Einführung in die lasso-regression
Bei der gewöhnlichen multiplen linearen Regression verwenden wir einen Satz von p Prädiktorvariablen und eine Antwortvariable, um ein Modell der Form anzupassen:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
Gold:
- Y : Die Antwortvariable
- X j : die j -te Vorhersagevariable
- β j : Die durchschnittliche Auswirkung einer Erhöhung von X j um eine Einheit auf Y, wobei alle anderen Prädiktoren unverändert bleiben
- ε : Der Fehlerterm
Die Werte von β 0 , β 1 , B 2 , …, β p werden mit der Methode der kleinsten Quadrate ausgewählt, die die Summe der Quadrate der Residuen (RSS) minimiert:
RSS = Σ(y i – ŷ i ) 2
Gold:
- Σ : Ein griechisches Symbol für Summe
- y i : der tatsächliche Antwortwert für die i-te Beobachtung
- ŷ i : Der vorhergesagte Antwortwert basierend auf dem multiplen linearen Regressionsmodell
Wenn jedoch Prädiktorvariablen stark korreliert sind, kann Multikollinearität zu einem Problem werden. Dies kann dazu führen, dass Modellkoeffizientenschätzungen unzuverlässig werden und eine hohe Varianz aufweisen. Das heißt, wenn das Modell auf einen neuen Datensatz angewendet wird, den es noch nie gesehen hat, wird es wahrscheinlich eine schlechte Leistung erbringen.
Eine Möglichkeit, dieses Problem zu umgehen, ist die Verwendung einer Methode namens Lasso-Regression , die stattdessen darauf abzielt, Folgendes zu minimieren:
RSS + λΣ|β j |
wobei j von 1 nach p geht und λ ≥ 0 ist.
Dieser zweite Term in der Gleichung wird als Auszahlungsstrafe bezeichnet.
Wenn λ = 0, hat dieser Strafterm keine Auswirkung und die Lasso-Regression erzeugt die gleichen Koeffizientenschätzungen wie die Methode der kleinsten Quadrate.
Wenn sich λ jedoch der Unendlichkeit nähert, wird die Entfernungsstrafe einflussreicher und Vorhersagevariablen, die nicht in das Modell importiert werden können, werden auf Null reduziert und einige werden sogar aus dem Modell entfernt.
Warum die Lasso-Regression verwenden?
Der Vorteil der Lasso-Regression gegenüber der Regression der kleinsten Quadrate ist der Bias-Varianz-Kompromiss .
Denken Sie daran, dass der mittlere quadratische Fehler (MSE) eine Metrik ist, mit der wir die Genauigkeit eines bestimmten Modells messen können. Er wird wie folgt berechnet:
MSE = Var( f̂( x 0 )) + [Bias( f̂( x 0 ))] 2 + Var(ε)
MSE = Varianz + Bias 2 + Irreduzibler Fehler
Die Grundidee der Lasso-Regression besteht darin, eine kleine Verzerrung einzuführen, sodass die Varianz deutlich reduziert werden kann, was zu einem insgesamt niedrigeren MSE führt.
Betrachten Sie zur Veranschaulichung die folgende Grafik:

Beachten Sie, dass mit zunehmendem λ die Varianz bei einem sehr geringen Anstieg der Vorspannung deutlich abnimmt. Ab einem bestimmten Punkt nimmt die Varianz jedoch weniger schnell ab und die Verringerung der Koeffizienten führt zu einer deutlichen Unterschätzung derselben, was zu einem starken Anstieg der Verzerrung führt.
Aus der Grafik können wir ersehen, dass der MSE des Tests am niedrigsten ist, wenn wir einen Wert für λ wählen, der einen optimalen Kompromiss zwischen Bias und Varianz ergibt.
Wenn λ = 0, hat der Strafterm in der Lasso-Regression keine Auswirkung und erzeugt daher die gleichen Koeffizientenschätzungen wie die Methode der kleinsten Quadrate. Durch Erhöhen von λ auf einen bestimmten Punkt können wir jedoch den Gesamt-MSE des Tests reduzieren.
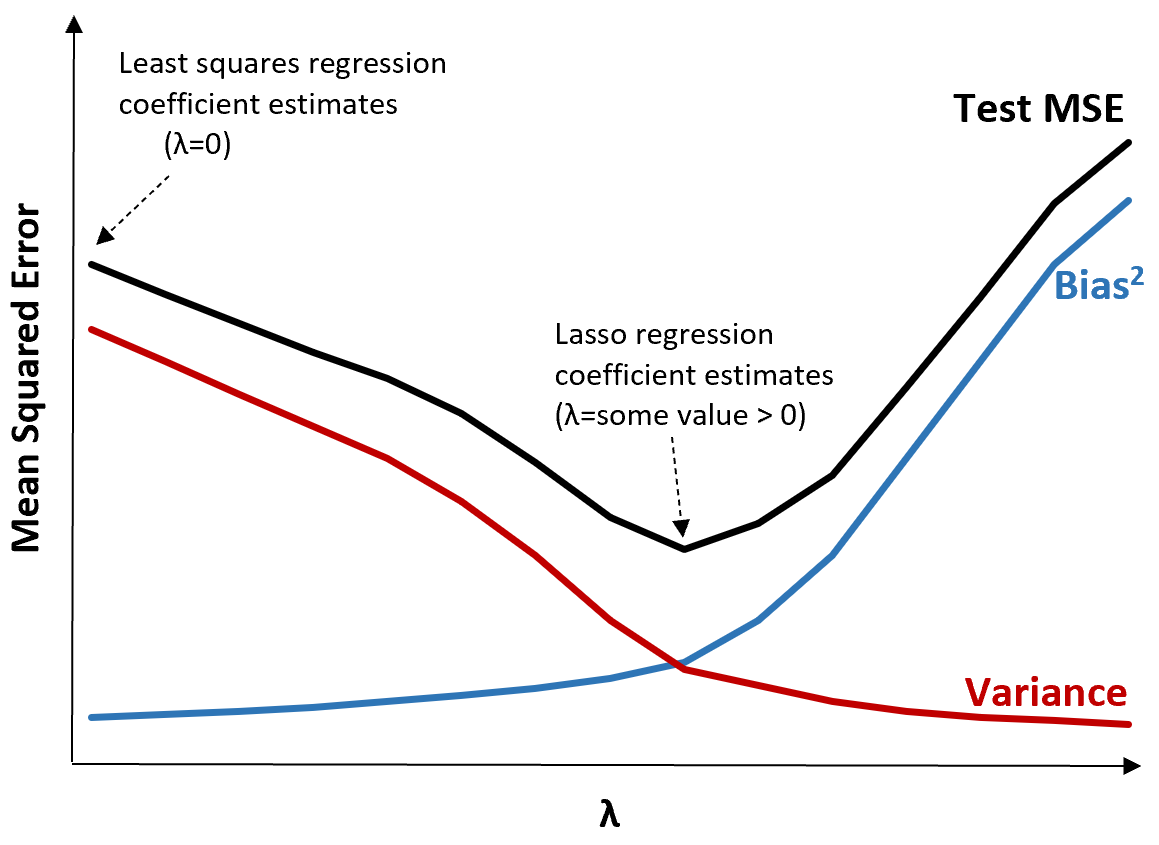
Dies bedeutet, dass die Modellanpassung durch Lasso-Regression zu kleineren Testfehlern führt als die Modellanpassung durch Regression der kleinsten Quadrate.
Lasso-Regression vs. Ridge-Regression
Lasso-Regression und Ridge-Regression werden beide als Regularisierungsmethoden bezeichnet, da sie beide versuchen, die verbleibende Quadratsumme (RSS) sowie einen bestimmten Strafterm zu minimieren.
Mit anderen Worten: Sie beschränken oder regulieren die Schätzungen der Modellkoeffizienten.
