什么是关联数据? (解释和示例)
当两个数据集长度相等并且一个数据集中的每个观测值可以与另一个数据集中的观测值“配对”时,我们将这种情况称为配对数据。

对于要关联的两个数据集,重要的是一个数据集的每个观测值只能与另一数据集的一个观测值关联。
匹配数据示例
以下是匹配数据的一些示例:
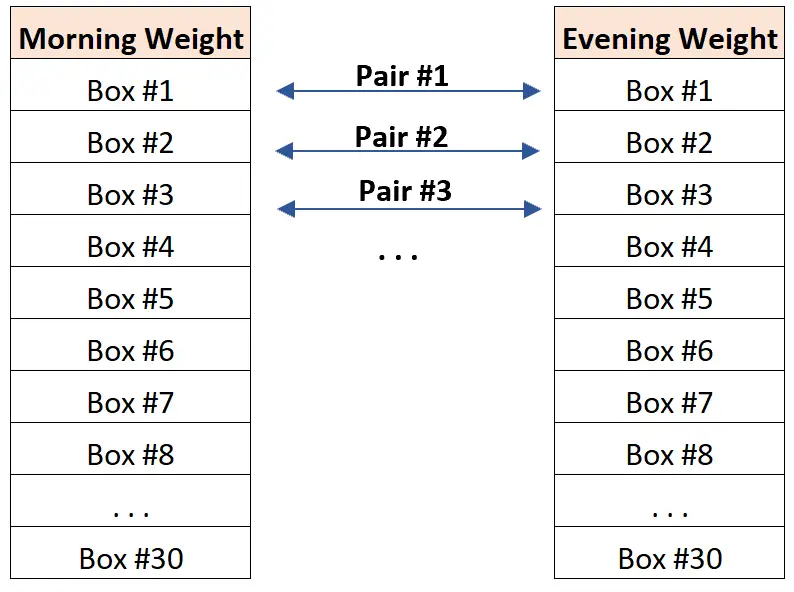
示例 1:重复测量。
假设研究人员想知道秤是否能够在给定仓库中全天对箱子进行称重。为了测试这一点,研究人员使用秤在早上和晚上对 30 个不同的盒子进行称重。
最终结果是两个数据集,其中每个盒子的早晨和晚上重量可以相互“匹配”。
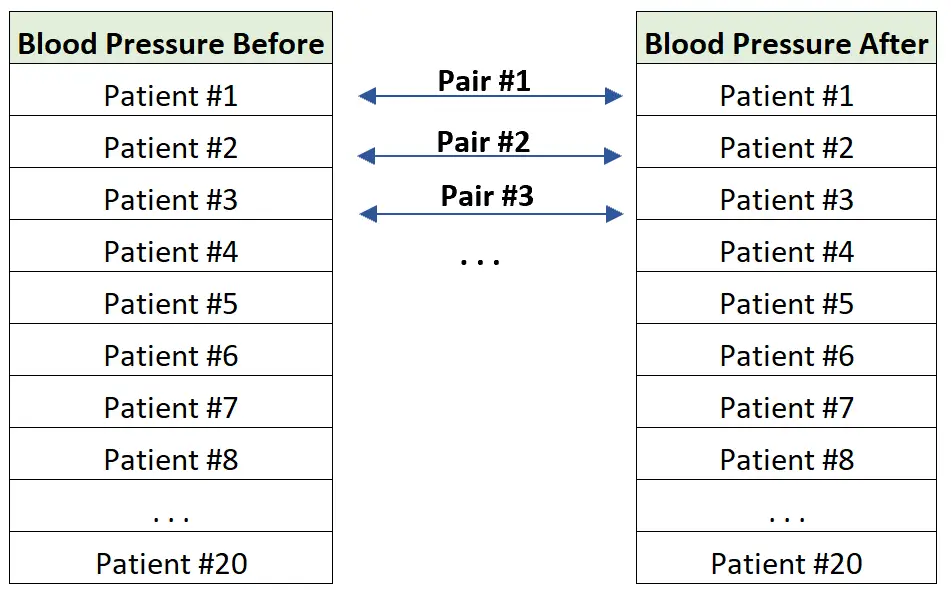
示例 2:前后测量。
医生想知道一种新药是否可以降低患者的血压。为了测试这一点,他测量了 20 名不同患者在使用该药物前后一周的血压。
最终的结果是两组数据,其中每个人前后的血压都可以与自己“匹配”。
如何分析配对数据
分析配对数据有两种常见方法:
1. 进行配对 t 检验。
分析配对数据的一种方法是执行配对样本 t 检验,当一个样本的每个观察值可以与另一个样本的观察值匹配时,它会比较两个样本的平均值。
该测试告诉我们两个数据集之间的平均值是否相等。
2. 计算两个数据集之间的相关性。
分析配对数据的另一种方法是计算两组数据之间的相关性。
这让我们了解两个数据集值之间关系的方向和强度。
配对数据和不匹配数据
与配对数据不同,当一个数据集的观测值无法与另一数据集的观测值唯一关联时,就会出现不配对数据。
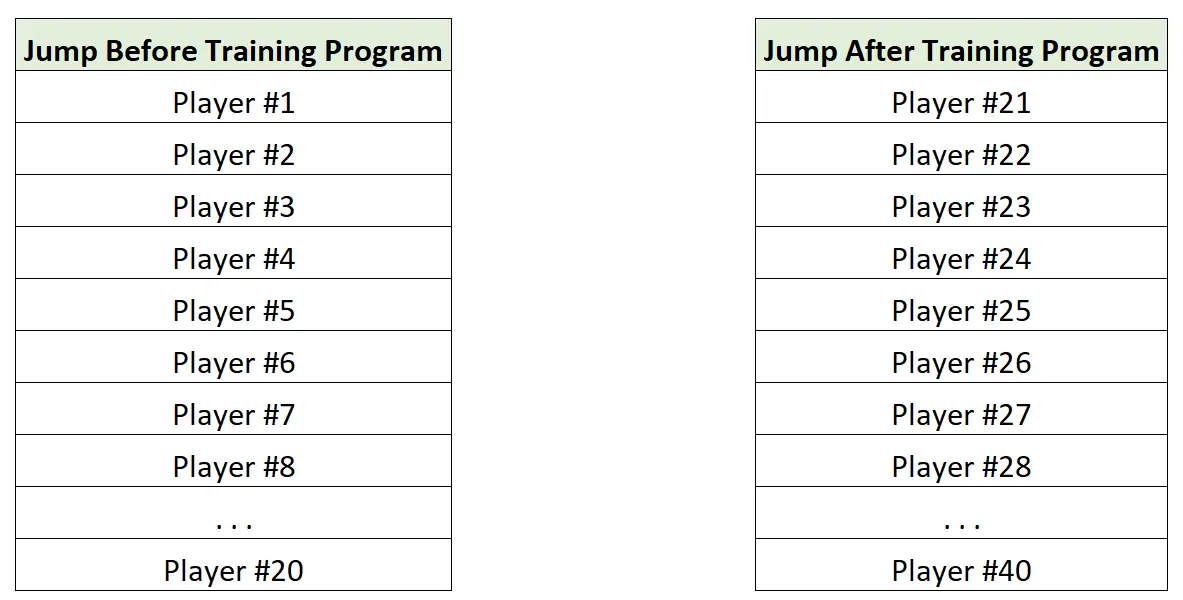
例如,假设研究人员想知道某个训练计划是否会提高篮球运动员的平均垂直弹跳力。
使用匹配数据测试这一点的一种方法是测量相同 20 名球员在使用训练计划之前和之后的最大垂直弹跳:

为了使用未配对的数据对此进行测试,研究人员测量了 20 名未使用该训练计划的球员的最大垂直弹跳力,然后测量了 20 名使用过该训练计划的不同球员的最大垂直弹跳力。 ‘训练:
在处理配对数据时,我们使用配对样本 t 检验来确定样本均值之间的差异是否不同。
当我们处理未配对的数据时,我们使用独立样本 t 检验来确定样本均值之间的差异是否不同。
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多