Lineare diskriminanzanalyse in python (schritt für schritt)
Die lineare Diskriminanzanalyse ist eine Methode, die Sie verwenden können, wenn Sie über eine Reihe von Prädiktorvariablen verfügen und eine Antwortvariable in zwei oder mehr Klassen klassifizieren möchten.
Dieses Tutorial bietet ein schrittweises Beispiel für die Durchführung einer linearen Diskriminanzanalyse in Python.
Schritt 1: Laden Sie die erforderlichen Bibliotheken
Zuerst laden wir die für dieses Beispiel benötigten Funktionen und Bibliotheken:
from sklearn. model_selection import train_test_split
from sklearn. model_selection import RepeatedStratifiedKFold
from sklearn. model_selection import cross_val_score
from sklearn. discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import datasets
import matplotlib. pyplot as plt
import pandas as pd
import numpy as np
Schritt 2: Daten laden
Für dieses Beispiel verwenden wir den Iris- Datensatz aus der Sklearn-Bibliothek. Der folgende Code zeigt, wie dieser Datensatz geladen und zur einfacheren Verwendung in einen Pandas-DataFrame konvertiert wird:
#load iris dataset iris = datasets. load_iris () #convert dataset to pandas DataFrame df = pd.DataFrame(data = np.c_[iris[' data '], iris[' target ']], columns = iris[' feature_names '] + [' target ']) df[' species '] = pd. Categorical . from_codes (iris.target, iris.target_names) df.columns = [' s_length ', ' s_width ', ' p_length ', ' p_width ', ' target ', ' species '] #view first six rows of DataFrame df. head () s_length s_width p_length p_width target species 0 5.1 3.5 1.4 0.2 0.0 setosa 1 4.9 3.0 1.4 0.2 0.0 setosa 2 4.7 3.2 1.3 0.2 0.0 setosa 3 4.6 3.1 1.5 0.2 0.0 setosa 4 5.0 3.6 1.4 0.2 0.0 setosa #find how many total observations are in dataset len( df.index ) 150
Wir können sehen, dass der Datensatz insgesamt 150 Beobachtungen enthält.
Für dieses Beispiel erstellen wir ein lineares Diskriminanzanalysemodell, um zu klassifizieren, zu welcher Art eine bestimmte Blume gehört.
Wir werden die folgenden Prädiktorvariablen im Modell verwenden:
- Kelchlänge
- Kelchblattbreite
- Blütenblattlänge
- Blütenblattbreite
Und wir werden sie verwenden, um die Antwortvariable „Species“ vorherzusagen, die die folgenden drei möglichen Klassen unterstützt:
- setosa
- versicolor
- Virginia
Schritt 3: Passen Sie das LDA-Modell an
Als Nächstes passen wir das LDA-Modell mithilfe der LinearDiscriminantAnalsys -Funktion von sklearn an unsere Daten an:
#define predictor and response variables X = df[[' s_length ',' s_width ',' p_length ',' p_width ']] y = df[' species '] #Fit the LDA model model = LinearDiscriminantAnalysis() model. fit (x,y)
Schritt 4: Verwenden Sie das Modell, um Vorhersagen zu treffen
Sobald wir das Modell mithilfe unserer Daten angepasst haben, können wir die Leistung des Modells mithilfe einer wiederholten geschichteten k-fachen Kreuzvalidierung bewerten.
Für dieses Beispiel verwenden wir 10 Faltungen und 3 Wiederholungen:
#Define method to evaluate model
cv = RepeatedStratifiedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
#evaluate model
scores = cross_val_score(model, X, y, scoring=' accuracy ', cv=cv, n_jobs=-1)
print( np.mean (scores))
0.9777777777777779
Wir können sehen, dass das Modell eine durchschnittliche Genauigkeit von 97,78 % erreichte.
Wir können das Modell auch verwenden, um basierend auf den Eingabewerten vorherzusagen, zu welcher Klasse eine neue Blume gehört:
#define new observation new = [5, 3, 1, .4] #predict which class the new observation belongs to model. predict ([new]) array(['setosa'], dtype='<U10')
Wir sehen, dass das Modell vorhersagt, dass diese neue Beobachtung zu der Art namens Setosa gehört.
Schritt 5: Visualisieren Sie die Ergebnisse
Schließlich können wir ein LDA-Diagramm erstellen, um die linearen Diskriminanten des Modells zu visualisieren und zu visualisieren, wie gut es die drei verschiedenen Arten in unserem Datensatz trennt:
#define data to plot X = iris.data y = iris.target model = LinearDiscriminantAnalysis() data_plot = model. fit (x,y). transform (X) target_names = iris. target_names #create LDA plot plt. figure () colors = [' red ', ' green ', ' blue '] lw = 2 for color, i, target_name in zip(colors, [0, 1, 2], target_names): plt. scatter (data_plot[y == i, 0], data_plot[y == i, 1], alpha=.8, color=color, label=target_name) #add legend to plot plt. legend (loc=' best ', shadow= False , scatterpoints=1) #display LDA plot plt. show ()
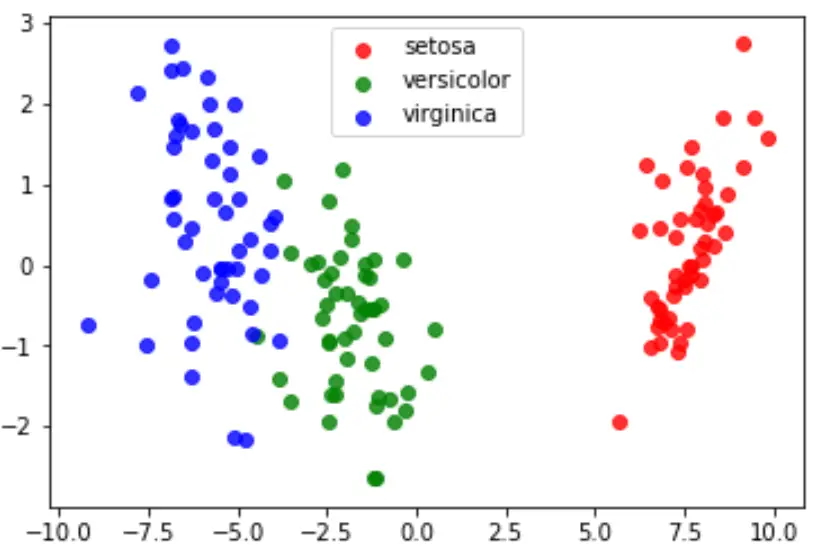
Den vollständigen Python-Code, der in diesem Tutorial verwendet wird, finden Sie hier .
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen