Verwendung von proc surveyselect in sas (mit beispielen)
Sie können PROC SURVEYSELECT verwenden, um eine Zufallsstichprobe aus einem Datensatz in SAS auszuwählen.
Hier sind drei gängige Möglichkeiten, dieses Verfahren in der Praxis anzuwenden:
Beispiel 1: Verwenden Sie PROC SURVEYSELECT, um eine einfache Zufallsstichprobe auszuwählen
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling*/
n =5 /*select a total of 5 observations*/
seed =1; /*set seed to make this example reproducible*/
run ;
In diesem speziellen Beispiel werden 5 zufällige Beobachtungen aus dem Datensatz ausgewählt.
Beispiel 2: Verwenden Sie PROC SURVEYSELECT, um eine geschichtete Zufallsstichprobe auszuwählen
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling*/
n =2 /*select 2 observations from each strata*/
seed =1; /*set seed to make this example reproducible*/
strata grouping_var; /*specify variable to use for stratification*/
run ;
In diesem speziellen Beispiel werden zwei zufällige Beobachtungen aus jeder einzelnen Schicht des Datensatzes ausgewählt.
Die strata- Anweisung gibt die Variable an, die für die Schichtung verwendet werden soll.
Beispiel 3: Verwenden Sie PROC SURVEYSELECT, um eine gepoolte Zufallsstichprobe auszuwählen
proc surveyselect data =my_data
out =my_sample
n =2 /*select 2 clusters*/
seed =1; /*set seed to make this example reproducible*/
clustergrouping_var ; /*specify variable to use for stratification*/
run ;
In diesem speziellen Beispiel werden zwei zufällige Cluster aus dem Datensatz ausgewählt und jede Beobachtung aus jedem Cluster in der Stichprobe einbezogen.
Die Cluster- Anweisung gibt die Variable an, die für das Clustering verwendet werden soll.
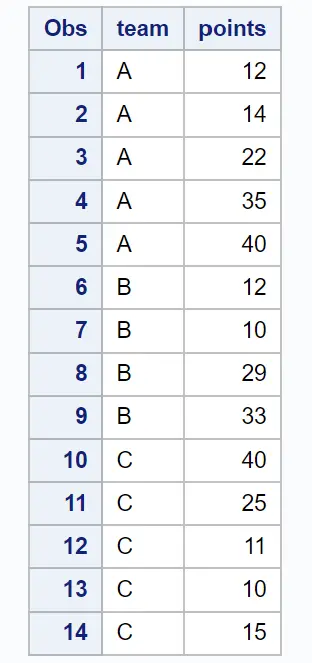
Die folgenden Beispiele zeigen, wie jede Methode in der Praxis mit dem folgenden Datensatz in SAS verwendet wird, der Informationen über Basketballspieler verschiedener Teams enthält:
/*create dataset*/
data my_data;
input team $points;
datalines ;
AT 12
At 14
At 22
At 35
At 40
B 12
B 10
B29
B 33
C40
C25
C 11
C 10
C15
;
run ;
/*view dataset*/
proc print data = my_data;
Beispiel 1: Verwenden Sie PROC SURVEYSELECT, um eine einfache Zufallsstichprobe auszuwählen
Wir können die folgende Syntax verwenden, um eine einfache Zufallsstichprobe von 5 Beobachtungen aus dem Datensatz auszuwählen:
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling*/
n =5 /*select a total of 5 observations*/
seed =1; /*set seed to make this example reproducible*/
run ;
/*view sample*/
proc print data =my_sample;
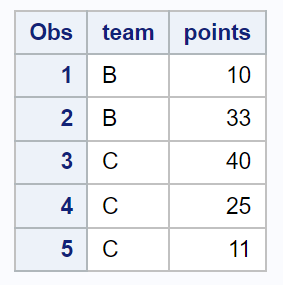
Die resultierende Stichprobe enthält 5 Beobachtungen, die zufällig aus dem Datensatz ausgewählt wurden.
Beispiel 2: Verwenden Sie PROC SURVEYSELECT, um eine geschichtete Zufallsstichprobe auszuwählen
Wir können die folgende Syntax verwenden, um eine geschichtete Zufallsstichprobe durchzuführen, bei der aus jedem Team zwei Beobachtungen zufällig ausgewählt werden, um in die Stichprobe aufgenommen zu werden:
proc surveyselect data =my_data
out =my_sample
method =srs /*use simple random sampling within strata*/
n =2 /*select 2 observations from each strata*/
seed =1; /*set seed to make this example reproducible*/
strata grouping_var; /*specify variable to use for stratification*/
run ;
/*view sample*/
proc print data =my_sample;
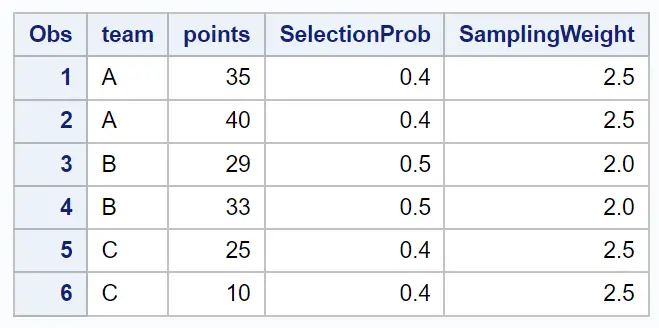
Die resultierende Stichprobe enthält zwei zufällig ausgewählte Beobachtungen von jedem Team.
Verwandte Themen: Cluster-Sampling und geschichtete Sampling: Was ist der Unterschied?
Beispiel 3: Verwenden Sie PROC SURVEYSELECT, um eine gepoolte Zufallsstichprobe auszuwählen
Wir können die folgende Syntax verwenden, um eine Cluster-Zufallsstichprobe durchzuführen, bei der wir Teams als Cluster verwenden, zufällig zwei Cluster auswählen und jede Beobachtung aus diesen Clustern in die Stichprobe aufnehmen:
proc surveyselect data =my_data
out =my_sample
n =2 /*select a total of 2 clusters*/
seed =1; /*set seed to make this example reproducible*/
clustergrouping_var ; /*specify variable to use for clustering*/
run ;
/*view sample*/
proc print data =my_sample;
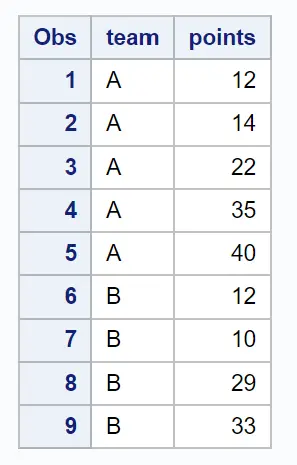
Diese spezielle Stichprobe enthält alle Beobachtungen der Teams A und B, die die beiden zufällig ausgewählten „Cluster“ waren.
Hinweis : Die vollständige PROC SURVEYSELECT- Dokumentation finden Sie hier .
Zusätzliche Ressourcen
In den folgenden Tutorials wird erläutert, wie Sie andere häufige Aufgaben in SAS ausführen:
So berechnen Sie deskriptive Statistiken in SAS
So erstellen Sie Häufigkeitstabellen in SAS
So berechnen Sie Perzentile in SAS
So erstellen Sie PivotTables in SAS
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen