Nicht gruppierte daten
In diesem Artikel erfahren Sie, was nicht gruppierte Daten in der Statistik sind, eine gelöste Übung zu nicht gruppierten Daten und auch, was die Unterschiede zwischen gruppierten Daten und nicht gruppierten Daten sind.
Was sind nicht gruppierte Daten?
In der Statistik handelt es sich bei nicht gepoolten Daten um Daten, die nicht gruppiert, sondern separat untersucht werden. Das heißt, wenn die Daten nicht gruppiert sind, wird jeder Wert im Datensatz einzeln analysiert.
Nicht gruppierte Daten bilden keine Intervalle, gruppierte Daten hingegen schon.
Im Allgemeinen werden Daten gruppiert, wenn die Variable kontinuierlich ist oder wenn viele Werte analysiert werden müssen. Wenn die Daten einer diskreten Variablen folgen und wir nicht über eine sehr große Datenmenge verfügen, besteht daher keine Notwendigkeit, die Daten in Intervalle zu gruppieren.
Beispiel für nicht gruppierte Daten
Nachdem wir die Definition nicht gruppierter Daten kennengelernt haben, lösen wir nun ein Beispiel mit dieser Art von statistischen Daten, um das Konzept besser zu verstehen.
- Die in der Statistik in einer Klasse mit 30 Schülern erzielten Noten lauten wie folgt. Was ist die absolute Häufigkeit jeder Note?



In diesem Fall handelt es sich um eine diskrete Variable, da es nur ganze Zahlen geben kann und daher keine Notwendigkeit besteht, die Daten in Intervalle zu gruppieren.
Zählen Sie also einfach, wie oft jeder Wert erscheint, und schreiben Sie ihn in ein Array:
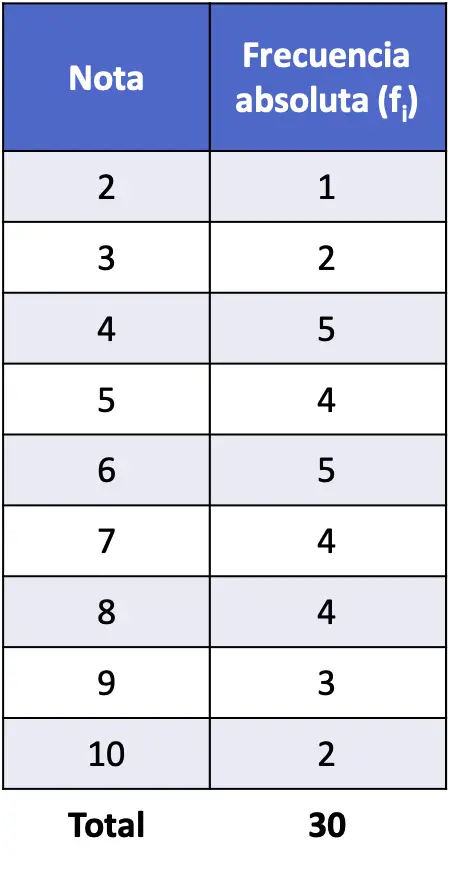
Da die Daten nicht in Intervalle gruppiert wurden, kann jeder Wert separat untersucht werden. So können wir die Anzahl der Schüler ermitteln, die jede Notiz gemacht haben.
Beachten Sie, dass Sie zum Ausfüllen einer Häufigkeitstabelle immer die kumulative absolute Häufigkeit, die relative Häufigkeit, die kumulative relative Häufigkeit usw. berechnen müssen. Wie es geht, können Sie hier sehen:
Nicht gruppierte Daten und gruppierte Daten
In diesem Abschnitt werden wir sehen, was der Unterschied zwischen gruppierten und nicht gruppierten Daten ist. Darüber hinaus werden wir sehen, wann es angebracht ist, die Daten zu gruppieren und wann nicht, da dies logischerweise den Rest der Untersuchung bestimmt.
Der Unterschied zwischen gruppierten und nicht gruppierten Daten besteht in der Gruppierung oder nicht. Wenn die Daten gruppiert sind, bedeutet dies, dass sie in Intervallen erfasst werden. Wenn die Daten hingegen nicht gruppiert sind, bedeutet dies, dass jeder Wert separat untersucht wird.
Im Allgemeinen werden Daten nach Intervallen gruppiert, wenn die Variable kontinuierlich ist. Wenn die Variable jedoch diskret ist, ist es besser, die Daten nicht zu gruppieren. Wenn wir jedoch über große Datenmengen verfügen, können wir die Daten auch in Intervallen gruppieren, um statistische Untersuchungen zu erleichtern.
Statistische Maße nicht gepoolter Daten
Sobald die Häufigkeitstabelle erstellt wurde und die Daten nicht gruppiert sind, werden üblicherweise mehrere statistische Maße berechnet.
Konkret werden in der Regel Maße der zentralen Tendenz, Maße der Streuung und Maße der Position bestimmt, da sie es ermöglichen, eine Stichprobe von Daten zusammenzufassen und darüber hinaus mit anderen Datensätzen zu vergleichen.
Wie all diese statistischen Parameter berechnet werden, können Sie unter den folgenden Links sehen:
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen