Kontinuierliche wahrscheinlichkeitsverteilung
In diesem Artikel wird erläutert, was kontinuierliche Wahrscheinlichkeitsverteilungen sind und wofür sie in der Statistik verwendet werden. So erfahren Sie, was es bedeutet, dass eine Wahrscheinlichkeitsverteilung stetig ist, Beispiele für stetige Verteilungen und welche verschiedenen Arten von stetigen Verteilungen es gibt.
Was ist eine kontinuierliche Wahrscheinlichkeitsverteilung?
Eine kontinuierliche Wahrscheinlichkeitsverteilung ist eine Verteilungsfunktion, deren Verteilungsfunktion stetig ist. Daher definiert eine kontinuierliche Wahrscheinlichkeitsverteilung die Wahrscheinlichkeiten einer kontinuierlichen Zufallsvariablen .
Beispielsweise sind die Normalverteilung und die Student-t-Verteilung kontinuierliche Wahrscheinlichkeitsverteilungen.
Eine der Eigenschaften kontinuierlicher Wahrscheinlichkeitsverteilungen besteht darin, dass sie innerhalb eines Intervalls jeden beliebigen Wert annehmen können. Im Gegensatz zu diskreten Wahrscheinlichkeitsverteilungen können kontinuierliche Wahrscheinlichkeitsverteilungen daher Dezimalwerte annehmen.
Bei kontinuierlichen Verteilungen muss man zur Berechnung einer kumulativen Wahrscheinlichkeit die Fläche unter der Kurve der Verteilung ermitteln. Bei dieser Art von Wahrscheinlichkeitsverteilungen entspricht die kumulative Wahrscheinlichkeitsfunktion also dem Integral der Dichtefunktion .
![\displaystyle P[X\leq x]=\int_{-\infty}^x f(x)dx](https://statorials.org/wp-content/ql-cache/quicklatex.com-4a24c53cda32a192e8dd8773df5b8ff6_l3.png "Rendered by QuickLaTeX.com")
Beispiele für kontinuierliche Wahrscheinlichkeitsverteilungen
Sobald wir die Definition der kontinuierlichen Wahrscheinlichkeitsverteilung kennengelernt haben, werden wir uns mehrere Beispiele dieser Art von Verteilung ansehen, um das Konzept besser zu verstehen.
Beispiele für kontinuierliche Wahrscheinlichkeitsverteilungen:
- Das Gewicht der Studierenden in einem Kurs.
- Die Lebensdauer einer elektrischen Komponente.
- Die Rentabilität von Aktien börsennotierter Unternehmen.
- Die Geschwindigkeit eines Autos.
- Der Preis bestimmter Aktien.
Arten kontinuierlicher Wahrscheinlichkeitsverteilungen
Die Haupttypen kontinuierlicher Wahrscheinlichkeitsverteilungen sind:
- Gleichmäßige und kontinuierliche Verteilung
- Normalverteilung
- Lognormalverteilung
- Chi-Quadrat-Verteilung
- Studentische t-Verteilung
- Snedecor F-Verteilung
- Exponentialverteilung
- Beta-Verteilung
- Gammaverteilung
- Weibull-Verteilung
- Pareto-Verteilung
Jeder Typ einer kontinuierlichen Wahrscheinlichkeitsverteilung wird im Folgenden ausführlich erläutert.
Gleichmäßige und kontinuierliche Verteilung
Die kontinuierliche Gleichverteilung , auch Rechteckverteilung genannt, ist eine Art kontinuierliche Wahrscheinlichkeitsverteilung, bei der alle Werte die gleiche Auftrittswahrscheinlichkeit haben. Mit anderen Worten: Die kontinuierliche Gleichverteilung ist eine Verteilung, bei der die Wahrscheinlichkeit gleichmäßig über ein Intervall verteilt ist.
Die kontinuierliche Gleichverteilung wird verwendet, um kontinuierliche Variablen mit konstanter Wahrscheinlichkeit zu beschreiben. In ähnlicher Weise wird die kontinuierliche Gleichverteilung zur Definition zufälliger Prozesse verwendet, denn wenn alle Ergebnisse die gleiche Wahrscheinlichkeit haben, bedeutet dies, dass das Ergebnis zufällig ist.
Die kontinuierliche Gleichverteilung weist zwei charakteristische Parameter a und b auf, die das Äquiwahrscheinlichkeitsintervall definieren. Somit ist das Symbol für die kontinuierliche Gleichverteilung U(a,b) , wobei a und b die charakteristischen Werte der Verteilung sind.

Wenn beispielsweise das Ergebnis eines Zufallsexperiments einen beliebigen Wert zwischen 5 und 9 annehmen kann und alle möglichen Ergebnisse die gleiche Eintrittswahrscheinlichkeit haben, kann das Experiment mit einer kontinuierlichen Gleichverteilung U(5,9) simuliert werden.
Normalverteilung
Die Normalverteilung ist eine kontinuierliche Wahrscheinlichkeitsverteilung, deren Diagramm glockenförmig und symmetrisch um seinen Mittelwert ist. In der Statistik wird die Normalverteilung zur Modellierung von Phänomenen mit sehr unterschiedlichen Eigenschaften verwendet, weshalb diese Verteilung so wichtig ist.
Tatsächlich gilt die Normalverteilung in der Statistik als die mit Abstand wichtigste Verteilung aller Wahrscheinlichkeitsverteilungen, da sie nicht nur eine große Anzahl realer Phänomene modellieren kann, sondern die Normalverteilung auch zur Approximation anderer Arten von Phänomenen verwendet werden kann Verteilungen. unter bestimmten Bedingungen.
Das Symbol für die Normalverteilung ist der Großbuchstabe N. Um anzuzeigen, dass eine Variable einer Normalverteilung folgt, wird sie mit dem Buchstaben N gekennzeichnet und die Werte ihres arithmetischen Mittels und ihrer Standardabweichung werden in Klammern hinzugefügt.

Die Normalverteilung hat viele verschiedene Namen, einschließlich Gauß-Verteilung , Gauß-Verteilung und Laplace-Gauß-Verteilung .
Lognormalverteilung
Die Lognormalverteilung oder Lognormalverteilung ist eine Wahrscheinlichkeitsverteilung, die eine Zufallsvariable definiert, deren Logarithmus einer Normalverteilung folgt.
Wenn also die Variable X eine Normalverteilung hat, dann hat die Exponentialfunktion e x eine Lognormalverteilung.

Beachten Sie, dass die Lognormalverteilung nur verwendet werden kann, wenn die Werte der Variablen positiv sind, da der Logarithmus eine Funktion ist, die nur ein positives Argument akzeptiert.
Unter den verschiedenen Anwendungen der Lognormalverteilung in der Statistik unterscheiden wir die Verwendung dieser Verteilung zur Analyse von Finanzinvestitionen und zur Durchführung von Zuverlässigkeitsanalysen.
Die Lognormalverteilung wird auch als Tinaut-Verteilung bezeichnet, manchmal auch als Lognormalverteilung oder Log-Normalverteilung geschrieben.
Chi-Quadrat-Verteilung
Die Chi-Quadrat-Verteilung ist eine Wahrscheinlichkeitsverteilung, deren Symbol χ² ist. Genauer gesagt ist die Chi-Quadrat-Verteilung die Summe des Quadrats von k unabhängigen Zufallsvariablen mit einer Normalverteilung.
Somit hat die Chi-Quadrat-Verteilung k Freiheitsgrade. Daher hat eine Chi-Quadrat-Verteilung so viele Freiheitsgrade wie die Summe der Quadrate der normalverteilten Variablen, die sie darstellt.
![\displaystyle X\sim\chi^2_k \ \color{orange}\bm{\longrightarrow}\color{black}\ \begin{array}{l}\text{Distribuci\'on chi-cuadrado}\\[2ex]\text{con k grados de libertad}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-9ea0bf7a87071883ceae5e419bae9e71_l3.png "Rendered by QuickLaTeX.com")
Die Chi-Quadrat-Verteilung wird auch als Pearson-Verteilung bezeichnet.
Die Chi-Quadrat-Verteilung wird häufig bei statistischen Schlussfolgerungen verwendet, beispielsweise beim Testen von Hypothesen und bei Konfidenzintervallen. Wir werden unten sehen, welche Anwendungen diese Art von Wahrscheinlichkeitsverteilung sind.
Studentische t-Verteilung
Die Student-t-Verteilung ist eine in der Statistik weit verbreitete Wahrscheinlichkeitsverteilung. Insbesondere wird die Student-t-Verteilung im Student-t-Test verwendet, um die Differenz zwischen den Mittelwerten zweier Stichproben zu bestimmen und Konfidenzintervalle festzulegen.
Die Student-t-Verteilung wurde 1908 vom Statistiker William Sealy Gosset unter dem Pseudonym „Student“ entwickelt.
Die Student-t-Verteilung wird durch die Anzahl der Freiheitsgrade definiert, die durch Subtrahieren einer Einheit von der Gesamtzahl der Beobachtungen ermittelt wird. Daher lautet die Formel zur Bestimmung der Freiheitsgrade der Student-t-Verteilung ν=n-1 .
![\begin{array}{c}\nu=n-1\\[2ex]X\sim t_\nu\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-1c805dc2d6ca050feb70dad99de53402_l3.png "Rendered by QuickLaTeX.com")
Snedecor F-Verteilung
Die Snedecor-F-Verteilung , auch Fisher-Snedecor-F-Verteilung oder einfach F-Verteilung genannt, ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die bei statistischen Inferenzen, insbesondere bei der Varianzanalyse, verwendet wird.
Eine der Eigenschaften der Snedecor-F-Verteilung besteht darin, dass sie durch den Wert zweier reeller Parameter m und n definiert wird, die ihre Freiheitsgrade angeben. Daher ist das Symbol für die Snedecor-Verteilung F F m,n , wobei m und n die Parameter sind, die die Verteilung definieren.
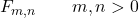
![\left.\begin{array}{c} X\sim \chi_m^2\\[2ex] Y\sim \chi_n^2\end{array}\right\}\color{orange}\bm{\longrightarrow}\color{black}\ F_{m,n}= \cfrac{X/m}{Y/n}](https://statorials.org/wp-content/ql-cache/quicklatex.com-d407869e61ca4357ffbcb40df3bd83ab_l3.png "Rendered by QuickLaTeX.com")
Die Fisher-Snedecor-F-Verteilung verdankt ihren Namen dem englischen Statistiker Ronald Fisher und dem amerikanischen Statistiker George Snedecor.
In der Statistik hat die Fisher-Snedecor-F-Verteilung verschiedene Anwendungen. Beispielsweise wird die Fisher-Snedecor-F-Verteilung verwendet, um verschiedene lineare Regressionsmodelle zu vergleichen, und diese Wahrscheinlichkeitsverteilung wird in der Varianzanalyse (ANOVA) verwendet.
Exponentialverteilung
Die Exponentialverteilung ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die zur Modellierung der Wartezeit für das Auftreten eines Zufallsphänomens verwendet wird.
Genauer gesagt ermöglicht die Exponentialverteilung die Beschreibung der Wartezeit zwischen zwei Phänomenen, die einer Poisson-Verteilung folgt. Daher ist die Exponentialverteilung eng mit der Poisson-Verteilung verwandt.
Die Exponentialverteilung hat einen charakteristischen Parameter, der durch den griechischen Buchstaben λ dargestellt wird und angibt, wie oft das untersuchte Ereignis in einem bestimmten Zeitraum voraussichtlich auftritt.

Ebenso wird die Exponentialverteilung auch zur Modellierung der Zeit bis zum Auftreten eines Ausfalls verwendet. Die Exponentialverteilung hat daher mehrere Anwendungen in der Zuverlässigkeits- und Überlebenstheorie.
Beta-Verteilung
Die Beta-Verteilung ist eine Wahrscheinlichkeitsverteilung, die auf dem Intervall (0,1) definiert und durch zwei positive Parameter parametrisiert ist: α und β. Mit anderen Worten, die Werte der Beta-Verteilung hängen von den Parametern α und β ab.
Daher wird die Betaverteilung verwendet, um kontinuierliche Zufallsvariablen zu definieren, deren Wert zwischen 0 und 1 liegt.
Es gibt mehrere Notationen, die darauf hinweisen, dass eine kontinuierliche Zufallsvariable durch eine Betaverteilung bestimmt wird. Die gebräuchlichsten sind:
![\begin{array}{c}X\sim B(\alpha,\beta)\\[2ex]X\sim Beta(\alpha,\beta)\\[2ex]X\sim \beta_{\alpha,\beta}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-ee1d0d8a1624a017b8ef9ce8a67c694e_l3.png "Rendered by QuickLaTeX.com")
In der Statistik hat die Beta-Verteilung sehr unterschiedliche Anwendungen. Beispielsweise wird die Betaverteilung verwendet, um prozentuale Schwankungen in verschiedenen Stichproben zu untersuchen. In ähnlicher Weise wird im Projektmanagement die Betaverteilung zur Durchführung einer Pert-Analyse verwendet.
Gammaverteilung
Die Gammaverteilung ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die durch zwei charakteristische Parameter, α und λ, definiert wird. Mit anderen Worten: Die Gammaverteilung hängt vom Wert ihrer beiden Parameter ab: α ist der Formparameter und λ der Skalenparameter.
Das Symbol für die Gammaverteilung ist der griechische Großbuchstabe Γ. Wenn also eine Zufallsvariable einer Gammaverteilung folgt, wird sie wie folgt geschrieben:

