Regression oder klassifizierung: was ist der unterschied?
Algorithmen für maschinelles Lernen können in zwei verschiedene Typen unterteilt werden: überwachte und unüberwachte Lernalgorithmen .

Algorithmen für überwachtes Lernen können in zwei Typen eingeteilt werden:
1. Regression: Die Antwortvariable ist kontinuierlich.
Die Antwortvariable könnte beispielsweise sein:
- Gewicht
- Höhe
- Preis
- Zeit
- Gesamteinheiten
In jedem Fall versucht ein Regressionsmodell, eine kontinuierliche Größe vorherzusagen.
Regressionsbeispiel:
Nehmen wir an, wir haben einen Datensatz mit drei Variablen für 100 verschiedene Häuser: Quadratmeterzahl, Anzahl der Badezimmer und Verkaufspreis.
Wir könnten ein Regressionsmodell anpassen, das die Quadratmeterzahl und die Anzahl der Badezimmer als erklärende Variablen und den Verkaufspreis als Antwortvariable verwendet.
Mithilfe dieses Modells könnten wir dann den Verkaufspreis eines Hauses basierend auf der Quadratmeterzahl und der Anzahl der Badezimmer vorhersagen.
Dies ist ein Beispiel für ein Regressionsmodell, da die Antwortvariable (Verkaufspreis) kontinuierlich ist.
Die gebräuchlichste Methode zur Messung der Genauigkeit eines Regressionsmodells ist die Berechnung des quadratischen Mittelfehlers (Root Mean Square Error, RMSE), einer Metrik, die uns sagt, wie weit unsere vorhergesagten Werte im Durchschnitt von unseren beobachteten Werten in einem Modell entfernt sind. Es wird wie folgt berechnet:
RMSE = √ Σ(P i – O i ) 2 / n
Gold:
- Σ ist ein ausgefallenes Symbol, das „Summe“ bedeutet
- P i ist der vorhergesagte Wert für die i-te Beobachtung
- O i ist der beobachtete Wert für die i-te Beobachtung
- n ist die Stichprobengröße
Je kleiner der RMSE, desto besser kann ein Regressionsmodell die Daten anpassen.
2. Klassifizierung: Die Antwortvariable ist kategorisch.
Die Antwortvariable könnte beispielsweise die folgenden Werte annehmen:
- Männlich oder weiblich
- Erfolg oder Misserfolg
- Niedrig, mittel oder hoch
In jedem Fall versucht ein Klassifizierungsmodell, eine Klassenbezeichnung vorherzusagen.
Beispiel einer Klassifizierung:
Nehmen wir an, wir haben einen Datensatz mit drei Variablen für 100 verschiedene College-Basketballspieler: Durchschnitt der Punkte pro Spiel, Divisionsstufe und ob sie in die NBA eingezogen wurden oder nicht.
Wir könnten ein Klassifizierungsmodell anpassen, das durchschnittliche Punkte pro Spiel und pro Divisionsebene als erklärende Variablen verwendet und „entworfen“ als Antwortvariable verwendet.
Wir könnten dieses Modell dann verwenden, um anhand seines Punktedurchschnitts pro Spiel und seiner Divisionsstufe vorherzusagen, ob ein bestimmter Spieler in die NBA eingezogen wird oder nicht.
Dies ist ein Beispiel für ein Klassifizierungsmodell, da die Antwortvariable („geschrieben“) kategorisch ist. Mit anderen Worten: Es kann nur Werte in zwei verschiedenen Kategorien annehmen: „Geschrieben“ oder „Undrafted“.
Die gebräuchlichste Methode zur Messung der Genauigkeit eines Klassifizierungsmodells besteht einfach darin, den Prozentsatz der vom Modell vorgenommenen korrekten Klassifizierungen zu berechnen:
Genauigkeit = Korrekturklassifizierungen / Gesamtzahl der Klassifizierungsversuche * 100 %
Wenn ein Modell beispielsweise in 88 von 100 möglichen Fällen korrekt ermittelt, ob ein Spieler in die NBA gedraftet wird oder nicht, beträgt die Genauigkeit des Modells:
Genauigkeit = (88/100) * 100 % = 88 %
Je höher die Genauigkeit, desto besser kann ein Klassifizierungsmodell Ergebnisse vorhersagen.
Ähnlichkeiten zwischen Regression und Klassifizierung
Regressions- und Klassifizierungsalgorithmen ähneln sich auf folgende Weise:
- Bei beiden handelt es sich um überwachte Lernalgorithmen, das heißt, beide beinhalten eine Antwortvariable.
- Beide verwenden eine oder mehrere erklärende Variablen , um Modelle zur Vorhersage einer Reaktion zu erstellen.
- Beides kann verwendet werden, um zu verstehen, wie sich Änderungen der Werte erklärender Variablen auf die Werte einer Antwortvariablen auswirken.
Unterschiede zwischen Regression und Klassifizierung
Regressions- und Klassifizierungsalgorithmen unterscheiden sich in folgenden Punkten:
- Regressionsalgorithmen versuchen, eine kontinuierliche Menge vorherzusagen, und Klassifizierungsalgorithmen versuchen, eine Klassenbezeichnung vorherzusagen.
- Wie wir die Genauigkeit von Regressions- und Klassifizierungsmodellen messen, ist unterschiedlich.
Regression in Klassifizierung umwandeln
Es ist zu beachten, dass ein Regressionsproblem in ein Klassifizierungsproblem umgewandelt werden kann, indem die Antwortvariable einfach in Kompartimente diskretisiert wird .
Nehmen wir zum Beispiel an, wir haben einen Datensatz, der drei Variablen enthält: Quadratmeterzahl, Anzahl der Badezimmer und Verkaufspreis.
Wir könnten ein Regressionsmodell erstellen, das die Quadratmeterzahl und die Anzahl der Badezimmer verwendet, um die Verkaufspreise vorherzusagen.
Wir könnten den Verkaufspreis jedoch in drei verschiedene Klassen einteilen:
- 80.000 bis 160.000 US-Dollar: „Niedriger Verkaufspreis“
- 161.000 – 240.000 US-Dollar: „Durchschnittlicher Verkaufspreis“
- 241.000 – 320.000 US-Dollar: „Hoher Verkaufspreis“
Wir könnten dann die Quadratmeterzahl und die Anzahl der Badezimmer als erklärende Variablen verwenden, um vorherzusagen, in welche Klasse (niedrig, mittel oder hoch) der Verkaufspreis eines bestimmten Hauses fallen wird.
Dies wäre ein Beispiel für ein Klassifizierungsmodell, da wir versuchen, jedes Haus einer Klasse zuzuordnen.
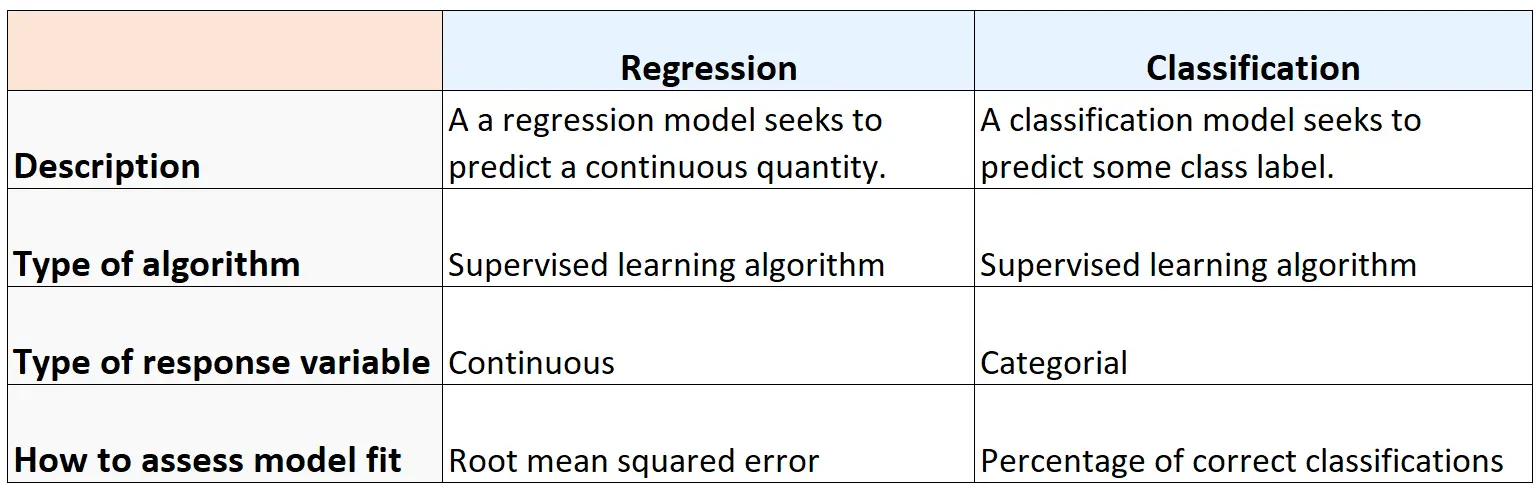
Zusammenfassung
Die folgende Tabelle fasst die Ähnlichkeiten und Unterschiede zwischen Regressions- und Klassifizierungsalgorithmen zusammen:
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen