Was gelten als rohdaten? (definition & beispiele)
In der Statistik beziehen sich Rohdaten auf Daten, die direkt aus einer Primärquelle erhoben und in keiner Weise verarbeitet wurden.
Bei jeder Art von Datenanalyseprojekt besteht der erste Schritt darin, Rohdaten zu sammeln. Sobald diese Daten erfasst sind, können sie bereinigt, transformiert, zusammengefasst und visualisiert werden.
Der Vorteil des Sammelns von Rohdaten besteht darin, dass man sie letztendlich nutzen kann, um bestimmte Phänomene besser zu verstehen oder eine Art Vorhersagemodell zu erstellen.
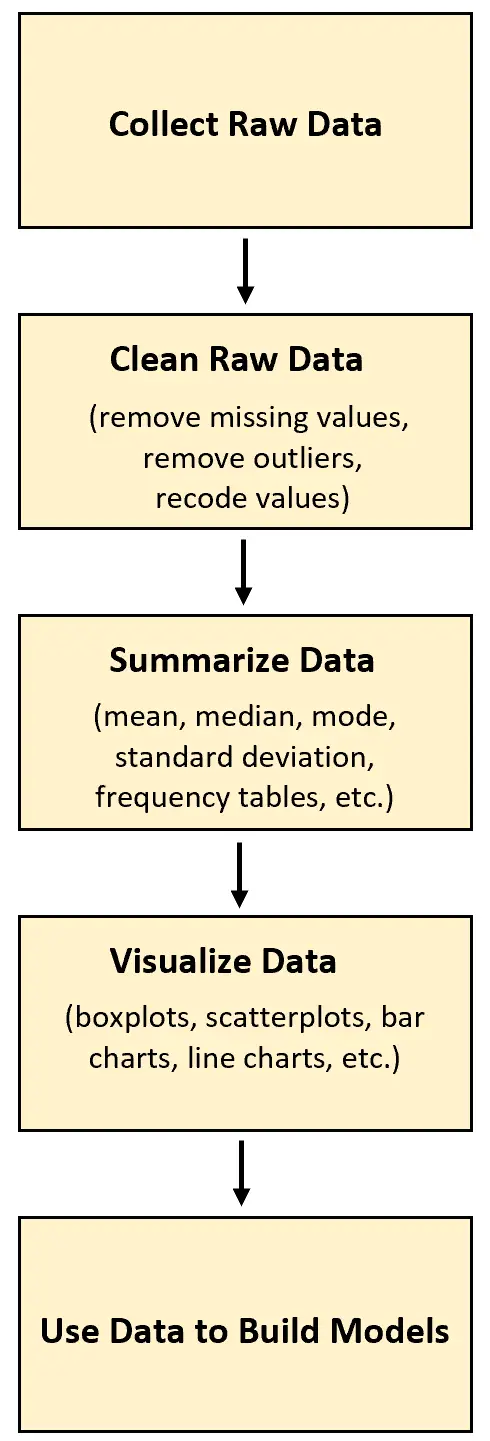
Das folgende Beispiel veranschaulicht, wie Rohdaten gesammelt und im wirklichen Leben verwendet werden können.
Beispiel: Erhebung und Nutzung von Rohdaten
Sport ist ein Bereich, in dem häufig Rohdaten gesammelt werden. Beispielsweise können Rohdaten für verschiedene Statistiken zu professionellen Basketballspielern gesammelt werden.
Schritt 1: Rohdaten sammeln
Stellen Sie sich vor, ein Basketball-Scout sammelt die folgenden Rohdaten für 10 Spieler einer professionellen Basketballmannschaft: 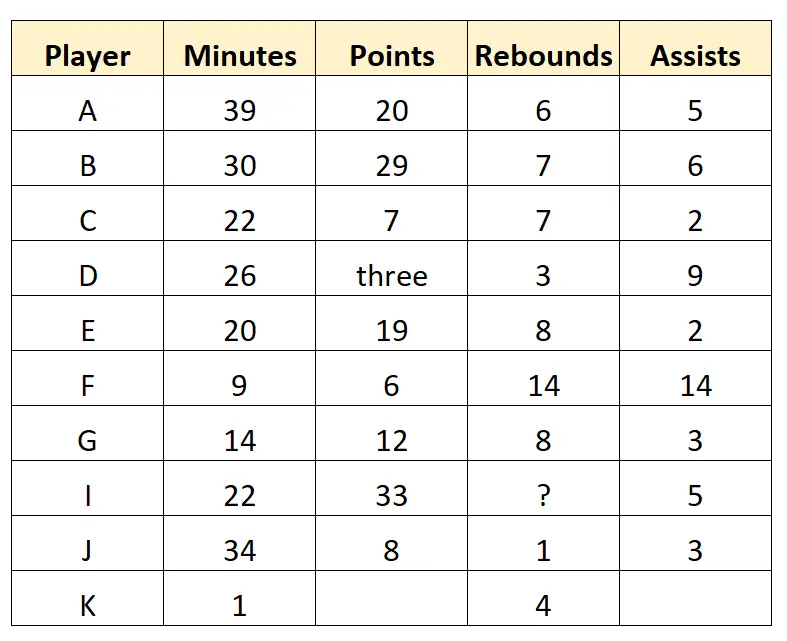
Dieser Datensatz stellt die Rohdaten dar, da diese direkt vom Scout erfasst und in keiner Weise bereinigt oder verarbeitet wurden.
Schritt 2: Bereinigen Sie die Rohdaten
Bevor der Scout diese Daten zum Erstellen von Übersichtstabellen, Diagrammen oder anderen Dingen verwenden kann, muss er zunächst alle fehlenden Werte entfernen und alle „unreinen“ Datenwerte bereinigen.
Beispielsweise können wir im Datensatz mehrere Werte entdecken, die transformiert oder entfernt werden müssen:
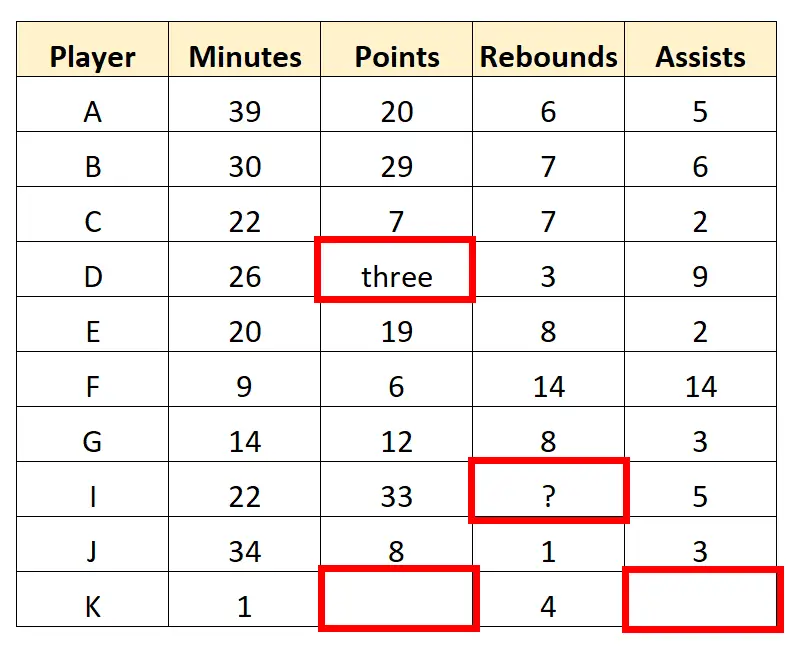
Der Scout kann beschließen, die letzte Zeile vollständig zu entfernen, da in ihr mehrere Werte fehlen. Anschließend können die Zeichenwerte im Datensatz bereinigt werden, um die folgenden „sauberen“ Daten zu erhalten:
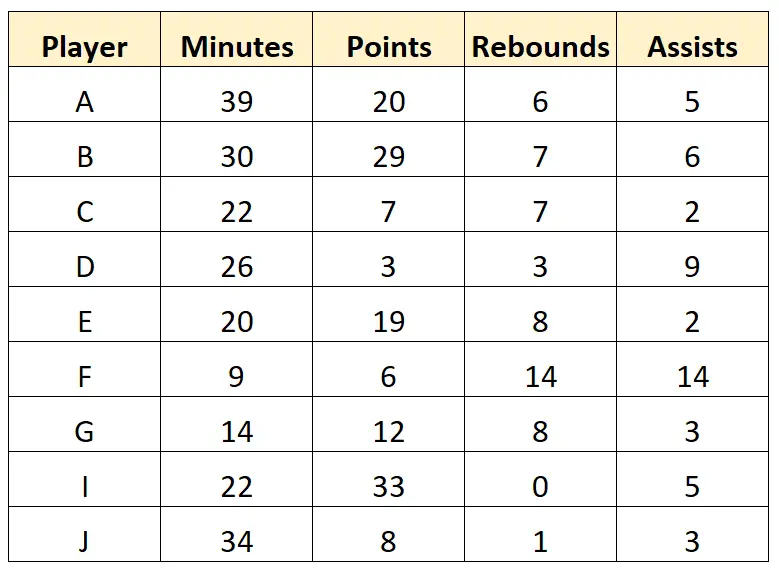
Schritt 3: Fassen Sie die Daten zusammen
Sobald die Daten bereinigt sind, kann der Scout jede Variable im Datensatz zusammenfassen. Es könnte beispielsweise die folgende zusammenfassende Statistik für die Variable „Minuten“ berechnen:
- Durchschnitt : 24 Minuten
- Median : 22 Minuten
- Standardabweichung : 9,45 Minuten
Schritt 4: Visualisieren Sie die Daten
Der Scout kann dann die Variablen im Datensatz visualisieren, um die Datenwerte besser zu verstehen.
Er könnte beispielsweise das folgende Balkendiagramm erstellen, um die von jedem Spieler insgesamt gespielten Minuten zu visualisieren:
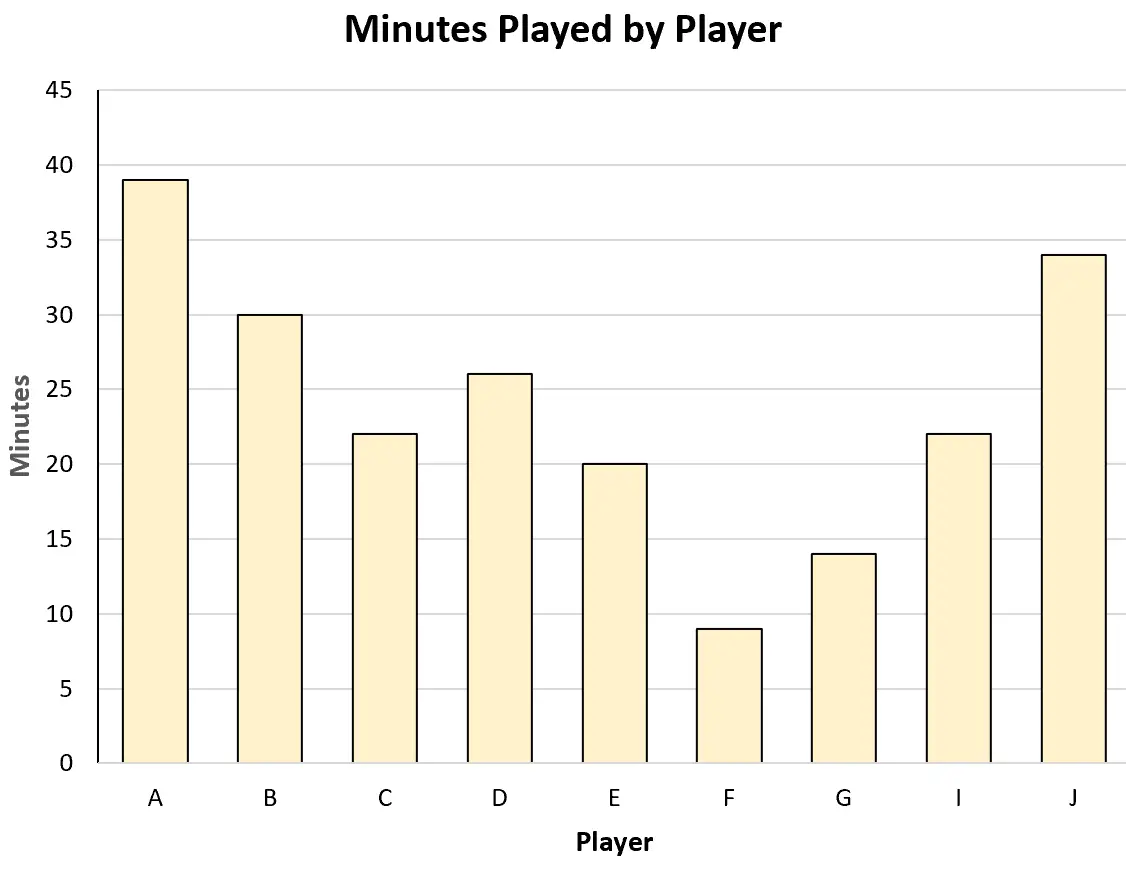
Oder er könnte das folgende Streudiagramm erstellen, um die Beziehung zwischen gespielten Minuten und erzielten Punkten zu veranschaulichen:
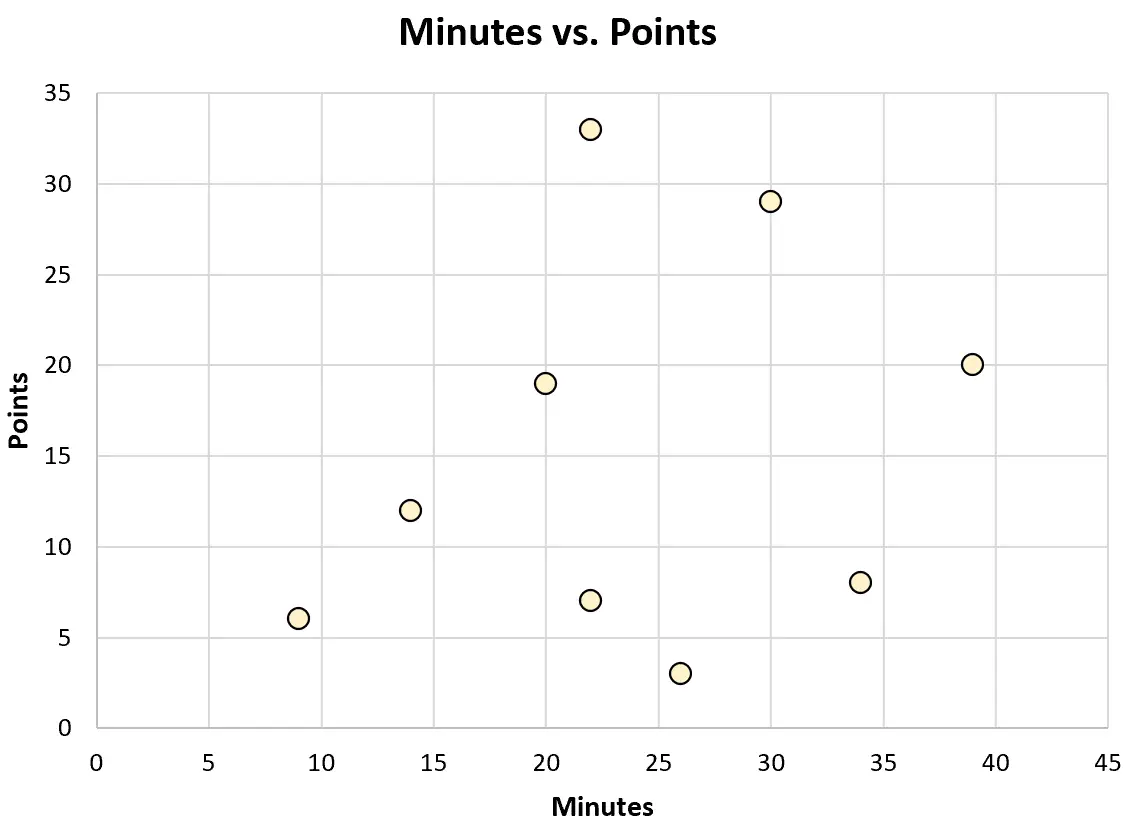
Jeder dieser Diagrammtypen kann ihm helfen, die Daten besser zu verstehen.
Schritt 5: Verwenden Sie Daten, um ein Modell zu erstellen
Sobald die Daten bereinigt sind, kann der Scout schließlich entscheiden, eine Art Vorhersagemodell anzupassen.
Es kann beispielsweise ein einfaches lineares Regressionsmodell anpassen und anhand der gespielten Minuten die Gesamtpunktzahl jedes Spielers vorhersagen.
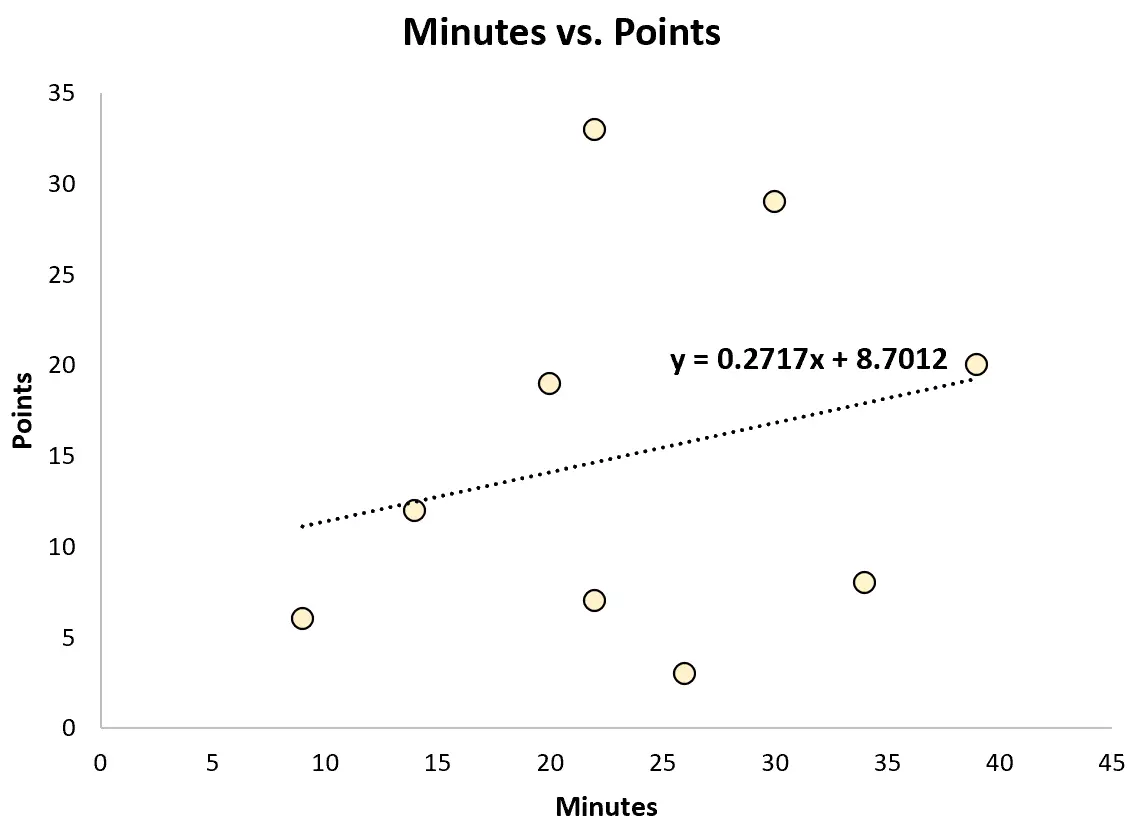
Die angepasste Regressionsgleichung lautet:
Punkte = 8,7012 + 0,2717*(Minuten)
Der Scout könnte diese Gleichung dann verwenden, um die Anzahl der Punkte vorherzusagen, die ein Spieler basierend auf der Anzahl der gespielten Minuten erzielen wird. Beispielsweise sollte ein Sportler, der 30 Minuten spielt , 16,85 Punkte erzielen:
Punkte = 8,7012 + 0,2717*(30) = 16,85
Zusätzliche Ressourcen
Warum sind Statistiken wichtig?
Warum ist die Stichprobengröße in der Statistik wichtig?
Was ist eine Beobachtung in der Statistik?
Was sind tabellarische Daten in der Statistik?
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen