Einführung in die ridge-regression
Bei der gewöhnlichen multiplen linearen Regression verwenden wir einen Satz von p Prädiktorvariablen und eine Antwortvariable, um ein Modell der Form anzupassen:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
Gold:
- Y : Die Antwortvariable
- X j : die j -te Vorhersagevariable
- β j : Die durchschnittliche Auswirkung einer Erhöhung von X j um eine Einheit auf Y, wobei alle anderen Prädiktoren unverändert bleiben
- ε : Der Fehlerterm
Die Werte von β 0 , β 1 , B 2 , …, β p werden mit der Methode der kleinsten Quadrate ausgewählt, die die Summe der Quadrate der Residuen (RSS) minimiert:
RSS = Σ(y i – ŷ i ) 2
Gold:
- Σ : Ein griechisches Symbol für Summe
- y i : der tatsächliche Antwortwert für die i-te Beobachtung
- ŷ i : Der vorhergesagte Antwortwert basierend auf dem multiplen linearen Regressionsmodell
Wenn jedoch Prädiktorvariablen stark korreliert sind, kann Multikollinearität zu einem Problem werden. Dies kann dazu führen, dass Modellkoeffizientenschätzungen unzuverlässig werden und eine hohe Varianz aufweisen.
Eine Möglichkeit, dieses Problem zu umgehen, ohne bestimmte Prädiktorvariablen vollständig aus dem Modell zu entfernen, besteht darin, eine Methode namens „Ridge-Regression“ zu verwenden, die stattdessen darauf abzielt, Folgendes zu minimieren:
RSS + λΣβ j 2
wobei j von 1 nach p geht und λ ≥ 0 ist.
Dieser zweite Term in der Gleichung wird als Auszahlungsstrafe bezeichnet.
Wenn λ = 0, hat dieser Strafterm keine Auswirkung und die Ridge-Regression erzeugt die gleichen Koeffizientenschätzungen wie die Methode der kleinsten Quadrate. Wenn sich λ jedoch der Unendlichkeit nähert, wird der Schrumpfungsnachteil stärker und die Schätzungen des Spitzenregressionskoeffizienten nähern sich Null.
Im Allgemeinen fallen die Prädiktorvariablen mit dem geringsten Einfluss im Modell am schnellsten gegen Null.
Warum Ridge-Regression verwenden?
Der Vorteil der Ridge-Regression gegenüber der Regression der kleinsten Quadrate ist der Kompromiss zwischen Bias und Varianz .
Denken Sie daran, dass der mittlere quadratische Fehler (MSE) eine Metrik ist, mit der wir die Genauigkeit eines bestimmten Modells messen können. Er wird wie folgt berechnet:
MSE = Var( f̂( x 0 )) + [Bias( f̂( x 0 ))] 2 + Var(ε)
MSE = Varianz + Bias 2 + Irreduzibler Fehler
Die Grundidee der Ridge-Regression besteht darin, eine kleine Verzerrung einzuführen, sodass die Varianz deutlich reduziert werden kann, was zu einem insgesamt niedrigeren MSE führt.
Betrachten Sie zur Veranschaulichung die folgende Grafik:

Beachten Sie, dass mit zunehmendem λ die Varianz bei einem sehr geringen Anstieg der Vorspannung deutlich abnimmt. Ab einem bestimmten Punkt nimmt die Varianz jedoch weniger schnell ab und die Verringerung der Koeffizienten führt zu einer deutlichen Unterschätzung derselben, was zu einem starken Anstieg der Verzerrung führt.
Aus der Grafik können wir ersehen, dass der MSE des Tests am niedrigsten ist, wenn wir einen Wert für λ wählen, der einen optimalen Kompromiss zwischen Bias und Varianz ergibt.
Wenn λ = 0, hat der Strafterm in der Ridge-Regression keine Auswirkung und erzeugt daher die gleichen Koeffizientenschätzungen wie die Methode der kleinsten Quadrate. Durch Erhöhen von λ auf einen bestimmten Punkt können wir jedoch den Gesamt-MSE des Tests reduzieren.
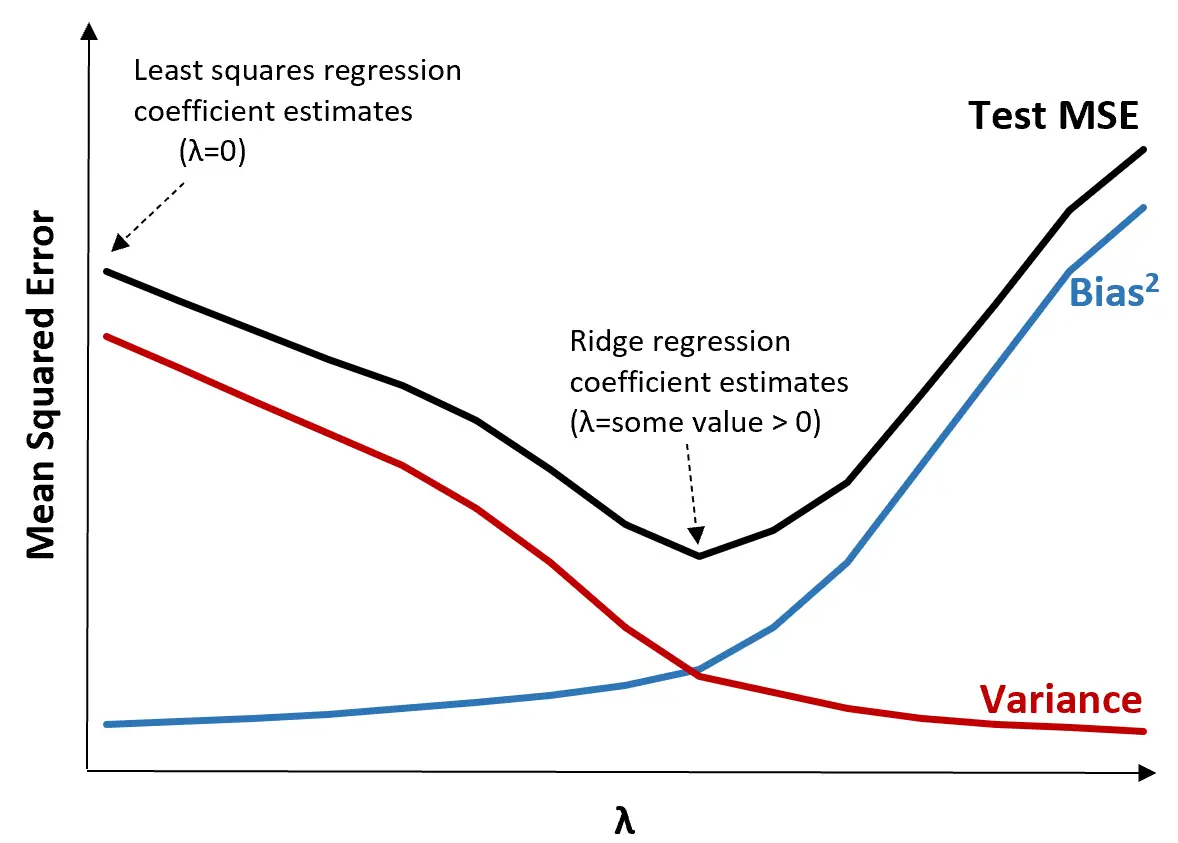
Dies bedeutet, dass die Modellanpassung mittels Ridge-Regression kleinere Testfehler erzeugt als die Modellanpassung mittels Regression der kleinsten Quadrate.
Schritte zur Durchführung der Ridge-Regression in der Praxis
Die folgenden Schritte können zur Durchführung einer Ridge-Regression verwendet werden:
Schritt 1: Berechnen Sie die Korrelationsmatrix und die VIF-Werte für die Prädiktorvariablen.
Zuerst müssen wir eine Korrelationsmatrix erstellen und die VIF-Werte (Varianz-Inflationsfaktor) für jede Prädiktorvariable berechnen.
Wenn wir eine starke Korrelation zwischen den Prädiktorvariablen und hohen VIF-Werten erkennen (einige Texte definieren einen „hohen“ VIF-Wert als 5, während andere 10 verwenden), dann ist die Ridge-Regression wahrscheinlich angemessen.
Wenn die Daten jedoch keine Multikollinearität aufweisen, ist die Durchführung einer Ridge-Regression möglicherweise überhaupt nicht erforderlich. Stattdessen können wir eine gewöhnliche Regression der kleinsten Quadrate durchführen.
Schritt 2: Standardisieren Sie jede Prädiktorvariable.
Bevor wir eine Ridge-Regression durchführen, müssen wir die Daten so skalieren, dass jede Prädiktorvariable einen Mittelwert von 0 und eine Standardabweichung von 1 hat. Dadurch wird sichergestellt, dass keine einzelne Prädiktorvariable einen übermäßigen Einfluss hat, wenn eine Ridge-Regression ausgeführt wird.
Schritt 3: Passen Sie das Ridge-Regressionsmodell an und wählen Sie einen Wert für λ.
Es gibt keine genaue Formel, mit der wir bestimmen können, welcher Wert für λ verwendet werden soll. In der Praxis gibt es zwei gängige Möglichkeiten, λ zu wählen:
(1) Erstellen Sie ein Ridge-Trace-Diagramm. Dies ist ein Diagramm, das die Werte der Koeffizientenschätzungen visualisiert, wenn λ in Richtung Unendlich ansteigt. Normalerweise wählen wir λ als den Wert, bei dem sich die meisten Koeffizientenschätzungen zu stabilisieren beginnen.
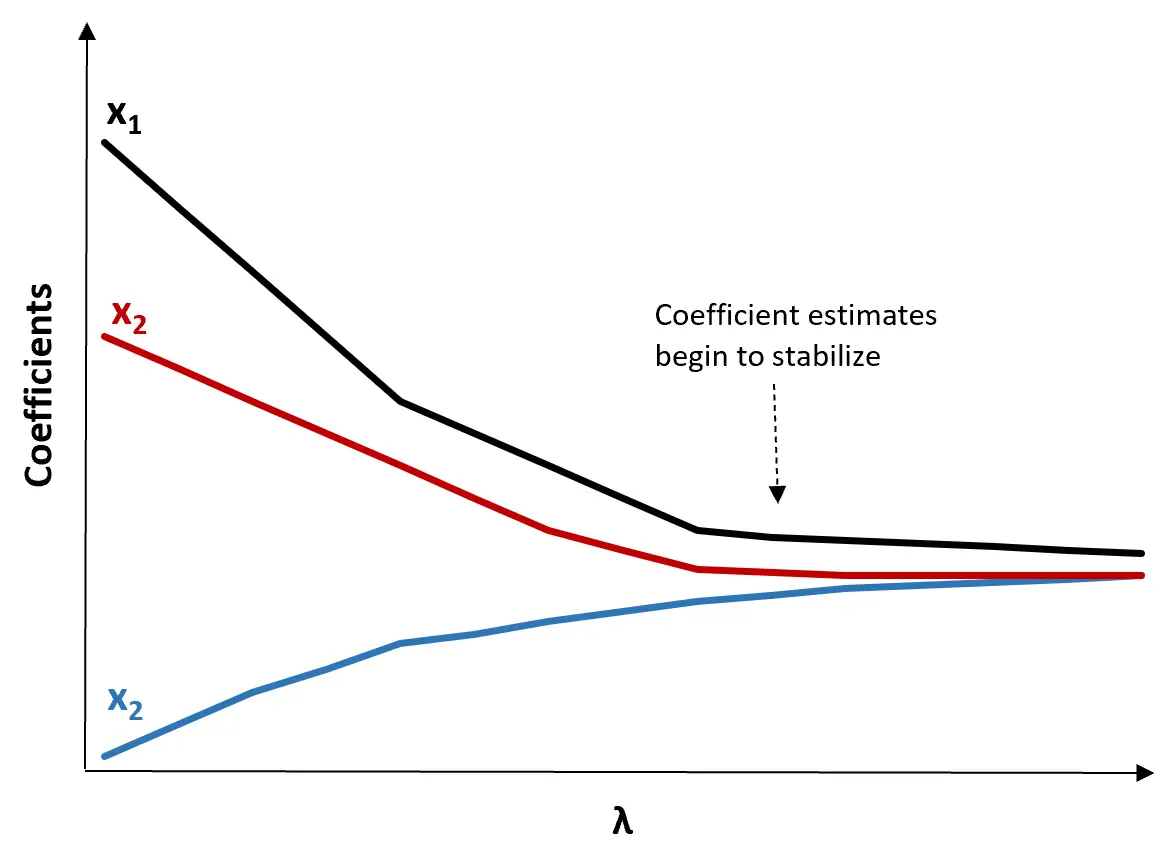
(2) Berechnen Sie den MSE-Test für jeden Wert von λ.
Eine andere Möglichkeit, λ auszuwählen, besteht darin, einfach den Test-MSE jedes Modells mit unterschiedlichen Werten von λ zu berechnen und λ als den Wert zu wählen, der den niedrigsten Test-MSE erzeugt.
Vor- und Nachteile der Ridge-Regression
Der größte Vorteil der Ridge-Regression besteht darin, dass sie bei Vorliegen von Multikollinearität einen niedrigeren mittleren quadratischen Testfehler (MSE) als die Methode der kleinsten Quadrate erzeugen kann.
Der größte Nachteil der Ridge-Regression besteht jedoch darin, dass sie keine Variablenauswahl durchführen kann, da sie alle Prädiktorvariablen in das endgültige Modell einbezieht. Da einige Prädiktoren sehr nahe an Null reduziert werden, kann dies die Interpretation der Modellergebnisse erschweren.
In der Praxis hat die Ridge-Regression das Potenzial, ein Modell zu erzeugen, das im Vergleich zu einem Modell der kleinsten Quadrate bessere Vorhersagen treffen kann, allerdings ist es oft schwieriger, die Ergebnisse des Modells zu interpretieren.
Je nachdem, ob Ihnen die Modellinterpretation oder die Prognosegenauigkeit wichtiger ist, können Sie in verschiedenen Szenarien die Methode der kleinsten Quadrate oder die Ridge-Regression verwenden.
Ridge-Regression in R & Python
In den folgenden Tutorials wird erläutert, wie eine Ridge-Regression in R und Python durchgeführt wird, den beiden am häufigsten verwendeten Sprachen zur Anpassung von Ridge-Regressionsmodellen:
Ridge-Regression in R (Schritt für Schritt)
Ridge-Regression in Python (Schritt für Schritt)
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen