So verwenden sie proc cluster in sas (mit beispiel)
Clustering ist eine Technik des maschinellen Lernens, die versucht, Gruppen von Beobachtungen innerhalb eines Datensatzes zu finden.
Das Ziel besteht darin, Cluster zu finden, bei denen die Beobachtungen innerhalb jedes Clusters einander recht ähnlich sind, während sich die Beobachtungen in verschiedenen Clustern deutlich voneinander unterscheiden.
Der einfachste Weg, Clustering in SAS durchzuführen, ist die Verwendung von PROC CLUSTER .
Das folgende Beispiel zeigt, wie PROC CLUSTER in der Praxis eingesetzt wird.
Beispiel: Verwendung von PROC CLUSTER in SAS
Nehmen wir an, wir haben den folgenden Datensatz mit Informationen zu Punkten, Assists und Rebounds für 20 verschiedene Basketballspieler:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
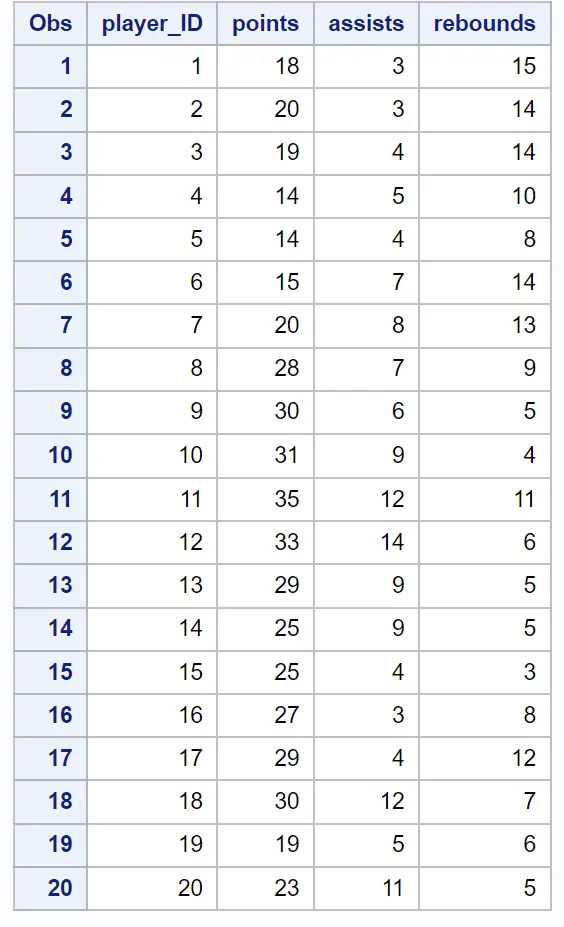
Nehmen wir an, wir möchten eine Gruppierung durchführen, um „Cluster“ von Spielern mit ähnlichen Statistiken zu identifizieren.
Der folgende Code zeigt, wie PROC CLUSTER in SAS zum Durchführen von Clustering verwendet wird:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
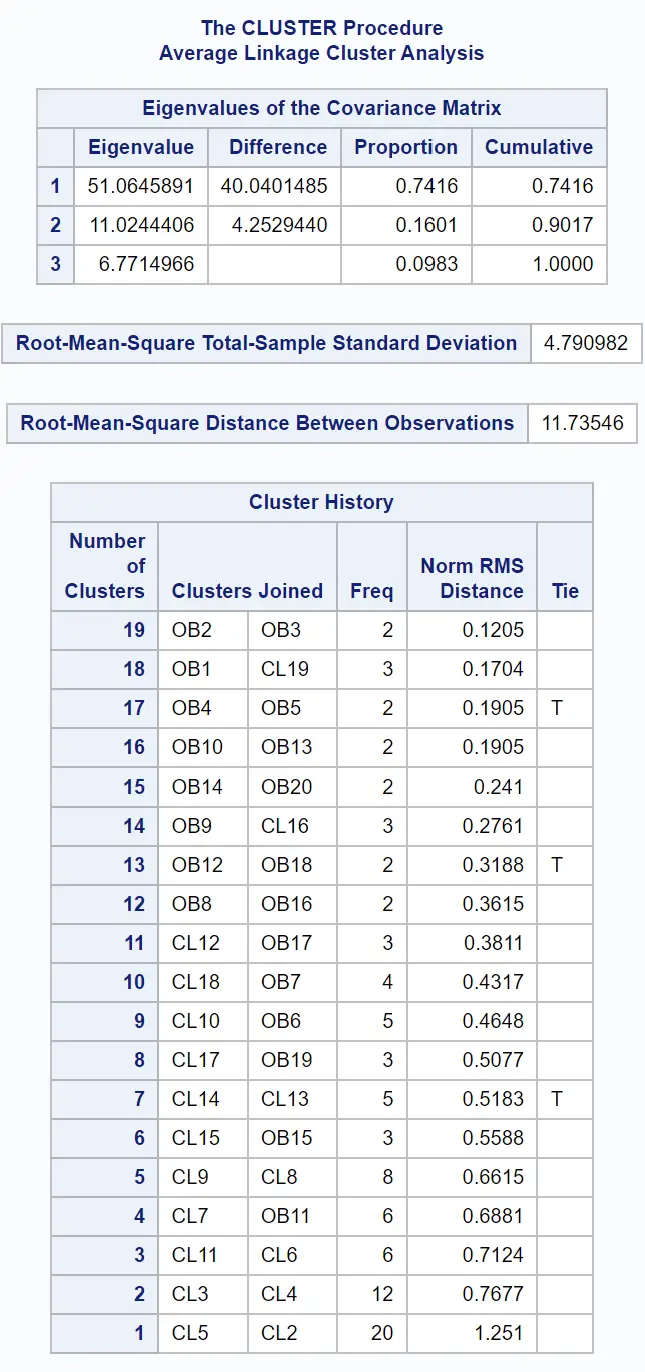
Die ersten Ergebnistabellen geben Aufschluss darüber, wie das Clustering durchgeführt wurde:
Außerdem wird ein Dendrogramm erstellt, damit wir die Ähnlichkeit zwischen Beobachtungen im Datensatz visuell überprüfen können:
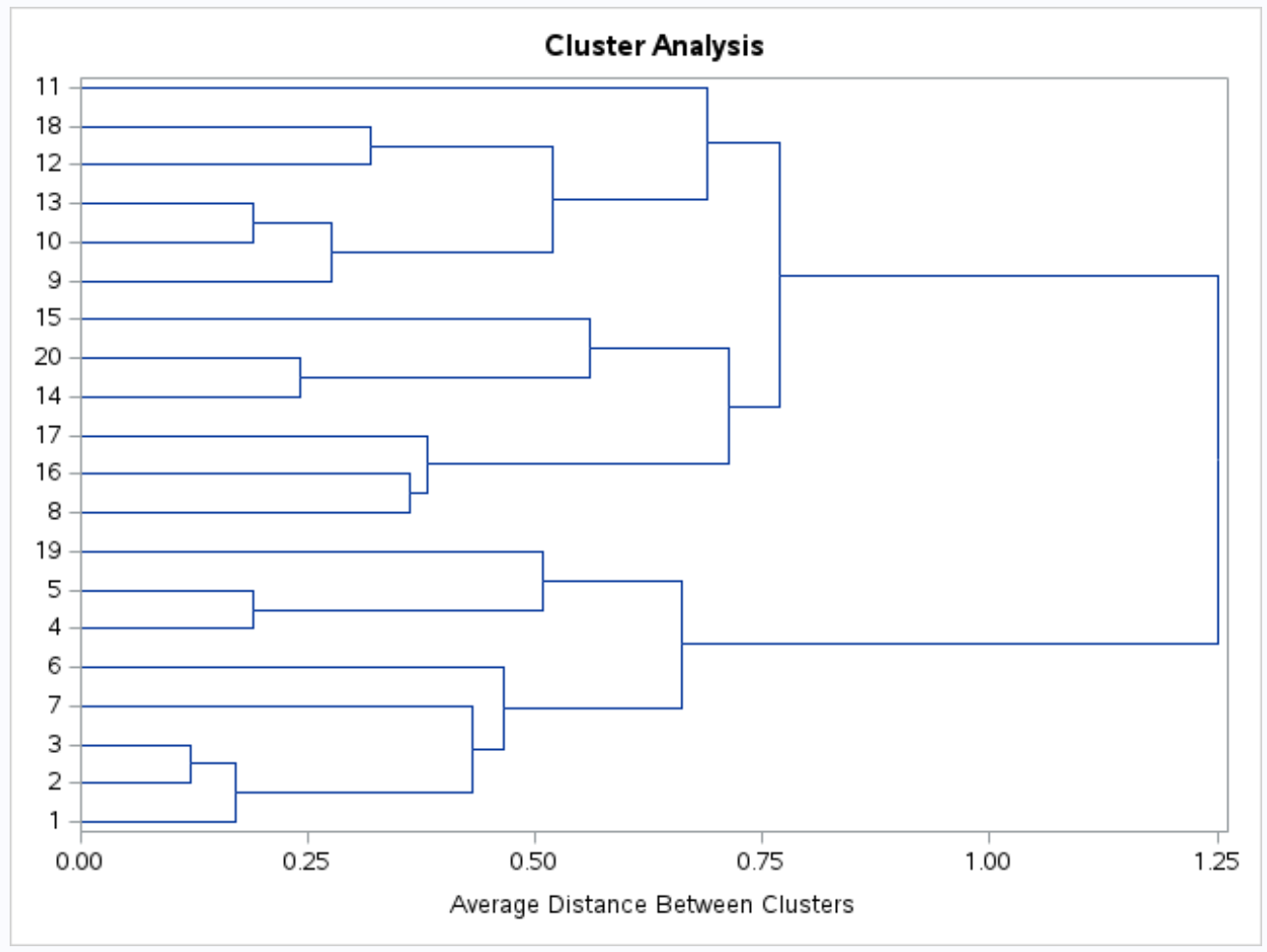
Die y-Achse zeigt einzelne Beobachtungen und die x-Achse zeigt den durchschnittlichen Abstand zwischen Clustern.
Wenn man sich dieses Dendrogramm ansieht, scheint es, dass die Beobachtungen natürlicherweise in drei Gruppen unterteilt werden können:
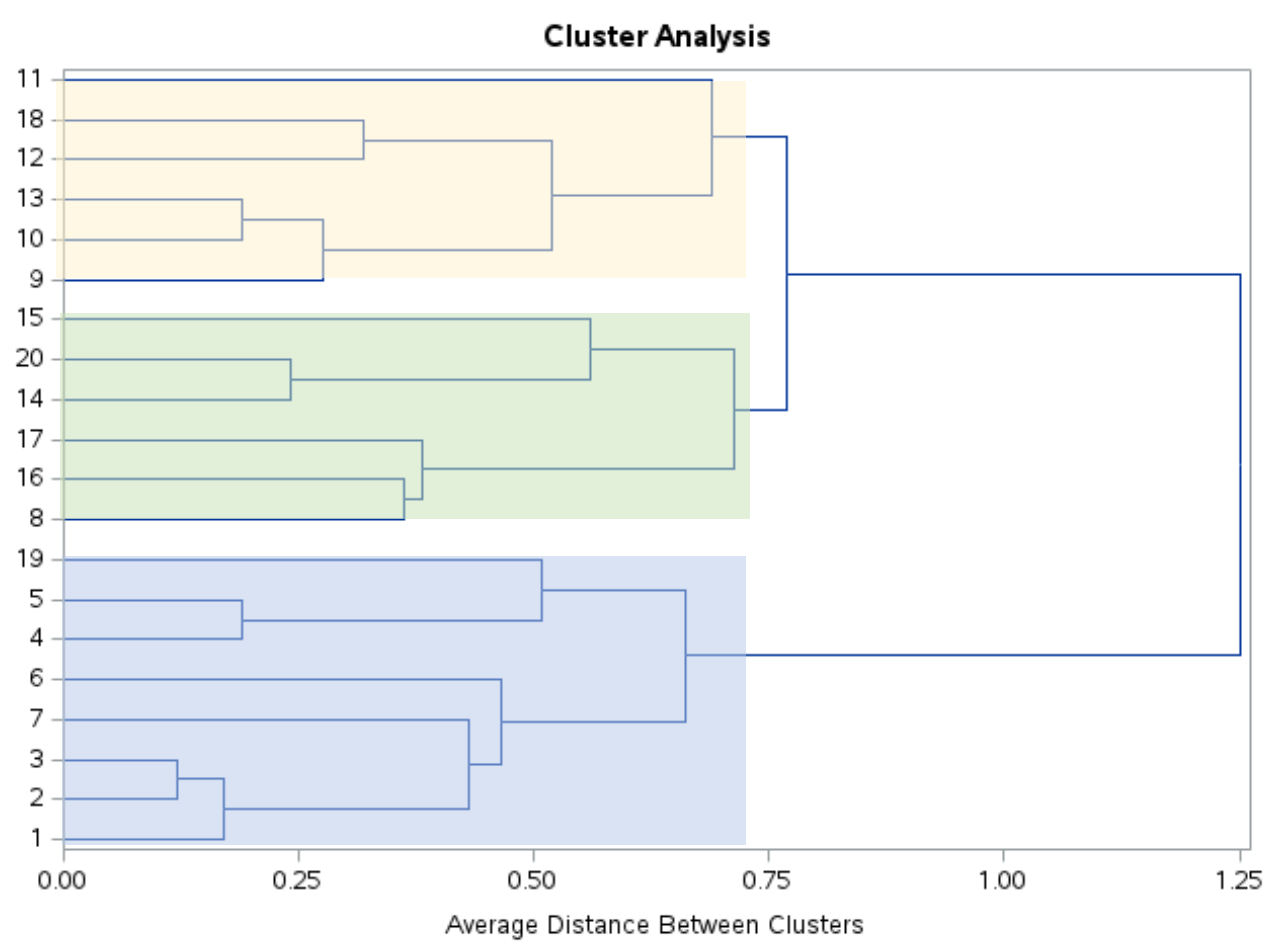
Anschließend können wir die PROC TREE -Anweisung mit ncl=3 verwenden, um SAS anzuweisen, jede Beobachtung im Originaldatensatz einem von drei Clustern zuzuordnen:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
Der resultierende Datensatz zeigt jede der ursprünglichen Beobachtungen zusammen mit dem Cluster, zu dem sie gehören:
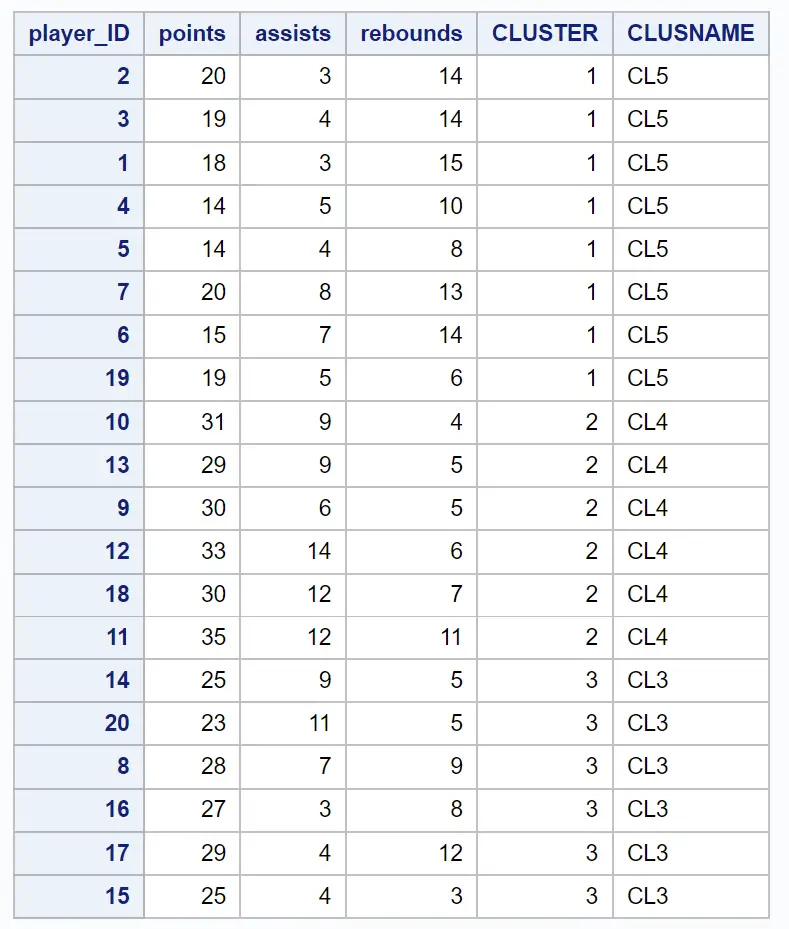
Wir können zum Beispiel sehen: dass Spieler mit den IDs 2, 3, 1, 4, 5, 7, 6 und 19 alle zum Cluster 1 gehören.
Dies zeigt uns, dass diese acht Spieler in Bezug auf Punkte, Assists und Rebounds-Variablen „ähnlich“ sind.
Hinweis : In diesem Beispiel haben wir uns für die Mittelwertbildung als Verknüpfungsmethode für das Clustering entschieden. Eine vollständige Liste anderer Bindungsmethoden, die Sie verwenden können, finden Sie in der SAS-Dokumentation .
Zusätzliche Ressourcen
In den folgenden Tutorials wird erläutert, wie Sie andere häufige Aufgaben in SAS ausführen:
So führen Sie eine Hauptkomponentenanalyse in SAS durch
So führen Sie eine multiple lineare Regression in SAS durch
So führen Sie eine logistische Regression in SAS durch
Über den Autor
Dr. Benjamin Anderson
Hallo, ich bin Benjamin, ein pensionierter Statistikprofessor, der sich zum engagierten Statorials-Lehrer entwickelt hat. Mit umfassender Erfahrung und Fachwissen auf dem Gebiet der Statistik bin ich bestrebt, mein Wissen zu teilen, um Studenten durch Statorials zu befähigen. Mehr wissen