Die Gammaverteilung kann auch mit dem Formparameter k = α und dem inversen Skalenparameter θ = 1/λ parametrisiert werden. In allen Fällen sind die beiden Parameter, die die Gammaverteilung definieren, positive reelle Zahlen.
Typischerweise wird die Gammaverteilung zur Modellierung rechtsschiefer Datensätze verwendet, sodass auf der linken Seite des Diagramms eine größere Datenkonzentration vorliegt. Beispielsweise wird die Gammaverteilung zur Modellierung der Zuverlässigkeit elektrischer Komponenten verwendet.
Weibull-Verteilung
Die Weibull-Verteilung ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die durch zwei charakteristische Parameter definiert wird: den Formparameter α und den Skalenparameter λ.
In der Statistik wird die Weibull-Verteilung hauptsächlich zur Überlebensanalyse verwendet. Ebenso hat die Weibull-Verteilung viele Anwendungen in verschiedenen Bereichen.

Den Autoren zufolge lässt sich die Weibull-Verteilung auch mit drei Parametern parametrisieren. Dann wird ein dritter Parameter namens Schwellenwert hinzugefügt, der die Abszisse angibt, bei der das Verteilungsdiagramm beginnt.
Die Weibull-Verteilung ist nach dem Schweden Waloddi Weibull benannt, der sie 1951 ausführlich beschrieb. Allerdings wurde die Weibull-Verteilung 1927 von Maurice Fréchet entdeckt und erstmals 1933 von Rosin und Rammler angewendet.
Pareto-Verteilung
Die Pareto-Verteilung ist eine kontinuierliche Wahrscheinlichkeitsverteilung, die in der Statistik zur Modellierung des Pareto-Prinzips verwendet wird. Daher ist die Pareto-Verteilung eine Wahrscheinlichkeitsverteilung, die einige wenige Werte aufweist, deren Eintrittswahrscheinlichkeit viel höher ist als die der übrigen Werte.
Denken Sie daran, dass das Pareto-Gesetz, auch 80-20-Regel genannt, ein statistisches Prinzip ist, das besagt, dass die Ursache eines Phänomens größtenteils auf einen kleinen Teil der Bevölkerung zurückzuführen ist.
Die Pareto-Verteilung hat zwei charakteristische Parameter: den Skalenparameter x m und den Formparameter α.

Ursprünglich wurde die Pareto-Verteilung verwendet, um die Vermögensverteilung innerhalb der Bevölkerung zu beschreiben, da der Großteil davon auf einen kleinen Teil der Bevölkerung zurückzuführen war. Doch derzeit hat die Pareto-Verteilung viele Anwendungen, beispielsweise in der Qualitätskontrolle, in der Wirtschaft, in der Wissenschaft, im sozialen Bereich usw.
Kontinuierliche und diskrete Wahrscheinlichkeitsverteilung
Wahrscheinlichkeitsverteilungen können in kontinuierliche Verteilungen und diskrete Verteilungen eingeteilt werden. Schließlich werden wir sehen, was der Unterschied zwischen diesen beiden Arten von Wahrscheinlichkeitsverteilungen ist.
Der Unterschied zwischen kontinuierlichen Wahrscheinlichkeitsverteilungen und diskreten Wahrscheinlichkeitsverteilungen besteht in der Anzahl der Werte, die sie annehmen können. Kontinuierliche Verteilungen können in einem Intervall unendlich viele Werte annehmen, während diskrete Verteilungen in einem Intervall nur eine abzählbare Anzahl von Werten annehmen können.
Daher besteht im Allgemeinen eine Möglichkeit, kontinuierliche Verteilungen von diskreten Verteilungen zu unterscheiden, darin, welche Art von Zahlen sie annehmen können. Normalerweise kann eine kontinuierliche Verteilung jeden Wert annehmen, einschließlich Dezimalzahlen, während diskrete Verteilungen nur ganze Zahlen annehmen können.
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen