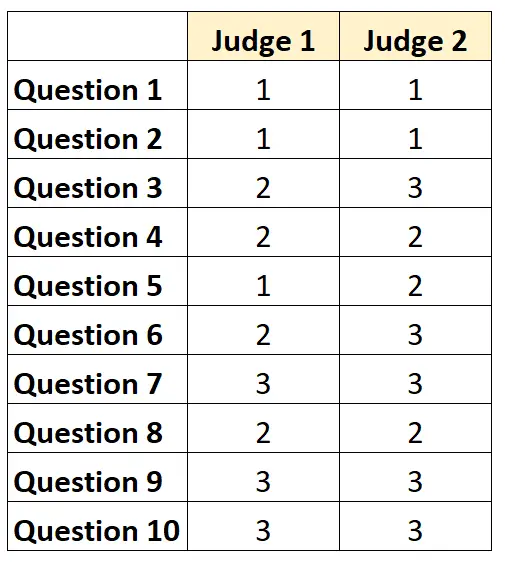
对于每个问题,如果两位法官都同意,我们可以写“1”;如果他们不同意,我们可以写“0”。
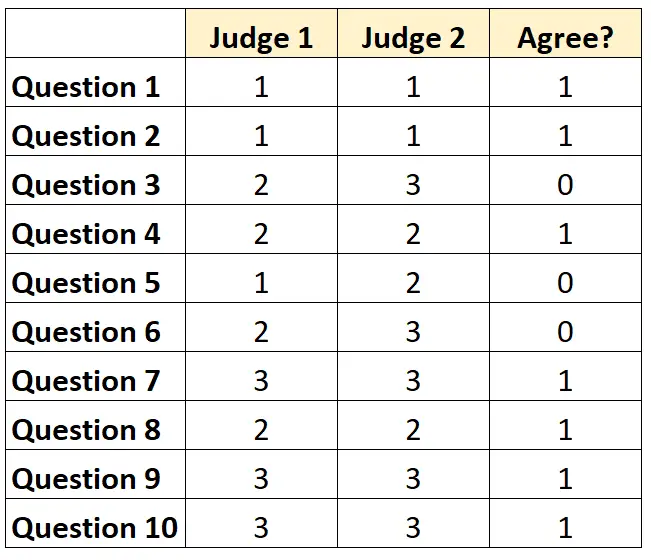
评委们一致同意的问题百分比是7/10= 70% 。
2.科恩的卡帕
衡量评估者间可靠性的最困难(也是最严格)的方法是使用Cohen 的 Kappa ,它计算评估者同意的项目的百分比,同时考虑到评估者可能仅就某些元素达成一致。幸运的是。
Cohen 的 kappa 公式计算如下:
k = (p o – p e ) / (1 – p e )
金子:
- p o :评估者之间观察到的相对一致性
- p e :机会一致的假设概率
Cohen 的 Kappa 始终介于 0 和 1 之间,其中 0 表示评分者之间没有达成一致,1 表示评分者之间完全一致。
有关如何计算 Cohen Kappa 的分步示例,请参阅本教程。
如何解释评估者间的可靠性
评分者间的可靠性越高,多个评委对分数相似的测试项目或问题的评分就越一致。
一般来说,在大多数领域,评估者之间的一致性必须达到至少 75%,测试才被认为是可靠的。然而,在特定领域可能需要更高的评估者间可靠性。
例如,对于确定电视节目的接收效果的测试来说,75% 的评分者间可靠性可能是可接受的。
另一方面,在多个医生判断是否应对特定患者使用某种治疗的医疗环境中,可能需要 95% 的评估者间可靠性。
请注意,在大多数学术环境和严谨的研究领域,Cohen 的 Kappa 用于计算评估者间的可靠性。
其他资源
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多