Die von ihnen verwendeten Strafbedingungen sind jedoch etwas anders:
- Die Lasso-Regression versucht, RSS + λΣ|β j | zu minimieren
- Die Ridge-Regression versucht, RSS + λΣβ j 2 zu minimieren
Wenn wir die Ridge-Regression verwenden, werden die Koeffizienten jedes Prädiktors auf Null reduziert, aber keiner von ihnen kann vollständig auf Null gehen.
Wenn wir umgekehrt die Lasso-Regression verwenden, ist es möglich, dass einige Koeffizienten vollständig Null werden, wenn λ groß genug wird.
Technisch gesehen ist die Lasso-Regression in der Lage, „sparse“-Modelle zu erzeugen, d. h. Modelle, die nur eine Teilmenge von Prädiktorvariablen enthalten.
Dies wirft die Frage auf: Ist die Ridge-Regression oder die Lasso-Regression besser?
Die Antwort: Es kommt darauf an!
In Fällen, in denen nur wenige Prädiktorvariablen signifikant sind, funktioniert die Lasso-Regression tendenziell besser, da sie in der Lage ist, unbedeutende Variablen vollständig auf Null zu reduzieren und aus dem Modell zu entfernen.
Wenn jedoch viele Prädiktorvariablen im Modell signifikant sind und ihre Koeffizienten ungefähr gleich sind, funktioniert die Ridge-Regression tendenziell besser, da alle Prädiktoren im Modell bleiben.
Um zu bestimmen, welches Modell am effektivsten Vorhersagen treffen kann, führen wir eine k-fache Kreuzvalidierung durch. Welches Modell den niedrigsten mittleren quadratischen Fehler (MSE) erzeugt, ist das beste zu verwendende Modell.
Schritte zur Durchführung einer Lasso-Regression in der Praxis
Die folgenden Schritte können verwendet werden, um eine Lasso-Regression durchzuführen:
Schritt 1: Berechnen Sie die Korrelationsmatrix und die VIF-Werte für die Prädiktorvariablen.
Zuerst müssen wir eine Korrelationsmatrix erstellen und die VIF-Werte (Varianz-Inflationsfaktor) für jede Prädiktorvariable berechnen.
Wenn wir eine starke Korrelation zwischen den Prädiktorvariablen und hohen VIF-Werten feststellen (einige Texte definieren einen „hohen“ VIF-Wert als 5, während andere 10 verwenden), dann ist die Lasso-Regression wahrscheinlich angemessen.
Wenn die Daten jedoch keine Multikollinearität aufweisen, besteht möglicherweise überhaupt keine Notwendigkeit, eine Lasso-Regression durchzuführen. Stattdessen können wir eine gewöhnliche Regression der kleinsten Quadrate durchführen.
Schritt 2: Passen Sie das Lasso-Regressionsmodell an und wählen Sie einen Wert für λ.
Sobald wir festgestellt haben, dass die Lasso-Regression angemessen ist, können wir das Modell anpassen (unter Verwendung gängiger Programmiersprachen wie R oder Python) und dabei den optimalen Wert für λ verwenden.
Um den optimalen Wert für λ zu bestimmen, können wir mehrere Modelle mit unterschiedlichen Werten für λ anpassen und λ als den Wert wählen, der den niedrigsten MSE-Test ergibt.
Schritt 3: Vergleichen Sie die Lasso-Regression mit der Ridge-Regression und der gewöhnlichen Regression der kleinsten Quadrate.
Schließlich können wir unser Lasso-Regressionsmodell mit einem Ridge-Regressionsmodell und einem Regressionsmodell der kleinsten Quadrate vergleichen, um mithilfe der k-fachen Kreuzvalidierung zu bestimmen, welches Modell den niedrigsten MSE-Test liefert.
Abhängig von der Beziehung zwischen den Prädiktorvariablen und der Antwortvariablen ist es durchaus möglich, dass eines dieser drei Modelle in verschiedenen Szenarien die anderen übertrifft.
Lasso-Regression in R & Python
Die folgenden Tutorials erklären, wie man eine Lasso-Regression in R und Python durchführt:
Lasso-Regression in R (Schritt für Schritt)
Lasso-Regression in Python (Schritt für Schritt)
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen