什么是高维数据? (定义和示例)
高维数据是指特征数量p大于观测数量N的数据集,通常写为p >> N。
例如,具有p = 6 个特征且只有N = 3 个观测值的数据集将被视为高维数据,因为特征数量大于观测值数量。
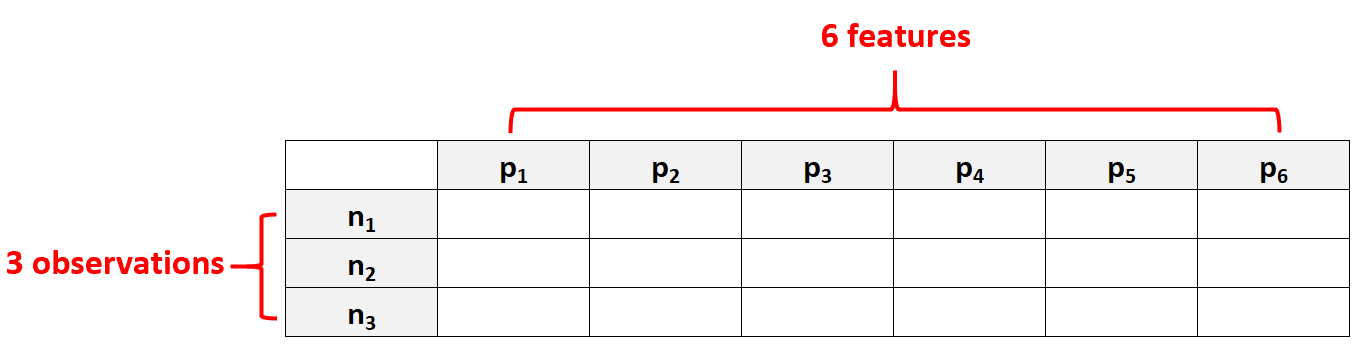
人们常犯的一个错误是假设“高维数据”仅仅意味着具有许多特征的数据集。然而,这是不正确的。一个数据集可能包含 10,000 个特征,但如果包含 100,000 个观测值,则它不是高维的。
注意:有关高维数据背后的数学的深入讨论,请参阅《统计学习要素》第 18 章。
为什么高维数据是一个问题?
当数据集中的特征数量超过观察数量时,我们永远不会得到确定性的答案。
换句话说,不可能找到一个可以描述预测变量 和响应变量之间关系的模型,因为我们没有足够的观测数据来训练模型。
高维数据示例
以下示例说明了不同领域中的高维数据集。
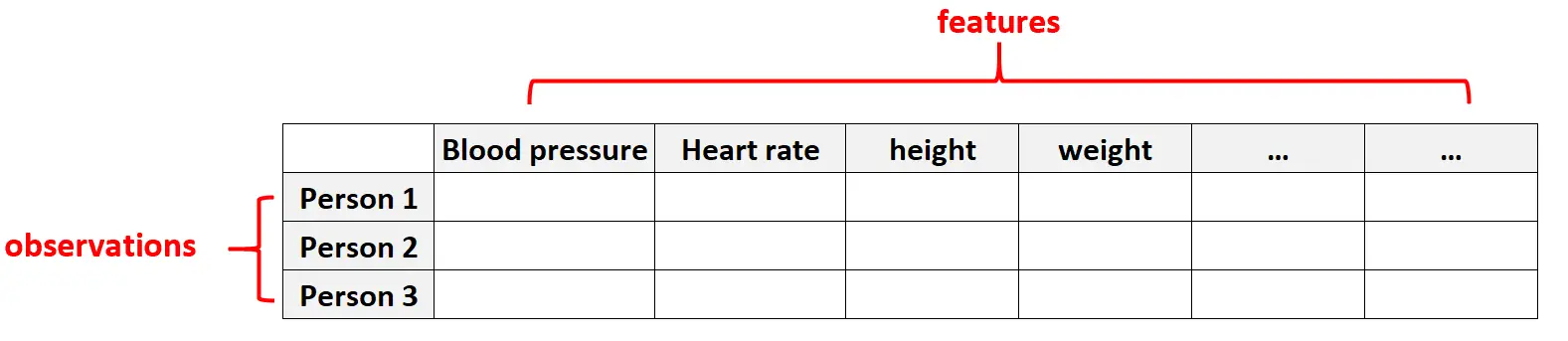
示例 1:健康数据
高维数据在医疗保健数据集中很常见,其中给定个体的特征数量可能非常巨大(即血压、静息心率、免疫系统状态、手术史、身高、体重、现有状况等)。
在这些数据集中,特征数量通常大于观测值数量。
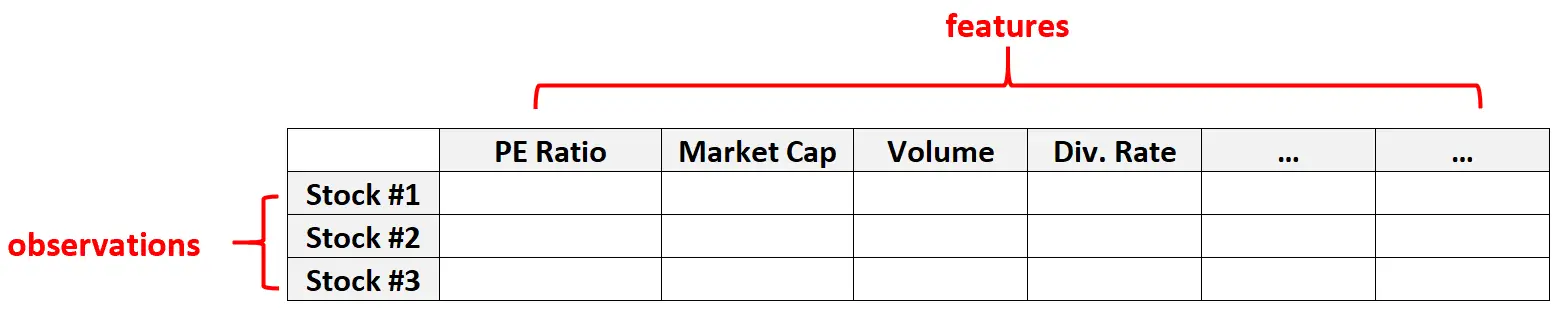
示例2:财务数据
高维数据在金融数据集中也很常见,其中给定股票的特征数量可能非常大(即市盈率、市值、交易量、股息率等)
在这些类型的数据集中,实体的数量通常远大于单个操作的数量。
示例 3:基因组学
高维数据在基因组学领域也很常见,其中给定个体的遗传特征的数量可能是巨大的。

如何处理大数据
处理高维数据有两种常见的方式:
1. 选择包含较少的功能。
避免处理高维数据的最明显方法是在数据集中包含更少的特征。
有多种方法可以决定从数据集中删除哪些特征,包括:
- 删除具有许多缺失值的特征:如果数据集中的给定列有许多缺失值,您可以将其完全删除而不会丢失太多信息。
- 删除低方差特征:如果数据集中的给定列的值变化很小,您也许可以将其删除,因为它不太可能提供与其他特征一样多的有关响应变量的有用信息。
- 删除与响应变量相关性较低的特征:如果某个特征与您感兴趣的响应变量不高度相关,您可以将其从数据集中删除,因为它不太可能是模型中有用的特征。
2.使用正则化方法。
处理高维数据而不从数据集中删除特征的另一种方法是使用正则化技术,例如:
这些技术中的每一种都可用于有效地处理高维数据。
您可以在此页面上找到所有统计机器学习教程的完整列表。
关于作者
本杰明·安德森博
大家好,我是本杰明,一位退休的统计学教授,后来成为 Statorials 的热心教师。 凭借在统计领域的丰富经验和专业知识,我渴望分享我的知识,通过 Statorials 增强学生的能力。了解更多